

Deep learning models achieve high accuracy in tasks like speech recognition and image classification, often surpassing human performance. 1 However, they require large training datasets and significant computational power. Cloud inference provides a scalable solution to handle these demands efficiently.
Explore cloud inference, compare it to on-device inference, and highlight its benefits and challenges. Here are some leading tools that can be deployed in cloud inference:
| Tool | Provider | Unique Feature | |
|---|---|---|---|
1. |  Amazon SageMaker Amazon SageMaker |
AWS | Multi-model endpoints, AWS-native |
2. |  Azure Machine Learning Studio Azure Machine Learning Studio |
Microsoft Azure | Kubernetes-native, scalable inference |
3. |  Vertex AI Vertex AI |
AutoML, MLOps, easy deployment | |
4. |  Watson Studio Watson Studio |
IBM | Visual modeling, open-source support |
5. |  H2O.ai H2O.ai |
H2O.ai | Open-source, private LLM deployment |
What is inference?
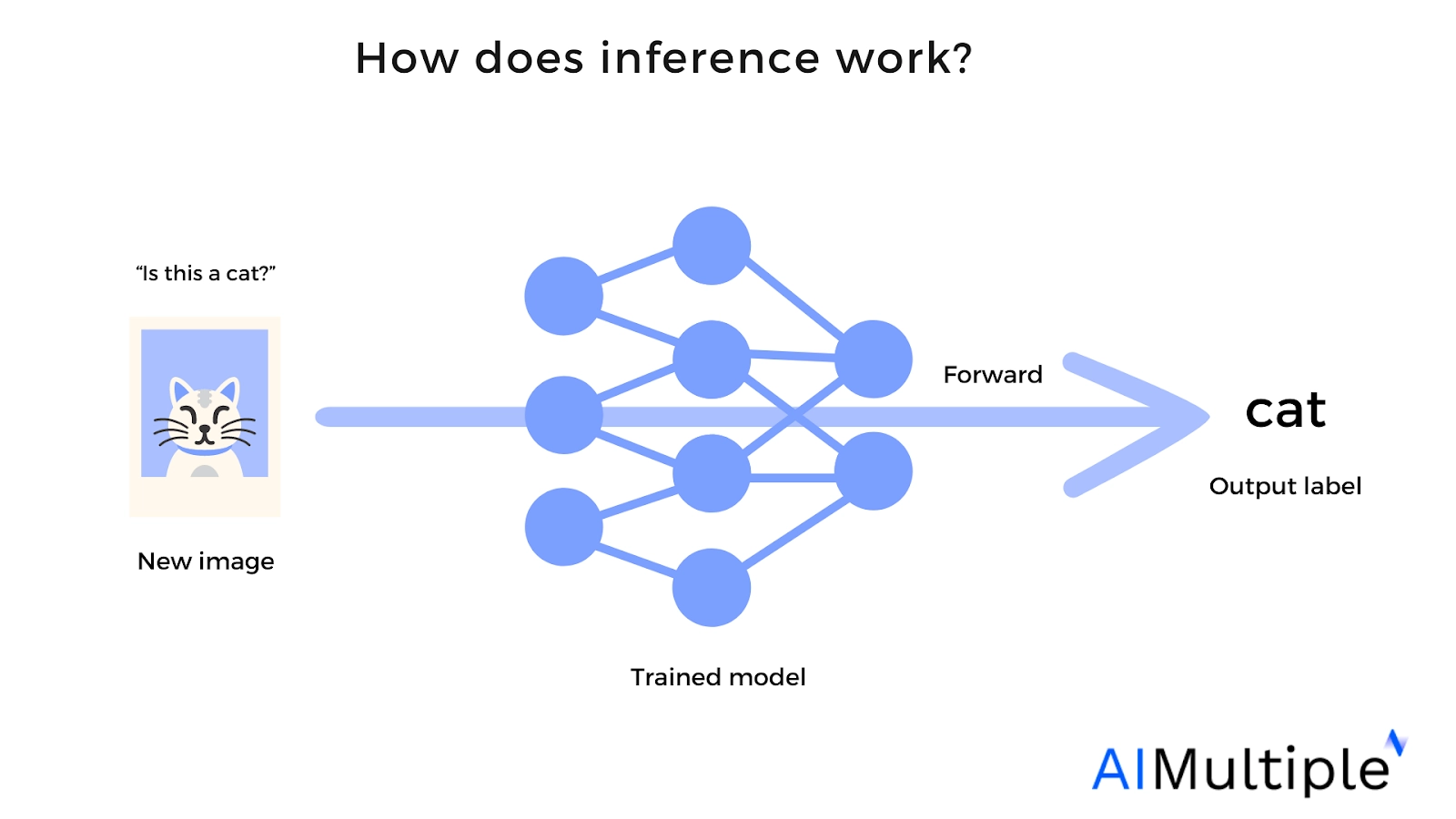
Figure 2. Visualization of how inference works.
Inference is the phase where a trained model processes new data to make predictions or decisions. The model applies the learned weights without further adjustment.
For example, if a model is trained on cat images, it should be able to identify whether a new image contains a cat. However, this process involves billions of parameters and requires high computational resources. Cloud inference addresses this challenge.2
What is cloud inference/inference as a service?
To keep up with the growing demand for machine learning (ML) inference, Meta has increased its infrastructure capacity by 250%.3 This reflects a broader trend—organizations are looking for scalable, high-performance solutions to handle inference workloads efficiently.
Cloud inference refers to running machine learning models on cloud platforms instead of local hardware. This approach allows users to access powerful computational resources remotely, leveraging cloud-based GPUs, TPUs, and other specialized hardware. Since these components are expensive and complex to maintain on-premises, cloud inference offers a practical alternative for businesses that need scalable AI capabilities without heavy infrastructure investments.
Cloud inference vs. inference at source
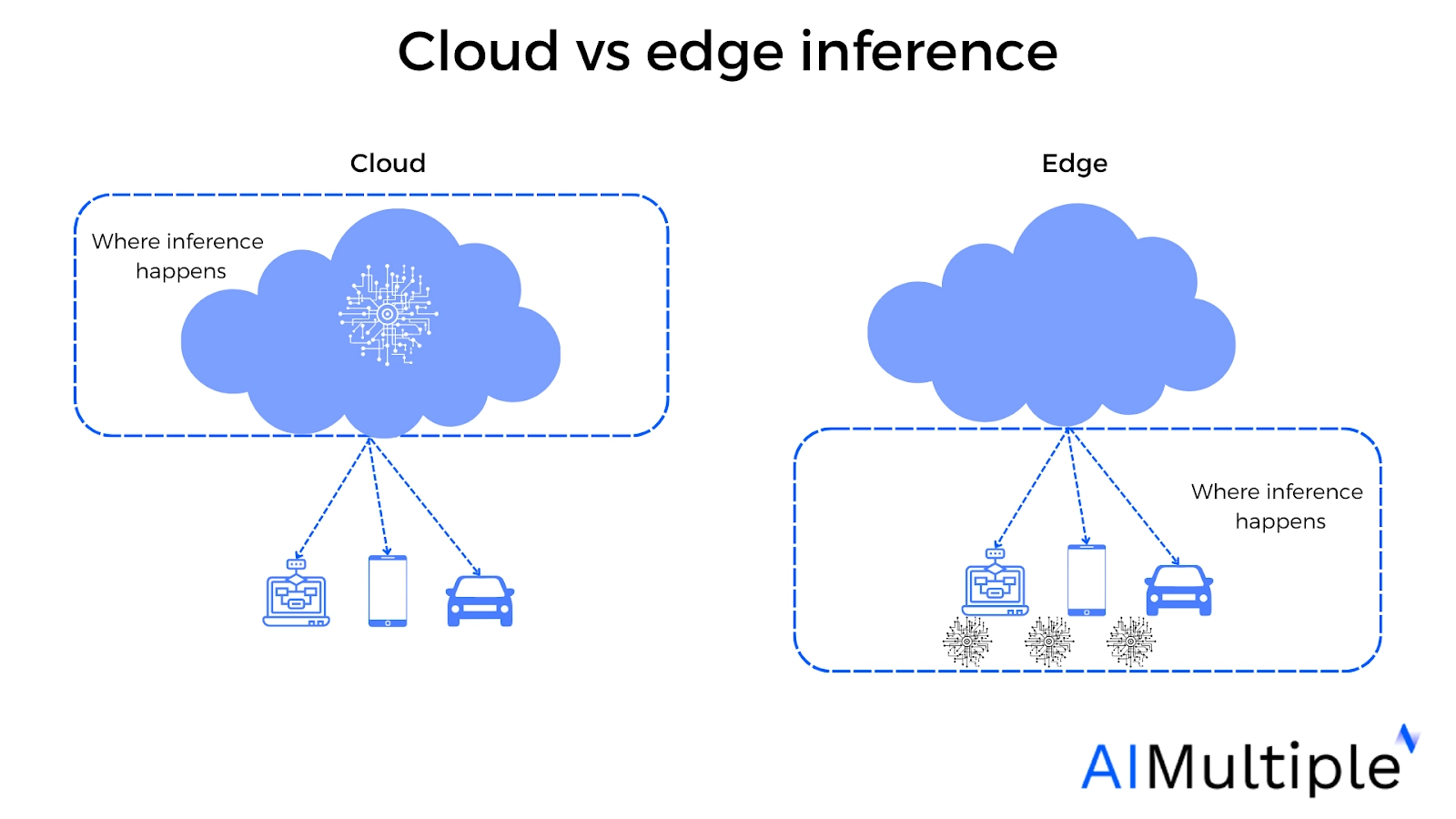
Source: SoftmaxAI4
Figure 3. Visualization of how and where edge vs cloud inference differs.
The primary distinction between cloud inference and on-device (or edge) inference lies in where the computation takes place:
- On-device inference (edge inference) processes data directly on the device where it’s generated, such as an IoT sensor or smartphone.
- Cloud inference sends data to remote cloud servers for processing before returning the results.
Each approach has its advantages. On-device inference offers lower latency and greater privacy since data remains local, but it is limited by the device’s hardware. Cloud inference, on the other hand, provides access to high-performance computing power but relies on internet connectivity and can introduce latency.
Cloud inference in inference time computing
The rising interest in AI efficiency, highlighted by Deepseek’s impact, has intensified the focus on optimizing inference-time computing. Leading cloud providers such as AWS Inferentia, Google TPU v5e, and Azure ML Endpoints are refining their infrastructures to reduce computational overhead while maximizing throughput.
Inference-time computing refers to the computational workload involved in generating predictions from trained AI models. Cloud inference optimizes this process by:
- Reducing latency: Cloud providers use specialized hardware (GPUs, TPUs, FPGAs) to accelerate processing.
- Scaling resources by computing: Cloud platforms dynamically allocate computational power based on demand, ensuring efficiency without over-provisioning.
Advantages of cloud inference
1- It is time sensitive
Cloud-based solutions often offer lower latency due to the high-performance compute capabilities available in the cloud. This is an advantage for applications where real-time results are needed (e.g., fraud detection).
2- It works anywhere
Cloud-based solutions are inherently global, offering the advantage of location independence and the ability to operate across different geographical regions.
3- It has a strong battery life
By offloading heavy computational tasks to cloud servers, there is a significant reduction in the power consumption of local devices.
Key challenges of cloud inference
1- Data leaks
Consider the operation of recommendation systems; they are developed through training on substantial volumes of data, much of which is personal in nature. When inference is conducted utilizing this trained dataset and the process is executed in a cloud environment, there arises a potential risk that the data could be accessed by unauthorized parties.
2- Attacks
Models used in cloud inference are susceptible to various forms of cyberattacks. For instance, most current cloud inference attacks are targeted at images.5 These attacks can compromise the integrity and confidentiality of sensitive data.
Strategies to prevent attacks
To safeguard against attacks in cloud-based inference systems, the following strategies can be implemented:
- Cryptographic methods: They are used to prevent unauthorized replication of training data and access to the model. An example would be encrypting the cloud-based models. Encryption acts as a barrier, ensuring that even if an attacker gains access to the model, they cannot easily understand or replicate the training data.
- Controlled noise: You can minimize the risk of information leakage from the model’s output by adding designed noise to the output vector of the model. This will make it more difficult for attackers to extract meaningful data.
- Prevent overfitting: Overfitting makes a model too tailored to the training data, potentially revealing sensitive information. By randomly removing some connections, or edges, during training, the model becomes less prone to overfitting.
3- Costs
Cloud inference requires balancing accuracy, latency, and cost efficiency. Running large models (e.g., BERT-Large at 192.2 TFLOPs) can be expensive, particularly when handling high-resolution data or scaling inference workloads.
4- Network delays
While cloud inference aims for low-latency performance, network delays and bandwidth limitations can impact real-time applications, especially when transmitting large datasets.
If you need assistance in choosing between edge vs cloud inference, don’t hesitate to contact us:
External Links
- 1. Enabling All In-Edge Deep Learning: A Literature Review | IEEE Journals & Magazine | IEEE Xplore.
- 2. PaLM: Scaling Language Modeling with Pathways.
- 3. Li, B., Samsi, S., Gadepally, V., & Tiwari, D. (2023). “Clover: Toward Sustainable AI with Carbon-Aware Machine Learning Inference Service.” In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (pp. 1-15). Retrieved January 31,2024.
- 4. Edge AI vs Cloud AI - Softmaxai.
- 5. Private Data Inference Attacks against Cloud: Model, Technologies, and Research Directions | IEEE Journals & Magazine | IEEE Xplore.



Comments
Your email address will not be published. All fields are required.