

Chevrolet of Watsonville, a car dealership, introduced a ChatGPT-based chatbot on their website. However, the chatbot falsely advertised a car for $1, potentially leading to legal consequences and resulting in a substantial bill for Chevrolet. Incidents like these highlight the importance of implementing security measures to LLM applications. 1
Therefore, we provide a detailed benchmark for you to choose the best LLM security tool that can deliver a comprehensive protection for your large language model applications.
Comparing top LLM security tools
Before comparing LLM security tools, we analyzed them under three categories:
- Open-source frameworks and libraries that can detect potential threats
- AI security tools that deliver LLM-specific services pinpointing system failures
- GenAI security tools that focus on external threats and internal errors in LLM apps.
As we concentrate on LLM security tools, we excluded LLMOps tools and other large language models (LLMs) that cannot identify critical vulnerabilities or any security breach. We also did not mention tools that provide AI governance services that check for ethical behavior and data privacy regulations.
| Tools | Number of employees | Tool category |
|---|---|---|
| Holistic AI | 84 | AI governance |
| Fiddler | 76 | AI governance |
| Credo AI | 43 | AI governance |
| Fairly | 11 | AI governance |
| Synack | 264 | AI security |
| WhyLabs LLM Security | 57 | AI security |
| CalypsoAI Moderator | 53 | AI security |
| Adversa AI | 3 | AI security |
| LLM Attack Chains by Praetorian | 146 | GenAI security |
| LLM Guard by Protect AI | 42 | GenAI security |
| Lasso Security | 23 | GenAI security |
| Lakera Guard | 13 | GenAI security |
| Prompt Security | 13 | GenAI security |
The table shows LLM security solutions listed on their category and number of employees of the vendors.
AI governance tools
AI governance tools evaluate AI models for efficacy, bias, robustness, privacy, and explainability, providing actionable strategies for risk mitigation and standardised reporting. AI governance tools can help with LLM security assessments, ensuring that LLMs are secure, trustworthy, and compliant with relevant regulations, thereby enhancing the overall safety and reliability. Some of these tools include:

Holistic AI
Best for AI audit and risk mitigationHolistic AI is an AI governance tool that helps ensure compliance, mitigate risks, and enhance the security of AI systems, including large language models (LLMs). It provides system assessments for efficacy, bias, privacy, and explainability, and continuous monitoring of global AI regulations. Some of its relevant features include:
- Data security to automatically censor sensitive data from generative AI prompts.
- Bias and toxicity shielding to protect against bias, toxicity, and hallucinations.
- Vulnerability detection to identify and mitigate vulnerabilities.
- Malicious prompt detection to detect and respond to malicious prompts to safeguard LLMs.

Credo AI
Best for LLMOps integrationCredo AI is an AI governance platform that helps companies adopt, scale, and govern AI. Credo AI offers GenAI Guardrails, which provide governance features to support the safe adoption of generative AI technologies. Some of the features are:
- Technical integrations with LLMOps tools to configure I/O filters and privacy-preserving infrastructure from a centralized command center.
- GenAI-specific policy packs that includes predefined processes and technical controls to mitigate risks in text, code, and image generation.

Fairly AI
Best for monitoringFairly AI is a focused AI governance, risk management and compliance tool to help organizations manage AI projects securely and effectively from the start. Fairly AI can be useful to detect and react on LLM security risks by features like:
- Continuous monitoring and testing to identify and mitigate risks in real-time.
- Collaboration between risk and compliance teams with data science and cybersecurity teams to ensure models are secure.
- Dynamic reporting to provide continuous visibility and documentation of compliance status to manage and audit LLM security measures.

Fiddler
Best for AI observabilityFiddler is an enterprise AI visibility tool that enhances AI observability, security, and governance. Fiddler helps organizations ensure LLMs are secure, compliant, and high-performing throughout their lifecycle. Its key products and capabilities include:
- LLM observability to monitors performance, detect hallucinations and toxicity, and protect PII.
- Fiddler auditor to evaluate LLMs for robustness, correctness, and safety, and supports prompt injection attack assessments.
- Model monitoring to identify model drift and set alerts for potential issues.
- Responsible AI to mitigate bias and provide actionable insights for improving specific KPIs.
AI security tools
AI security tools provide security measures for artificial intelligence applications by employing advanced algorithms and threat detection mechanisms. Some of these tools can be deployed for LLMs to ensure the integrity of these models.

Synack
Best for crowdsourced security testingSynack is a cybersecurity company that focuses on providing crowdsourced security testing services. Synack platform introduces a set of capabilities to identify AI vulnerabilities and reduce other risks involved in LLM applications. Synack is suitable for various AI implementations, including chatbots, customer guidance, and internal tools. Some critical features it offers include:
- Continuous security by identifying insecure code before release, ensuring proactive risk management during code development.
- Vulnerability checks including prompt injection, insecure output handling, model theft, and excessive agency, addressing concerns such as biased outputs.
- Testing results by delivering real-time reports through Synack platform, showcasing testing methodologies and any exploitable vulnerabilities.

WhyLabs
Best for LLMOps integrationWhyLabs LLM Security offers a comprehensive solution to ensure the safety and reliability of LLM deployments, particularly in production environments. It combines observability tools and safeguarding mechanisms, providing protection against various security threats and vulnerabilities, such as malicious prompts. Here are some of the key features WhyLabs’ platform offers:
- Data leakage protection by evaluating prompts and blocking responses containing personally identifiable information (PII) to identify targeted attacks that can leak confidential data.
- Prompt injection monitoring of malicious prompts that can confuse the system into providing harmful outputs.
- Misinformation prevention by identifying and managing LLM generated content that might include misinformation or inappropriate answers due to “hallucinations.”
- OWASP top 10 for LLM applications which are best practices to identify and mitigate risks associated with LLMs.
CalypsoAI Moderator
CalypsoAI Moderator can secure LLM applications and ensure that organizational data remains within its ecosystem, as it neither processes nor stores the data. The tool is compatible with various platforms powered by LLM technology, including popular models like ChatGPT. Calypso AI Moderator features help with
- Data loss prevention by screening for sensitive data, such as code and intellectual property and preventing unauthorized sharing of proprietary information.
- Full auditability by offering a detailed record of all interactions, including prompt content, sender details, and timestamps.
- Malicious code detection by identifying and blocking malware, safeguarding the organization’s ecosystem from potential infiltrations through LLM responses.
- Automated analysis by automatically generating comments and insights on decompiled code, facilitating a quicker understanding of complex binary structures.
Adversa AI
Adversa AI specializes in cyber threats, privacy concerns, and safety incidents in AI systems. The focus is on understanding potential vulnerabilities that cybercriminals may exploit in AI applications based on the information about the client’s AI models and data. Adversa AI conducts:
- Resilience testing by simulating scenario-based attack simulations to assess the AI system’s ability to adapt and respond, enhancing incident response and security measures.
- Stress testing by evaluating the AI application’s performance under extreme conditions, optimizing scalability, responsiveness, and stability for real-world usage.
- Attack identification by analyze vulnerabilities in facial detection systems to counter adversarial attacks, injection attacks, and evolving threats, ensuring privacy and accuracy safeguards.
GenAI security tools
GenAI-specific tools safeguards the integrity and reliability of language-based AI solutions. These tools can be cybersecurity tools that tailor their services for LLMs or platforms and toolkits specifically developed for securing language generation applications.
LLM attack Chains by Praetorian
Praetorian is a cybersecurity company that specializes in providing advanced security solutions and services. Praetorian can enhance company security posture by offering a range of services, including vulnerability assessments, penetration testing, and security consulting. Praetorian employs adversarial attacks to challenge LLM models. Praetorian’s platform allows users to:
- Use crafted prompts to assess vulnerabilities in Language Models (LLMs), exposing potential biases or security flaws. Injecting prompts allows for thorough testing, revealing the model’s limitations and guiding improvements in robustness.
- Employ side-channel attack detection to fortify tools against potential vulnerabilities. By identifying and mitigating side-channel risks, organizations enhance the security of their systems, safeguarding sensitive information from potential covert channels and unauthorized access.
- Counter data poisoning to maintain the integrity of LLM training datasets. Proactively identifying and preventing data poisoning ensures the reliability and accuracy of models, guarding against malicious manipulation of input data.
- Prevent unauthorized extraction of training data to protect proprietary information.Preventing illicit access to training data enhances the confidentiality and security of sensitive information used in model development.
- Detect and eliminate backdoors to bolster security within the Praetorian platform. Identifying and closing potential backdoors enhances the trustworthiness and reliability of models, ensuring they operate without compromise or unauthorized access.
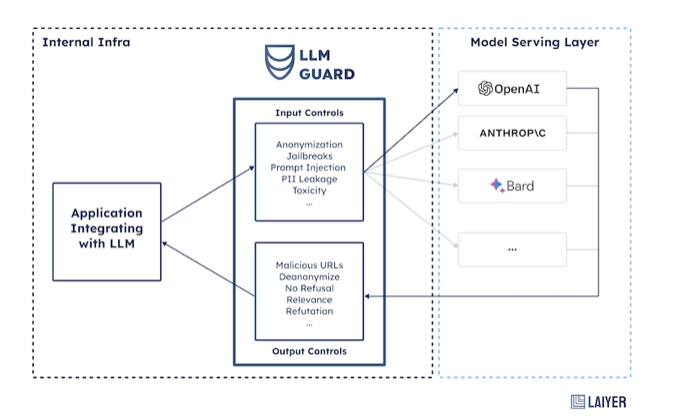
LLMGuard
LLM Guard, developed by Laiyer AI, is a comprehensive and open-source toolkit crafted to enhance the security of Large Language Models (LLMs) through bug fixing, documentation improvement, or spreading awareness. The toolkit allows to
- Detect and sanitize harmful language in LLM interactions, ensuring content remains appropriate and safe.
- Prevent data leakage of sensitive information during LLM interactions, a crucial aspect of maintaining data privacy and security.
- Resist against prompt injection attacks, ensuring the integrity of LLM interactions.
Lakera
Lakera Guard is a developer-centric AI security tool crafted to safeguard Large Language Models (LLMs) applications within enterprises. The tool can integrate with existing applications and workflows through its API, remaining model-agnostic, enabling organizations to secure their LLM applications. Noteworthy features include:
- Prompt Injection protection for both direct and indirect attacks, preventing unintended downstream actions.
- Leakage of sensitive information, such as personally identifiable information (PII) or confidential corporate data.
- Detection of hallucinations by identifying outputs from models that deviate from the input context or expected behavior.
LLM Guardian by Lasso Security
Lasso Security’s LLM Guardian integrates assessment, threat modeling, and education to protect LLM applications. Some of the key features include:
- Security assessments to identify potential vulnerabilities and security risks, providing organizations with insights into their security posture and potential challenges in deploying LLMs.
- Threat modeling, allowing organizations to anticipate and prepare for potential cyber threats targeting their LLM applications.
- Specialized training programs to enhance teams’ cybersecurity knowledge and skills when working with LLMs.
Open-source coding frameworks and libraries
Open-source coding platforms and libraries empower developers to implement and enhance security measures in AI and Generative AI applications. Some of them are specifically developed for LLM security, while some others can be deployed to any AI model.
| Open-Source Coding Frameworks | GitHub Scores | Descriptions |
|---|---|---|
| Guardrails AI | 2,900 | Python package for specifying structure and type, and validating and correcting LLMs |
| Garak | 622 | LLM vulnerability scanner |
| Rebuff | 382 | LLM prompt injection detector |
| G-3PO | 270 | LLM code analyser and annotator |
| Vigil LLM | 204 | LLM prompt injection detector |
| LLMFuzzer | 129 | Fuzzing framework for integration applications via LLM APIs. |
| EscalateGPT | 75 | Escalation detector |
| BurpGPT | 68 | LLM vulnerability scanner |
The table shows open-source LLM security coding frameworks and libraries according to their Github rates.
Guardrails AI
Guardrails AI is an open-source library for AI applications security. The tool consists of two essential components:
- Rail, defining specifications using the Reliable AI Markup Language (RAIL)
- Guard, a lightweight wrapper for structuring, validating, and correcting LLM outputs.
Guardrails AI helps establishing and maintaining assurance standards in LLMs by
- Developing a framework that can facilitate the creation of validators, ensuring adaptability to diverse scenarios, and accommodating specific validation needs.
- Implementing a simplified workflow for prompts, verifications, and re-prompts to optimize the process for seamless interaction with Language Models (LLMs) and enhancing overall efficiency.
- Establishing a centralized repository housing frequently employed validators to promote accessibility, collaboration, and standardized validation practices across various applications and use cases.
Garak
Garak is a thorough vulnerability scanner designed for Large Language Models (LLMs), aiming to identify security vulnerabilities in technologies, systems, applications, and services utilizing language models. Garak’s features are listed as:
- Automated scanning to conduct a variety of probes on a model, manage tasks like detector selection and rate limiting and generate detailed reports without manual intervention, analyzing model performance and security with minimal human involvement.
- Connectivity with various LLMs, including OpenAI, Hugging Face, Cohere, Replicate, and custom Python integrations, increasing flexible for diverse LLM security needs.
- Self-adapting capability whenever an LLM failure is identified by logging and training its auto red-team feature.
- Diverse failure mode exploration throıgh plugins, probes, and challenging prompts to systematically explore and report each failing prompt and response, offering a comprehensive log for in-depth analysis.
Rebuff AI
Rebuff is a prompt injection detector designed to safeguard AI applications from prompt injection (PI) attacks, employing a multi-layered defense mechanism. Rebuff can enhance the security of Large Language Model (LLM) applications by
- Employing four layers of defense to comprehensively protect against PI attacks.
- Utilizing LLM-based detection that can analyze incoming prompts to identify potential attacks, enabling nuanced and context-aware threat detection.
- Storing embeddings of previous attacks in a vector database, recognizing and preventing similar attacks in the future.
- Integrating canary tokens into prompts to detect leakages. The framework stores prompt embeddings in the vector database, fortifying defense against future attacks.
Explore more on Vector database and LLMs.
G3PO
The G3PO script serves as a protocol droid for Ghidra, aiding in the analysis and annotation of decompiled code. This script functions as a security tool in reverse engineering and binary code analysis by utilizes large language models (LLMs) like GPT-3.5, GPT-4, or Claude v1.2. It providers users with
- Vulnerability identification to identify potential security vulnerabilities by leveraging LLM, offering insights based on patterns and training data.
- Automated analysis to automatically generate comments and insights on decompiled code, facilitating a quicker understanding of complex binary structures.
- Code annotation and documentation to suggest meaningful names for functions and variables, enhancing code readability and understanding, particularly crucial in security analysis.
Vigil
Vigil is a Python library and REST API specifically designed for assessing prompts and responses in Large Language Models (LLMs). Its primary role is to identify prompt injections, jailbreaks, and potential risks associated with LLM interactions. Vigil can deliver:
- Detection methods for prompt analysis, including vector database/text similarity, YARA/heuristics, transformer model analysis, prompt-response similarity, and Canary Tokens.
- Custom detections using YARA signatures.
LLMFuzzer
LLMFuzzer is an open-source fuzzing framework specifically crafted to identify vulnerabilities in Large Language Models (LLMs), focusing on their integration into applications through LLM APIs. This tool can be helpful for security enthusiasts, penetration testers, or cybersecurity researchers. Its key features include
- LLM API integration testing to assess LLM integrations in various applications, ensuring comprehensive testing.
- Fuzzing strategies to uncover vulnerabilities, enhancing its effectiveness.
EscalateGPT
EscalateGPT is an AI-powered Python tool that identifies privilege escalation opportunities within Amazon Web Services (AWS) Identity and Access Management (IAM) configurations. It analyzes IAM misconfigurations and provides potential mitigation strategies by using different OpenAI’s models. Some features include:
- IAM policy retrieval and analysis to identify potential privilege escalation opportunities and suggests relevant mitigations.
- Detailed results in JSON format to exploit and recommend strategies that can address vulnerabilities.
EscalateGPT’s performance may vary based on the model it utilizes.For instance, GPT4 demonstrated the ability to identify more complex privilege escalation scenarios compared to GPT3.5-turbo, particularly in real-world AWS environments.
BurpGPT
BurpGPT is a Burp Suite extension designed to enhance web security testing by incorporating OpenAI’s Large Language Models (LLMs). It offers advanced vulnerability scanning and traffic-based analysis capabilities, making it suitable for both novice and experienced security testers. Some of its key features include:
- Passive scan check of HTTP data submitted to an OpenAI-controlled GPT model for analysis, allowing detection of vulnerabilities and issues that traditional scanners might overlook in scanned applications.
- Granular control to choose from multiple OpenAI models and control the number of GPT tokens used in the analysis.
- Integration with Burp suite, leveraging all native features required for analysis, such as displaying results within the Burp UI.
- Troubleshooting functionality via the native Burp Event Log, assisting users in resolving communication issues with the OpenAI API.
FAQ
What is LLM security and why does it matter?
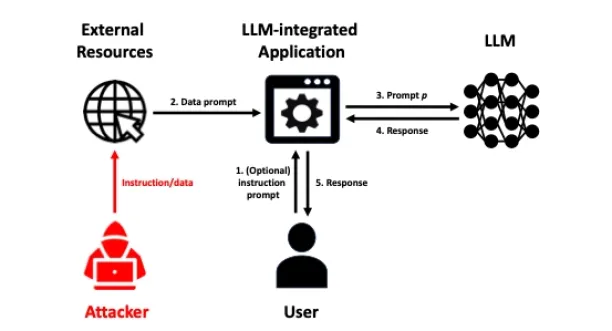
LLM security refers to the security measures and considerations applied to Large Language Models (LLMs), which are advanced natural language processing models, such as GPT-3. LLM security involves addressing potential security risks and challenges associated with these models, including issues like:
1. Data Security: Language models may generate inaccurate or biased content due to their training on vast datasets. Another data security issue is the data breaches where unauthorized users gain access to the sensitive information.
Solution: Use Reinforcement Learning from Human Feedback (RLHF) to align models with human values and minimize undesirable behaviors.
2. Model Security: Protect the model against tampering and ensure the integrity of its parameters and outputs.
Measures: Implement security to prevent unauthorized changes, maintaining trust in the model’s architecture. Use validation processes and checksums to verify output authenticity.
3. Infrastructure Security: Ensure the reliability of language models by securing the hosting systems.
Actions: Implement strict measures for server and network protection, including firewalls, intrusion detection systems, and encryption mechanisms, to guard against threats and unauthorized access.
4. Ethical Considerations: Prevent the generation of harmful or biased content and ensure responsible model deployment.
Approach: Integrate ethical considerations into security practices to balance model capabilities with the mitigation of risks. For this, applyAI governance toolsand methods.
LLM security concerns may lead to:
– Loss of Trust: Security incidents can erode trust, impacting user confidence and stakeholder relationships.
– Legal Repercussions: Breaches may lead to legal consequences, especially concerning regulated data derived from reverse engineering LLM models.
– Damage to Reputation: Entities using LLMs may face reputational harm, affecting their standing in the public and industry.
On the other hand, compromise security can ensure and improve:
– Reliabile and consistent LLM performance in various applications.
– Trustworthiness of LLM outputs, preventing unintended or malicious outcomes.
– Responsible LLM security assurance for users and stakeholders.
Top 10 LLM security risks
OWASP (Open Web Application Security Project) has expanded its focus to address the unique security challenges associated with LLMs. Here is the full list of these LLM security risks and tools to mitigate them:
1. Prompt Injection
Manipulating the input prompts given to a language model to produce unintended or biased outputs.
Tools & methods to use:
– Input validation: Implement strict input validation to filter and sanitize user prompts.
– Regular expression filters: Use regular expressions to detect and filter out potentially harmful or biased prompts.
2. Insecure Output Handling
Mishandling or inadequately managing the outputs generated by a language model, leading to potential security or ethical issues.
Tools & methods to use:
– Post-processing filters: Apply post-processing filters to review and refine generated outputs for inappropriate or biased content.
– Human-in-the-loop review: Include human reviewers to assess and filter model outputs for sensitive or inappropriate content.
3. Training Data Poisoning
Introducing malicious or biased data during the training process of a model to influence its behavior negatively.
Tools & methods to use:
– Data quality checks: Implement rigorous checks on training data to identify and remove malicious or biased samples.
– Data augmentation techniques: Use data augmentation methods to diversify training data and reduce the impact of poisoned samples.
4. Model Denial of Service
Exploiting vulnerabilities in a model to disrupt its normal functioning or availability.
Tools & methods to use:
– Rate limiting: Implement rate limiting to restrict the number of model queries from a single source within a specified time frame.
– Monitoring and alerting: Ensure continuous monitoring of model performance and set up alerts for unusual spikes in traffic.
5. Supply Chain Vulnerabilities:
Identifying weaknesses in the supply chain of AI systems, including the data used for training, to prevent potential security breaches.
Tools & methods to use:
– Data source validation: Verify the authenticity and quality of training data sources.
– Secure data storage: Ensure secure storage and handling of training data to prevent unauthorized access.
6. Sensitive Information Disclosure:
Unintentionally revealing confidential or sensitive information through the outputs of a language model.
Tools & methods to use:
– Redaction techniques: Develop methods for redacting or filtering sensitive information from model outputs.
– Privacy-preserving techniques: Explore privacy-preserving techniques like federated learning to train models without exposing raw data.
7. Insecure Plugin Design:
Designing plugins or additional components for a language model that have security vulnerabilities or can be exploited.
Tools & methods to use:
– Security audits: Conduct security audits of plugins and additional components to identify and address vulnerabilities.
– Plugin isolation: Implement isolation measures to contain the impact of security breaches within plugins.
8. Excessive Agency:
Allowing a language model to generate outputs with excessive influence or control, potentially leading to unintended consequences.
Tools & methods to use:
– Controlled generation: Set controls and constraints on the generative capabilities of the model to avoid outputs with excessive influence.
– Fine-tuning: Fine-tune models with controlled datasets to align them more closely with specific use cases.
9. Overreliance:
Excessive dependence on the outputs of a language model without proper validation or consideration of potential biases and errors.
Tools & methods to use:
– Diversity of models: Consider using multiple models or ensembles to reduce overreliance on a single model.
– Diverse training data: Train models on diverse datasets to mitigate bias and ensure robustness.
10. Model theft:
Unauthorized access or acquisition of a trained language model, which can be misused or exploited for various purposes.
Tools & methods to use:
– Model encryption: Implement encryption techniques to protect the model during storage and transit.
– Access controls: Enforce strict access controls to limit who can access and modify the model.
Further reading
Explore more on LLMs and LLMOps by checking out:
- LLMOPs vs MLOPs: Discover the Best Choice for You
- Compare 45+ MLOps Tools: A comprehensive vendor benchmark
- Network security software.
If you have more questions, let us know:


Comments
Your email address will not be published. All fields are required.