Retrieval-Augmented Generation (RAG) is an AI method that improves large language model (LLM) responses by using external information sources.
We benchmarked 4 embedding models and 3 chunk sizes to understand the practical performance of RAG systems. We examined how each parameter influences retrieval accuracy and response quality.
Explore the RAG models and tools, what RAG is, how it works, its benefits, and the current situation in the LLM landscape.
RAG benchmark results
We used our methodology to benchmark 10 different LLMs and evaluate the impact of RAG parameters, such as chunk size and embedding models.
Embedding models
RAG systems’ performance heavily depends on the quality of embedding models, as they directly influence the system’s accuracy and effectiveness in retrieving relevant information.
To assess this, we evaluated the performance of 4 embedding models across 10 LLMs:
In the embedding benchmark, we used:
- Chunk size: 512
- Vector database: Pinecone
The average success rate of each embedding model:
These results show that Google Gemini embedding has the highest average accuracy, while mistral-embed has the lowest, which shows the importance of choosing an embedding model in RAG systems. The embedding model affects retrieved information quality and generated responses’ correctness.
Chunk size
Chunk size in RAG systems determines how large the text segments are when they are divided for processing. These segments are then converted into vectors by embedding models and stored in a vector database. When a question is posed, the model retrieves the most relevant segments from the vector database and generates a response based on this information.
The average success rate of each chunk size:
Our findings indicate that a chunk size of 512 generally delivers the best performance across models, though variations exist depending on the specific LLM and embedding model used.
The choice of chunk size and embedding model should be optimized to ensure the RAG system performs accurately:
The benchmark results show the role of chunk size in RAG systems. Chunk size directly affects how text is segmented and the quality of the retrieved information, requiring a balance to ensure the system operates both efficiently and accurately.
In the chunk size benchmark, we used:
- Embedding model: OpenAI text-embedding-3-small
- Vector database: Pinecone
RAG benchmark methodology
This study was specifically designed to evaluate the performance of Retrieval-Augmented Generation (RAG) systems. To test RAG’s ability to retrieve and generate accurate and relevant information from a vector database, we prepared a dataset based on CNN News articles and formulated questions. The tests focused on examining the impact of critical parameters such as chunk size and embedding models.
- CNN News articles were loaded into a vector database. This database served as the knowledge source for the LLM, ensuring that the model-generated responses were solely based on the provided data.
- The tested LLMs were configured via API keys to respond to questions. The models were restricted to accessing only the information in the vector database, operating independently of external knowledge sources.
- Each response generated by the LLM was compared against the ground truth in the source articles. This comparison was performed automatically using an accuracy evaluation system, with the accuracy rate calculated based on the exact match between the responses and the article data.
RAG vs. Context Window
RAG retrieves external data for queries, while context windows process fixed amounts of text. As context windows expand to millions of tokens, the necessity of RAG is questioned.
We benchmarked the RAG against a long context window approach:
For context window:
We used Llama 4 Scout’s native context length.
For RAG:
- LLM: Llama 4 Scout
- Vector database: Pinecone
- Embedding model: OpenAI text-embedding-3-large
- Chunk size: 512
Llama 4 achieved an accuracy of 78% when using RAG, compared to 66% when relying solely on its long context window. This performance gap highlights the advantage of RAG in maintaining accuracy, even as context lengths grow.
Why RAG remains effective
RAG systems leverage external knowledge bases like vector databases to retrieve only the most relevant information for a given query. By segmenting the data into chunks and embedding them, Llama 4 was able to focus on high-quality, contextually relevant data rather than processing an entire lengthy context.
This avoids the clutter of irrelevant data that often overwhelms models in long-context scenarios. RAG helps the model maintain clarity and deliver more accurate responses by focusing on smaller, targeted inputs.
In long context lengths, models often struggle to process and prioritize information effectively, leading to diminished performance.1
Can long context windows replace RAG?
Long context windows can process large datasets in one go. Still, their practical downsides, such as performance drops and computational inefficiency, make RAG a more dependable option for tasks needing high accuracy.
RAG systems address these challenges by adjusting parameters like chunk size and embedding models, achieving a balance between efficiency and effectiveness. Context windows provide a limited view of the input, whereas RAG retrieves relevant external information to enhance response quality. This makes RAG better suited for tasks needing up-to-date or domain-specific knowledge that exceeds the model’s internal training data.
While context windows can work for simpler tasks within the model’s token limit, RAG is more effective when external knowledge is required.
Methodology for RAG vs. context window benchmark
We evaluated the performance of Llama 4 Scout using two approaches: RAG and a long context window. For RAG, we integrated Llama 4 Scout with Pinecone as the vector database, using OpenAI’s text-embedding-3-large model for embeddings and a chunk size of 512.
For the context window approach, we relied solely on Llama 4 Scout’s native context length without external retrieval. Both methods were evaluated using our previously mentioned dataset, with accuracy calculated as the percentage of correct responses to a set of queries.
Why is RAG important now?
The importance of Retrieval-Augmented Generation (RAG) has increased in recent years due to the growing need for AI systems that provide accurate, transparent, and contextually relevant responses. However, business leaders may not know the term, as RAG is a recently emerging area (See Figure below).

As businesses and developers seek to overcome the limitations of traditional Large Language Models (LLMs), such as outdated knowledge, lack of transparency, and hallucinated outputs, RAG has emerged as a critical solution.
What are the available RAG models and tools?
Retrieval-Augmented Generation (RAG) models and tools can be divided into three categories:
- LLMs with Built-in RAG Capabilities to enhance response accuracy by accessing external knowledge.
- RAG libraries and frameworks that can be applied to LLMs for custom implementations.
- Components, such as integration frameworks, vector databases, and retrieval models, that can be combined with each other or with large language models (LLMs) to build RAG systems.
LLMs with Built-in RAG Capabilities
Several LLMs now feature native RAG functionality to enhance their accuracy and relevance by retrieving external knowledge.
- Meta AI: The RAG model from Meta AI integrates retrieval and generation within a single framework, using Dense Passage Retrieval (DPR) for the retrieval process and BART for generation. This model is available on Hugging Face for knowledge-intensive tasks.
- OpenAI Retrieval Plugin: This plugin combines ChatGPT with a retrieval-based system to enhance its responses. You can set up a database of documents and use retrieval algorithms to find relevant information to include in ChatGPT’s responses.
- Anthropic’s Claude: Includes a Citations API for models like Claude 3.5 Sonnet and Haiku, enabling source referencing.
- Mistral’s SuperRAG 2.0: This model offers retrieval with integration into Mistral 8x7B v1.
- Cohere’s Command R: Optimized for RAG with multilingual support and citations, accessible via API or Hugging Face model weights.
- Gemini Embedding: Google’s Gemini embedding model for RAG.
- Mistral Embed: Mistral’s embedding model complements its LLM offerings by producing dense vector embeddings optimized for RAG tasks.
- OpenAI Embeddings: OpenAI offers various embedding models, such as Embedding-3-Large, Embedding-3-Small, and text-embedding-ada-002, each suited for different use cases in natural language processing tasks like retrieval-augmented generation.
RAG Libraries and Frameworks
These tools enable developers to add RAG capabilities to existing LLMs, providing flexibility and scalability.
- Haystack: An end-to-end framework by Deepset for building RAG pipelines, focused on document search and question answering.
- LlamaIndex: Specializes in data ingestion and indexing, enhancing LLMs with retrieval systems.
- Weaviate: A vector database with RAG features, supporting scalable search and retrieval workflows.
- DSPY: A declarative programming framework for optimizing RAG in large language models.
- Pathway: A framework for deploying RAG at scale with data connectivity.
- REALM: Google’s toolkit for retrieval-augmented open-domain question answering, primarily research-oriented.
- Azure Machine Learning: Provides RAG capabilities through Azure AI Studio and Machine Learning pipelines.
- IBM watsonx.ai: Provides frameworks for developing applications that facilitate the implementation of RAG with large language models.
Integration Frameworks for RAG
Integration frameworks streamline the development of context-aware, reasoning-enabled applications powered by LLMs. They offer modular components and pre-configured chains tailored to specific needs while allowing customization.
- LangChain: A framework for creating context-aware applications, commonly used with RAG and LLMs.
- Dust: Facilitates custom AI assistant creation with semantic search and RAG support, enhancing LLM applications.
Users can pair these frameworks with vector databases to fully implement RAG, boosting the contextual depth of LLM outputs.
Vector Databases for RAG
Vector Databases (VDs) handle multidimensional data, such as patient symptoms, blood test results, behaviors, and health metrics, making them vital for RAG systems.
- Deep Lake: A data lake optimized for LLMs, supporting vector storage and integration with tools like LlamaIndex.
- Pinecone: A managed vector database service for RAG setups.
- Weaviate: Combines vector storage with RAG-ready features for retrieval.
- Milvus: An open-source vector database for AI use cases.
- Qdrant: A vector search engine for similarity search.
- Zep Vector Store: An open-source platform that supports a document vector store, where you can upload, embed, and search through documents for RAG.
Other Retrieval Models Supporting RAG
Since RAG leverages sequence-to-sequence and retrieval techniques like DPR, developers can combine these models with LLMs to enable retrieval-augmented generation.
- BART with Retrieval: Integrates BART’s generative power with retrieval mechanisms for RAG.
- BM25: A traditional term-frequency-based retrieval algorithm, widely used for its simplicity.
- ColBERT Model: Based on BERT (Bidirectional Encoder Representations from Transformers) and is designed to combine both dense retrieval and traditional sparse retrieval.
- DPR (Dense Passage Retrieval) Model: A model used for information retrieval tasks, particularly in the domain of question answering (QA) and search systems.
What is retrieval-augmented generation?
In 2020, Meta Research introduced RAG models to manipulate knowledge precisely. Lewis and colleagues refer to RAG as a general-purpose fine-tuning approach that can combine pre-trained parametric-memory generation models with a non-parametric memory.
In simple terms, Retrieval-augmented generation (RAG) is a natural language processing (NLP) approach that combines elements of both retrieval and generation models to improve the quality and relevance of generated content. It’s a hybrid approach that leverages the strengths of both techniques to address the limitations of purely generative or purely retrieval-based methods. Here is a brief video about RAG:
How do RAG models work?
RAG system operates in two phases: Retrieval and content generation.
In the retrieval phase:
Algorithms actively search for and retrieve relevant snippets of information based on the user’s prompt or question using techniques like BM25. This retrieved information is the basis for generating coherent and contextually relevant responses.
- In open-domain consumer settings, these facts can be sourced from indexed documents on the internet. In closed-domain enterprise settings, a more restricted set of sources is typically used to enhance the security and reliability of internal knowledge. For example, the RAG system can look for:
- Current contextual factors, such as real-time weather updates and the user’s precise location
- User-centric details, their previous orders on the website, their interactions with the website, and their current account status
- Relevant factual data in retrieved documents that are either private or were updated after the LLM’s training process.
In the content generation phase:
- After retrieving the relevant embeddings, a generative language model, such as a transformer-based model like GPT, takes over. It uses the retrieved context to generate natural language responses. The generated text can be further conditioned or fine-tuned based on the retrieved content to ensure that it aligns with the context and is contextually accurate. The system may include links or references to the sources it consulted for transparency and verification purposes.
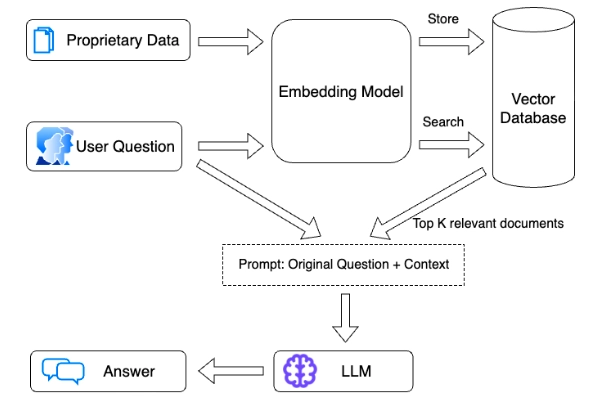
RAG LLMs use two systems to obtain external data:
- Vector database: Vector databases help find relevant documents using similarity searches. They can either work independently or be part of the LLM application.
- Feature stores: These are systems or platforms to manage and store structured data features used in machine learning and AI applications. They provide organized and accessible data for training and inference processes in machine learning models like LLMs.
What is retrieval-augmented generation in large language models?
RAG models generate solutions that can address challenges faced by Large language models (LLMs). These main problems include:
- Limited knowledge access and manipulation: LLMs struggle with keeping their world knowledge up-to-date since their training dataset updates are infeasible. Also, they have limitations in precisely manipulating knowledge. This limitation affects their performance on knowledge intensive tasks, often causing them to fall behind task-specific architectures. For example, LLMs lack domain-specific knowledge as they are trained for generalized tasks.
- Lack of transparency: LLMs struggle to provide transparent information about how they make decisions. It is difficult to trace how and why they arrive at specific conclusions or answers, so they are often considered “black boxes”.
- Hallucinations in answers: Language models can answer questions that appear to be accurate or coherent but that are entirely fabricated or inaccurate. Addressing and reducing hallucinations is a crucial challenge in improving the reliability and trustworthiness of LLM-generated content.
What are the different types of RAG?
Contextual RAG
Contextual RAG is an enhanced version of standard RAG that adds context to each chunk of information before retrieval. It uses techniques such as contextual embeddings and contextual BM25 (Best Matching 25) to provide chunk-specific explanatory context, improving the accuracy and relevance of the retrieved information.
How contextual RAG works
- Preprocessing:
- Similar to Standard RAG, but each chunk is augmented with context before embedding and indexing.
- Context is generated by analyzing the entire document to provide relevant background information about each chunk.
- Retrieval:
- The retrieval process is similar to Standard RAG but leverages the additional context to enhance retrieval accuracy.
- Reranking:
- After initial retrieval, a reranking model evaluates and scores the top chunks based on their relevance to the user’s query, selecting the most pertinent chunks for the final prompt.
Benefits
- Improved accuracy: Reduces retrieval failures significantly by providing necessary context.
- Relevance: Enhances the understanding of the chunks, making the retrieved information more relevant to specific queries.
- Flexibility: It works with various embedding models and can be tailored for specific domains or use cases.
Cons
- Complexity: Requires additional preprocessing steps to generate context, potentially increasing implementation effort.
- Cost: Although it aims to be cost-effective, the need for context generation and reranking could add to computational expenses, especially with very large knowledge bases.

Speculative RAG
Speculative RAG is a hybrid retrieval-augmented generation approach that combines two components: a specialist RAG drafter and a generalist RAG verifier. This method enhances the efficiency of AI responses by utilizing a smaller, specialized language model (LM) to draft responses based on retrieved documents, while a generalist LM focuses on validating these drafts and selecting the most accurate answer.
Methodology
- Retrieval:
- The base model’s knowledge retriever retrieves related documents from a knowledge base relevant to the user query.
- Drafting:
- The specialist RAG drafter, a smaller LM, processes subsets of the retrieved documents, generating multiple answer drafts and their corresponding rationales in parallel. This speeds up the response generation while managing the computational load.
- Verification:
- The generalist RAG verifier, a more comprehensive LM, evaluates the drafted answers. It calculates conditional generation probabilities and assigns confidence scores to each draft. The verifier filters out drafts that do not align with the context of the query, focusing on the most accurate response.
Benefits
- Efficiency: Offloading drafting to a specialized LM allows for rapid processing and reduces the computational burden on the generalist model.
- Improved accuracy: The dual-system approach enhances the quality of responses by allowing the generalist verifier to focus on validating drafts rather than generating content from scratch.
- Scalability: Capable of handling a high volume of documents quickly, making it suitable for scenarios with large knowledge bases.
Cons
- Dependency on retrieval quality: The effectiveness of Speculative RAG heavily relies on the accuracy of the initial document retrieval. If irrelevant documents are retrieved, the specialist drafter may produce less relevant drafts.
- Complexity in integration: Implementing a dual-layered system adds complexity, requiring careful coordination between the specialist drafter and the generalist verifier.
- Potential overhead: While the specialist RAG drafter speeds up the process, there might be additional overhead in managing multiple drafts and confidence scoring, which could offset some of the efficiency gains.
What is Retrieval-Augmented Fine-Tuning (RAFT)?
Retrieval-augmented fine-tuning (RAFT) is a method that enhances the fine-tuning of language models by integrating a retrieval mechanism that allows the model to access external information or documents during training.
How RAFT works
- Fine-Tuning: The model is initially fine-tuned on domain-specific data to tailor its responses.
- Retrieval Mechanism: During the training process, the model retrieves relevant external documents or information to inform its responses.
- Selective Ignoring: The model learns to focus on pertinent details from the retrieved context while disregarding irrelevant information, improving the quality of its outputs.
Benefits
- Improved Output Quality: By accessing relevant external data, the model can generate more accurate and contextually relevant responses.
- Enhanced Knowledge Base: The ability to retrieve information allows the model to expand its understanding beyond its initial training data.
- Flexibility: RAFT can be adapted to various tasks and domains, making it versatile for different applications.
Cons
- Complexity: Implementing RAFT can add complexity to the training process, requiring careful integration of retrieval systems.
- Dependence on Retrieval Quality: The effectiveness of RAFT is contingent upon the quality and relevance of the retrieved documents; poor retrieval can lead to inaccurate outputs.
- Increased Resource Requirements: The retrieval process may require additional computational resources, potentially impacting efficiency.
| Aspect | Traditional RAG | Contextual Retrieval | Speculative RAG | Retrieval Augmented Fine-Tuning (RAFT) |
|---|---|---|---|---|
| Methodology | Breaks down knowledge into small chunks and uses embeddings + BM25 for retrieval | Uses Contextual Embeddings + Contextual BM25, adding context to chunks | Integrates a speculative approach where multiple responses are generated and evaluated | Enhances fine-tuning by integrating a retrieval mechanism that allows access to external data during training |
| Strengths | - Handles large knowledge bases - Combines semantic embeddings with lexical matching | - Improves retrieval accuracy - Provides chunk-specific context - Reduces failed retrievals | - Explores multiple possible answers - Can provide diverse perspectives or solutions | Improves output quality by retrieving relevant external data - Expands knowledge base through external information retrieval |
| Weaknesses | - Often loses context in individual chunks - Exact matches can be missed | - Adds complexity in implementation - Requires prompt customization | - May introduce noise with multiple responses - Increased processing time and resource usage | Complexity in training due to retrieval integration - Dependence on retrieval quality - Increased computational resources for retrieval |
| Key Techniques | - Embedding model converts chunks into vectors - BM25 ranks based on lexical matching | - Adds context to chunks before embedding and BM25 indexing - Uses rank fusion | - Generates multiple hypotheses or responses, then ranks them based on relevance and context | Fine-tuning model with domain-specific data - Selective retrieval mechanism to access external information - Learns to focus on relevant details from retrieved data |
| Improvement Metrics | - Relies on semantic similarity and exact word matches | - Reduces retrieval failure | - Focuses on ranking and selecting the most relevant speculative responses | Improved output quality - Flexibility to tailor outputs based on external data retrieval |
| Scalability | Can handle larger knowledge bases beyond prompt size limitations | Handles large knowledge bases with improved retrieval through contextualization | Potentially scalable, but may require more computational resources for generating multiple responses | Can scale well depending on the retrieval mechanism, but requires more resources due to external document retrieval during training |
| Use Case | Best for general retrieval with diverse knowledge bases | Best for retrieval when precise context is critical (e.g., technical data, legal cases) | Best for scenarios needing creative problem-solving or exploration of multiple viewpoints | Versatile for various tasks and domains, enhances model with external knowledge for more accurate and relevant responses |
| Implementation Cost | Standard embeddings and BM25 computations | Requires manual or automated contextualization of chunks, but cost is reduced with caching | Higher computational cost due to generating and evaluating multiple responses | ncreased cost and resource requirements due to retrieval integration, with careful implementation to ensure quality results from external document retrieval |
What are the benefits of retrieval-augmented generation?
RAG formulations can be applied to various NLP applications, including chatbots, question-answering systems, and content generation, where correct information retrieval and natural language generation are critical. The key advantages RAG provides include:
Improved relevance and accuracy
Generative AI stats show that Gen AI tools and models like ChatGPT have the potential to automate knowledge intensive NLP tasks that make up ~70% of employees’ time. Yet, ~60% of business leaders consider AI-generated content biased or inaccurate, lowering the adoption rate of LLMs.
By incorporating a retrieval component, RAG models can access external knowledge sources, ensuring the generated text is grounded in accurate and up-to-date information. This leads to more contextually relevant and accurate responses, reducing hallucinations in question answering and content generation.
Contextual coherence
Retrieval-based models provide context for the generation process, making it easier to generate coherent and contextually appropriate text. This leads to more cohesive and understandable responses, as the generation component can build upon the retrieved information.
Handling open-domain queries
RAG models excel in taking open-domain questions where the required information may not be in the training data. The retrieval component can fetch relevant information from a vast knowledge base, allowing the model to provide answers or generate content on various topics.
Reduced generation bias
Incorporating retrieval can help mitigate some inherent biases in purely generative models. By relying on existing information from a diverse range of sources, RAG models can generate less biased and more objective responses.
Efficient computation
Retrieval-based models can be computationally efficient for tasks where the knowledge base is already available and structured. Instead of generating responses from scratch, they can retrieve and adapt existing information, reducing the computational cost.
Multi-modal capabilities
RAG models can be extended to work with multiple modalities, such as text and images. This allows them to generate contextually relevant text to textual and visual content, opening up possibilities for applications in image captioning, content summarization, and more.
Customization and fine-tuning
RAG models can be customized for specific domains or use cases. This adaptability makes them suitable for various applications, including domain-specific chatbots, customer support, and information retrieval systems.
Human-AI Collaboration
RAG models can assist humans in information retrieval tasks by quickly summarizing and presenting relevant information from a knowledge base, reducing the time and effort required for manual search.
Fine-Tuning vs. Retrieval-Augmented Generation
Typically, A foundation model can acquire new knowledge through two primary methods:
- Fine-tuning: This process requires adjusting pre-trained models based on a training set and model weights.
- RAG: This method introduces knowledge through model inputs or inserts information into a context window.
Fine-tuning has been a common approach. Yet, it is generally not recommended to enhance factual recall but rather to refine its performance on specialized tasks. Here is a comprehensive comparison between the two approaches:
| Category | RAG | Fine-Tuning |
|---|---|---|
| Functionality | Combines retrieval and content generation | Adapts pre-trained models to create content |
| Knowledge access | Retrieves external information as needed | Limited to knowledge within the pre-trained model. |
| Up-to-date data | Can incorporate the latest information | Knowledge is static, challenging to update. |
| Use case | Suitable for knowledge-intensive tasks | Often used for specific, task-driven applications. |
| Transparency | Transparent due to sourced information | May lack transparency in decision-making. |
| Resource efficiency | May require significant computational resources | Can be more resource-efficient. |
| Domain specificity | Can adapt to various domains and sources | Must be fine-tuned for specific domains. |
Supporting technologies
Semantic Search
Semantic search is a search technique that enables AI systems to understand the meaning and intent behind user queries rather than simply matching keywords. It utilizes natural language processing (NLP) to analyze the context of the words in a query, allowing for more accurate and relevant search results.
How semantic search works
- Understanding Context: Semantic search goes beyond keyword matching by interpreting the meanings of words and phrases in a broader context. It considers synonyms, related terms, and even the intent behind the user’s query.
- Analyzing Relationships: The system breaks down the relationships between words and phrases, enabling it to retrieve results that are relevant to the user’s intended meaning, even if they do not contain the exact keywords used in the query.
By leveraging semantic search, RAG can retrieve information that is contextually relevant to user queries, even if the specific keywords do not match. This improves the quality of the responses generated by the model.
Vector Search
A vector search is a technique that transforms words, phrases, and documents into numerical representations (vectors) in a multidimensional space. This allows for the quantification of semantic relationships between different pieces of data.
How vector search works
- Vector representation: Each word or phrase is represented as a vector—a point in a multidimensional space—where similar meanings have vectors that are positioned closely together.
- Searching for similarity: During a vector search, a query is also transformed into a vector. The search system then looks for vectors that are near the query vector in this multidimensional space. The closer the vectors are, the more semantically similar they are, indicating a higher relevance to the query.
A vector search enables the model to find semantically similar documents quickly and efficiently. This is especially beneficial when working with large knowledge bases, as it allows for faster identification of relevant information based on meaning rather than exact matches.
Disclaimers
RAG is an emerging field, which is why there are few sources that can categorize these tools and frameworks. Therefore, AIMultiple relied on public vendor statements for such categorization. AIMultiple will improve this vendor list and categorization as the market grows.
RAG models and libraries listed above are sorted alphabetically on this page since AIMultiple doesn’t currently have access to more relevant metrics to rank these companies.
The vendor lists are not comprehensive.
Further reading
Discover recent developments on LLMs and LLMOps by checking out:
- LLMOPs vs MLOPs: Discover the Best Choice for You
- Comparing 10+ LLMOps Tools: A Comprehensive Vendor Benchmark
- Compare Top 20+ AI Governance Tools: A Vendor Benchmark
If you still have questions, we are here to help:



Comments
Your email address will not be published. All fields are required.