OCR accuracy is critical for many document processing tasks and SOTA multi-modal LLMs are now offering an alternative to OCR. We tested leading OCR services to identify their accuracy levels in different document types:
- Printed text:
- All solutions achieve >95% accuracy.
- Recommended solution: A free solution like Tesseract.
- Printed media:
- Accuracy range: ~60% to ~90%
- Recommendation: GCP, AWS or Azure OCR services or multi-modal LLMs like GPT-4o or Claude Sonnet 3.7.
- Handwriting:
- Accuracy range: ~20% to ~96%.
- Recommendation: Same as printed media but multi-modal LLMs have a bit higher accuracy.
2025 OCR benchmark results
Product names were shortened above, their full names are listed below. We used their latest versions as of March/2025:
- Claude Sonnet 3.7
- OpenAI GPT-4o
- Amazon Textract API
- Google Cloud Vision API
- Microsoft Azure Document Intelligence API
- Mistral OCR
- Pytesseract
We calculated the accuracy of results as a percentage for printed text, printed media, and handwriting. For the overall results, we added all the 3 results together, so the overall results are calculated over 3 categories.
We were surprised by Mistral OCR’s poor performance given its high scores on open source benchmarks. When examining failure cases, we found it struggled with cursive handwriting and disorganized text layouts (mixed line ordering, inconsistent capitalization) in the handwriting category. Similar issues occurred with printed media, particularly in low-resolution images and those containing multiple font styles.
Dataset
We used 30 documents of 3 categories in this benchmark:
Printed text includes letters, website screenshots, emails, reports, etc.
Printed media includes posters, book covers, advertisements, etc. We aimed to see the success of the OCR tools in different text fonts and placements.
Files in these 2 categories were sourced from the Industry Documents Library (IDL).1
Handwriting: In the handwritten category, some IDL documents were not easy to read so our team generated documents that are similar to the IDL documents. We manually prepared samples of human-legible handwriting. Half of the samples were cursive and the other half were print style (i.e. separate letters were not connected).

Methodology
This benchmark focuses on the text extraction accuracy of the products.
Preprocessing: This is only done for the handwriting category. We took pictures of handwritten documents with our smartphones and using a mobile scanner app, CamScanner:
- Pictures were converted to black-and-white
- The contrast was increased and the background was removed.
OCR: We ran all the products on the same data set and generated text outputs as raw text (i.e. .txt) files. Then, we manually prepared the ground truth including the correct text in all of these files. The ground truth was verified twice by humans.
Comparison: We compared the outputs from OCR solutions with the original texts to measure their accuracy. We used the similarity function from the spaCy library in Python and calculated the similarity score between each product’s output and the original text. The similarity score obtained in this operation is the text accuracy.
The similarity function uses cosine distance formulation for calculating the similarity between two texts. We did not use Levenshtein distance for this benchmark because different products output texts in different orders.
While Levenshtein distance takes these differences into account, we are only looking for how accurately the text is detected but not where it is located. The cosine distance has negligible penalties for such cases, so we decided to use it in this benchmark.
Product selection
There are many OCR products in the market. We need to focus on the ones that can output raw text results. The products for this benchmark are chosen based on:
- Capability to extract text. We did not include solutions that only extract machine-readable (i.e. structured data) in this comparison
- Their popularity in the market
This is not a comprehensive market review and we may have excluded some products with significant capabilities. If that is the case, please leave a comment and we will be happy to expand the benchmark.
Limitations
Advanced capabilities like text location detection, key-value pairing, or document classification were not evaluated in this benchmark.
The sample size will be increased in the next iteration. If you are looking for OCR for handwriting, see our handwriting OCR benchmark with 50 samples.
You can also see our invoice OCR benchmark and receipt OCR benchmark if you are interested.
Previous OCR Benchmark results
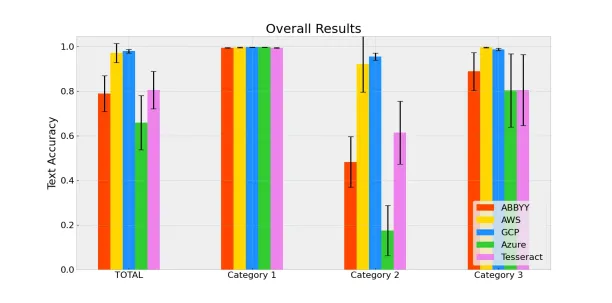
- Google Cloud Vision and AWS Textract are the leading technologies in the market for all cases
- Abbyy also has high performance for non-handwritten documents
- All benchmarked OCRs, including the open source Tesseract performed well on digital screenshots.
Google Cloud Platform’s Vision OCR tool has the greatest text accuracy by 98.0% when the whole data set is tested. While all products perform above 99.2% with Category 1, where typed texts are included, the handwritten images in Category 2 and 3 create the real difference between the products.
The overall results show that GCP Vision and AWS Textract are the dominant OCR products that most accurately recognize the given text.
Notes from the overall results:
- There is a single time when AWS Textract failed to recognize the handwritten text. This situation significantly reduces AWS Textract’s category and total performance. It also increases the deviation for the category and in total because AWS Textract performs very successfully in all other instances.
- Azure is the leading product in Category 1 with 99.8% accuracy. However, the product usually fails to recognize the handwritten text, as seen in the results for the second category. This is the reason why Azure falls behind in the third category and total.
- Tesseract OCR is an open-source product that can be used for free. Compared to Azure and ABBYY, it performs better in handwritten instances and can be considered for handwriting recognition if the user cannot obtain AWS or GCP products. However, it may perform poorer in scanned images.
- Unlike other products, ABBYY outputs a more structured .txt file. ABBYY also considers the location of the text on the image while generating the output file. While the product has further useful capabilities, we are focused only on the text accuracy in this benchmark. And it performed poorly in handwriting recognition.
Removing the “Trouble-Maker” image
As mentioned in the overall results, there was a single “outlier” image where AWS Textract could not recognize any text. While the product shows more than 95% text accuracy in all other images, this instance reduced AWS’ performance and widened its confidence interval.
As this instance might be an exception, we also wanted to compare the products without it. We called this image the “troublemaker” and re-run our results to see if they made a difference.
Here are the new results when the “trouble-maker” is excluded from the data set.
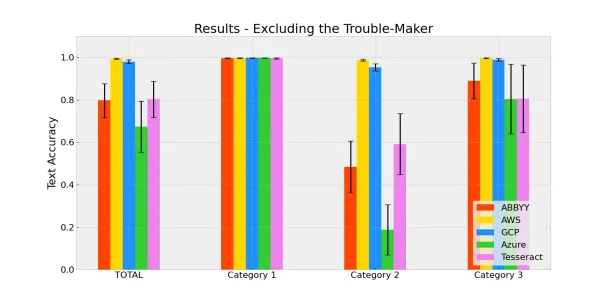
When the “trouble-maker” is excluded, AWS Textract becomes the top performer by an almost perfect (99.3%) text accuracy level with a narrow confidence interval. While the scores do not change much, GCP Vision and AWS Textract are still the top 2 products that perform better than the others in terms of text accuracy.
Results without Handwriting Recognition
The main factor that reduces the text accuracy of certain products is the images that include handwriting. Thus, we excluded all images (all of category 2 and 6 images from category 3) and re-evaluated the text accuracy performance, again.
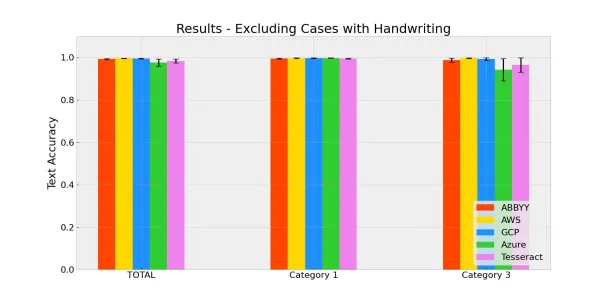
The results are more head-to-head when handwritten images are excluded. AWS Textract and GCP Vision remain the top 2 products in the benchmark, but ABBYY FineReader also performs very well (99.3%) this time. Although all products perform above 95% accuracy when handwriting is excluded, Azure Computer Vision and Tesseract OCR still have issues with scanned documents, which puts them behind in this comparison.
Benchmarked products
We tested five OCR products to measure their text accuracy performance. We used versions available as of May/2021. Used products are:
- ABBYY FineReader 15
- Amazon Textract
- Google Cloud Platform Vision API
- Microsoft Azure Computer Vision API
- Tesseract OCR Engine
Dataset
Although there are many image datasets for OCR, these are
- mostly at character level and do not conform to real business use cases
- or focus on the text location rather than the text itself.
Thus, we decided to create our own dataset under three main categories:
- Category 1 – Web page screenshots that include texts: This category includes screenshots from random Wikipedia pages and Google search results with random queries.
- Category 2 – Handwriting: This category includes random photos that include different handwriting styles.
- Category 3 – Receipts, invoices, and scanned contracts: This category includes a random collection of receipts, handwritten invoices, and scanned insurance contracts collected from the internet.
All input files are in .jpg or .png format.
Limitations
- Limited Dataset: Originally, we had a fourth category that consisted of photos of newspapers to observe the performance of products in the photos of printed documents. However, these photos include too much text which made it hard to generate the ground truth. Thus, we decided not to use them.
- Inconsistencies in output formats: Many images include instances where there are separate texts on the left and right-hand sides. The products extract these texts in different orders causing the output files to be different although texts are accurately detected. This situation prevented us from using other distance measures (like Levenshtein distance) and limited our options for calculating text accuracy.
- Possible Problem with Cosine Distance: The cosine distance uses embeddings while calculating the similarity. For example, comparing the sentences “I like tea” and “I like coffee” would give a higher similarity score than it should be. However, cases like detecting the word “tea” as “coffee” would hardly ever occur, so we did not take this possibility into account in this exercise.
We use other market data (e.g. software reviews, customer case studies) to rank software providers. Feel free to check out our list of OCR providers. However, since most corporates use the term “OCR” when searching for data extraction solutions (i.e. including those that generate machine-readable data), our list has a larger scope and more companies than those presented in this benchmarking exercise.
FAQ
What is OCR?
Optical Character Recognition (OCR) is a field of machine learning that specializes in distinguishing characters within images like scanned documents, printed books, or photos. Although it is a mature technology, there are still no OCR products that can recognize all kinds of text with 100% accuracy. Among the products that we benchmarked, only a few products could output successful results from our test set.
OCR tools are used by companies to identify texts and their positions in images, classify business documents according to subjects, or conduct key-value pairing within documents. Based on OCR results, other technology companies build applications like document automation. For all these business cases, accurate text recognition is critical for an OCR product.
External Links
- 1. pixparse/idl-wds · Datasets at Hugging Face. Pixel Parsing




Comments
Your email address will not be published. All fields are required.