What are Top 10 LLM Security Risks & Why do They Matter? in '24
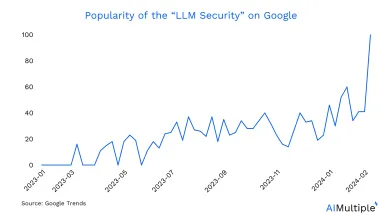
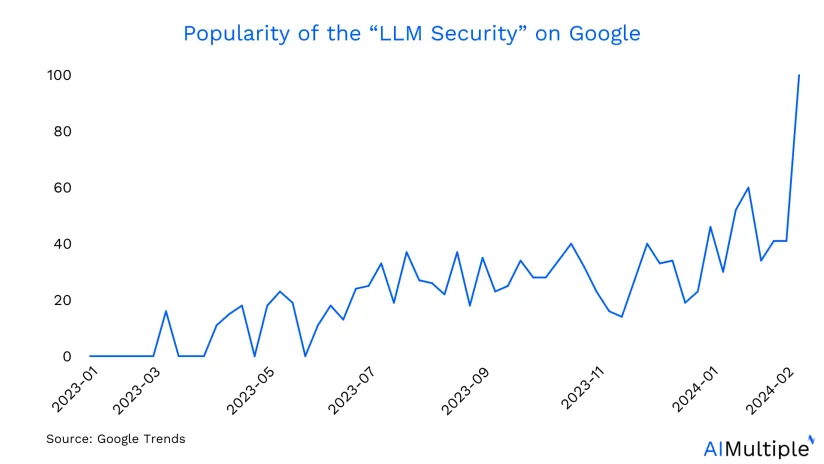
Based on the latest GenAI statistics, 71% of surveyed IT leaders express concerns about potential security vulnerabilities introduced by the implementation of generative AI. This forward-looking perspective underscores a growing interest in implementing security measures for GenAI tools, particularly large language models (LLMs). Since 2023, a gradual shift towards prioritizing LLM security in the IT domain has been evident, as illustrated by the data presented in the Google Trends graph.
This article will explain LLM security inside out, covering OWASP the 10 security risks for LLMs and top tools and technologies to mitigate them.
What is LLM security?
LLM security, or Large Language Model security, refers to the protective measures implemented to address potential risks and challenges associated with advanced natural language processing models like GPT-3. The primary concerns encompass data security, model integrity, infrastructure reliability, and ethical considerations. Language models, due to their vast training datasets, may generate inaccurate or biased content, posing a risk to data security. Unauthorized access, in the form of data breaches, is another crucial issue.
What are top LLM security tools?
LLM security tools refer to a wide range of solutions that may both address ethical behavior and specific vulnerabilities. AI governance tools play a crucial role in ensuring ethical use and compliance with privacy regulations.
To address the top 10 LLM vulnerabilities, specialized LLM security tools are available:
- Open-source frameworks and libraries: These tools are designed to detect potential threats, like data leakage and unauthorized data access which can provide a foundation for securing language models.
- AI security tools: Tailored for LLMs, these tools offer specific services that identify and address system failures, enhancing overall security.
- GenAI security tools: Focusing on both external threats and internal errors within LLM applications, these tools provide comprehensive security measures to safeguard against unique security challenges.
This diverse toolkit aims to fortify LLM security, covering various aspects such as threat detection, system resilience, and protection against both internal and external security issues like proprietary data breaches.
Top 10 LLM security risks
Potential security risks that may threat your LLM applications and effective solutions for a better vulnerability management include:
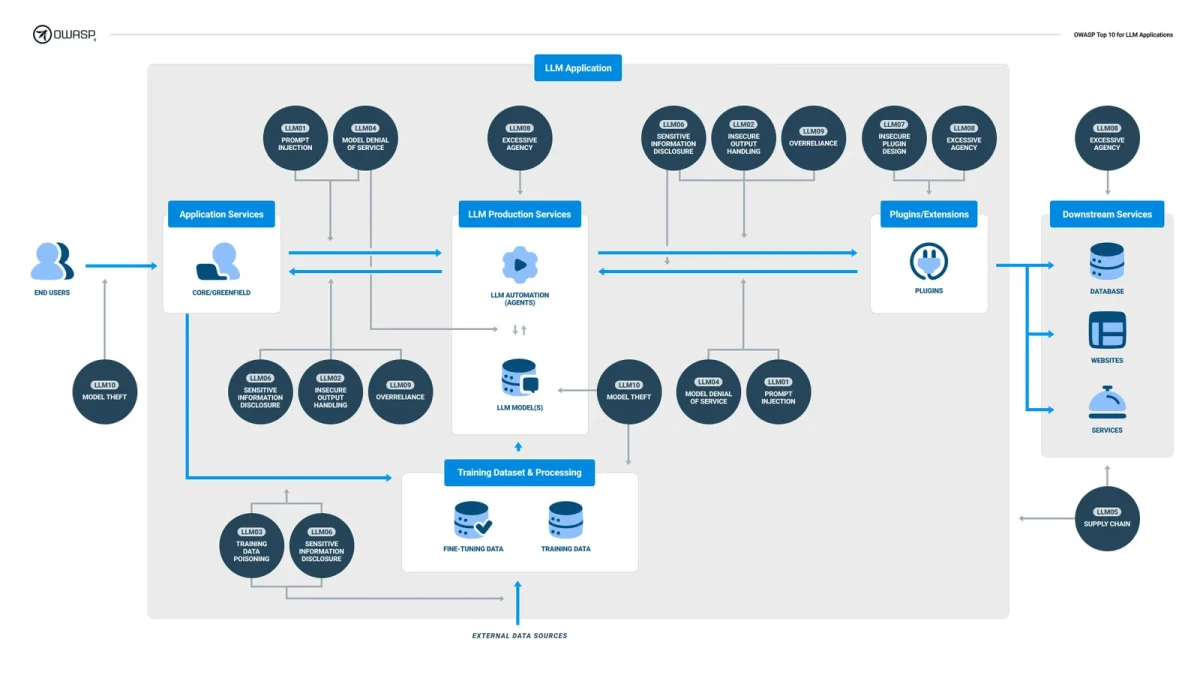
LLM01: Prompt injections
Indirect prompt injection, a frequently discussed LLM vulnerability, occurs when an attacker manipulates a trusted LLM through crafted inputs, directly or indirectly. For instance, an attacker employs an LLM to summarize a webpage containing a malicious prompt injection, leading to the disclosure of sensitive data.
Solutions: To prevent prompt injection vulnerabilities:
- Enforce privilege control on LLM access to the backend system.
- Segregate external content from user prompts.
- Keep humans in the loop for extensible functionality.
Example: Consider an e-commerce platform that uses an LLM for customer support queries. A malicious prompt injected by an attacker manipulates the LLM into revealing sensitive customer information. Implementing privilege controls and segregating content would mitigate such risks.
LLM02: Insecure output handling
Insecure output handling occurs when LLM output is accepted without scrutiny, potentially exposing backend systems. This behavior, akin to providing indirect user access to additional functionality, can lead to severe consequences such as XSS, CSRF, and privilege escalation.
Solutions: To prevent insecure output handling:
- Treat model output as untrusted user content and validate inputs.
- Encode output to mitigate undesired code interpretations.
- Conduct pentesting to identify insecure outputs.
Example: Imagine a customer service chatbot based on LLMs is not properly validated, an attacker inject malicious scripts and the chatbot ends up delivering sensitive information, such as credit card numbers. When a user inputs their credit card information to make a purchase, the chatbot may inadvertently expose this data in the conversation history or through other means, putting the user’s financial information at risk.
LLM03: Training data poisoning
Training data poisoning involves manipulating data or fine-tuning processes to introduce vulnerabilities, backdoors, or biases, compromising an LLM’s security, effectiveness, or ethical behavior. This integrity attack impacts the model’s ability to make correct predictions.
Solutions: To prevent training data poisoning:
- Verify the supply chain of training data and its legitimacy.
- Ensure sufficient sandboxing to prevent unintended data sources.
- Use strict vetting or input filters for specific training data.
Example: An LLM used for for sentiment analysis in social media platforms is manipulated through poisoned training data. Malicious actors inject biased or misleading data into the training set, causing the model to produce skewed or inaccurate sentiment analysis results. This could lead to misinformation or manipulation of public opinion.
LLM04: Model denial of service
Model denial of service occurs when attackers cause resource-heavy operations on LLMs, leading to service degradation or high costs. This vulnerability arises from unusually resource-consuming queries, repetitive inputs, or flooding the LLM with a large volume of variable-length inputs.
Solutions: To prevent Model Denial of Service:
- Implement input validation, sanitization, and enforce limits.
- Cap resource use per request and limit queued actions.
- Continuously monitor LLM resource utilization.
Example: An attacker flooding an LLM with a high volume of requests could overload the system, causing service degradation for legitimate users. This disrupts various applications and services relying on the language model for processing.
LLM05: Supply chain vulnerabilities
Supply chain vulnerabilities in LLMs impact the integrity of training data, ML models, and deployment platforms. These vulnerabilities can lead to biased outcomes, security breaches, and system failures. LLMs face an extended supply chain attack surface through susceptible pre-trained models, poisoned training data, and insecure plugin design.
Solutions: To prevent supply chain vulnerabilities:
- Carefully vet data sources and suppliers.
- Use reputable plug-ins scoped appropriately.
- Conduct monitoring, adversarial testing, and proper patch management.
Example: Consider that LLM rely on a pre-trained model from an unverified source, like a language model library with a vulnerability in its dependency chain. In this case, attackers could exploit the language model’s functionality to gain unauthorized access to sensitive data or execute malicious code on systems where the model is deployed, posing a significant security risk across multiple applications.
LLM06: Sensitive information disclosure
Sensitive information disclosure occurs when LLMs inadvertently reveal confidential data, leading to privacy violations and security breaches. This vulnerability can expose proprietary algorithms, intellectual property, or personal information.
Solutions:To prevent sensitive information disclosure:
- Integrate adequate data input/output sanitization techniques.
- Implement robust input validation and sanitization methods.
- Practice the principle of least privilege during model training.
Example: An LLM unintentionally revealing personal user data during interactions poses a risk. For instance, if the model’s responses are logged without proper anonymization or encryption, sensitive medical records could be exposed to unauthorized parties, leading to privacy breaches and legal consequences.
Explore LLMs in healthcare to understand LLM security risk applications better.
LLM07: Insecure plugin design
Insecure plugin design extends the power of LLMs but introduces vulnerability through poor design. Plugins can be prone to malicious requests, leading to harmful behaviors like sensitive data exfiltration or remote code execution.
Solutions: To prevent insecure plugin design:
- Enforce strict parameterized input for plugins.
- Use appropriate authentication and authorization mechanisms.
- Thoroughly test plugins for security vulnerabilities.
Example: A language model platform allows third-party developers to create and integrate plugins to extend its functionality. However, a poorly designed plugin with security vulnerabilities is uploaded to the platform’s marketplace. Upon installation, the plugin exposes the entire system to potential attacks, such as injection attacks or unauthorized data access, compromising the security of the entire ecosystem.
LLM08: Excessive agency
Excessive agency results from excessive functionality, permissions, or autonomy in LLMs, allowing damaging actions in response to unexpected outputs. This vulnerability impacts confidentiality, integrity, and availability. If an LLM has excessive autonomy, it may perform damaging actions in response to unexpected inputs.
Solutions: To avoid excessive agency:
- Limit tools, functions, and permissions to the minimum necessary.
- Tightly scope functions, plugins, and APIs to avoid over-functionality.
- Require human approval for major and sensitive actions.
Example: A language model with excessive autonomy is deployed in a financial trading system. The model, designed to make trading decisions based on market data, exhibits unexpected behavior and begins executing high-risk trades without human oversight. This excessive agency can lead to significant financial losses or market instability if the model’s decisions are flawed or manipulated.
LLM09: Overreliance
Overreliance occurs when systems or individuals depend on LLMs without sufficient oversight, leading to misinformation spread or incorporation of insecure code. This vulnerability arises from blind trust in LLM outputs.
Solutions: To prevent overreliance:
- Monitor and cross-check LLM outputs with trusted external sources.
- Fine-tune LLM models for improved output quality.
- Break down complex tasks to reduce chances of model malfunctions.
Example: A law enforcement agency relies heavily on a language model for automated surveillance and threat detection. However, due to limitations in the model’s training data or biases in its algorithms, the system consistently fails to accurately identify potential threats, leading to false positives or missed alerts. Overreliance on the model without human oversight could result in serious consequences, such as wrongful arrests or security breaches.
LLM10: Model Theft
Model Theft involves unauthorized access, copying, or exfiltration of proprietary LLM models, leading to economic loss, reputational damage, and unauthorized access to sensitive data.
Solutions: To prevent model theft:
- Implement strong access controls and exercise caution around model repositories.
- Restrict LLM’s access to network resources and internal services.
- Monitor and audit access logs to catch suspicious activity.
Example: A competitor infiltrates a company’s servers and steals their proprietary language model trained for natural language processing tasks. The stolen model is then repurposed or reverse-engineered for unauthorized use, giving the competitor an unfair advantage in developing competing products or services without investing in the research and development efforts required to train such a model from scratch.
For more check out:
How to use LLM safely?
Users can enhance the safe and responsible utilization of Large Language Models in various applications, including:
1. Understand model capabilities and limitations: Familiarize yourself with the capabilities and limitations of the specific LLM you are using. This includes understanding its strengths, potential biases, and areas where it might generate inaccurate or inappropriate content.
2. Preprocess input data: Carefully preprocess input data to ensure it aligns with the intended use of the model. Clean and structure data to minimize the risk of generating unintended or biased outputs.
3. Implement ethical guidelines: Incorporate ethical guidelines into the use of LLMs. Be aware of potential biases in the training data and actively work to avoid generating content that could be considered harmful, discriminatory, or unethical.
4. Regularly update and monitor models: Keep LLMs up-to-date with the latest advancements and updates. Regularly monitor model performance and adjust parameters as needed to maintain optimal results.
5. Use reinforcement learning from human feedback (RLHF): Implement RLHF techniques to align LLMs with human values and correct undesirable behaviors. This helps improve the model’s output over time.
6. Secure data handling: Prioritize data security by employing secure data handling practices. Protect sensitive information from potential data breaches and unauthorized access.
7. Establish access controls: Implement access controls to restrict who can interact with and modify LLMs. This helps prevent misuse and ensures that only authorized users can leverage the model.
8. Incorporate model validation: Include model validation processes to verify the authenticity of LLM outputs. This adds an extra layer of security to ensure the reliability of generated content.
9. Stay informed about model governance: Stay informed about evolving best practices and guidelines related to model governance. Understand and adhere to regulatory requirements and industry standards.
10. Provide user education: Educate users about the proper and ethical use of LLMs. Encourage responsible usage and make users aware of the potential impact of their interactions with the model.
What is OWASP Top Ten?
OWASP (Open Web Application Security Project) is a nonprofit organization dedicated to improving the security of software. It provides freely available security-related resources, including tools and guidelines, to help organizations develop, deploy, and maintain secure software applications.
One of the key contributions from OWASP is the OWASP Top Ten, which is a regularly updated list of the most critical web application security risks. These ten security challenges are revised for LLM security.
Further reading
Explore more on large language models and how to develop one by checking out:
- LLMOPs vs MLOPs: Discover the Best Choice for You
- Large Multimodal Models (LMMs) vs Large Language Models (LLMs)
- 12 Retrieval Augmented Generation (RAG) Tools / Software
- LLM Data Guide & 6 Methods of Collection
External sources

Next to Read
Network Security Policy Management in 2024
Guide to RLHF LLMs in 2024: Benefits & Top Vendors
Vector Database & LLMs: Intersection and Importance in '24
Related research

Comparing 10+ LLMOps Tools: A Comprehensive Vendor Benchmark

Comments
Your email address will not be published. All fields are required.