

A GPU cluster is a set of computers where each node is equipped with a Graphics Processing Unit (GPU). Computational demands are ever-rising, whether in cloud or traditional markets. In this context, having the right knowledge on GPU clusters is more important than before.
In this article, we will delve into information on how to form GPU clusters; identify some of the top vendors and present use cases of GPU clusters.
The components of GPU clusters
The components of a GPU cluster can be divided into hardware and software categories. The classification of GPU cluster hardware is divided into two distinct types: heterogeneous and homogeneous.
Heterogeneous cluster: In this category, hardware from both major independent hardware vendors (IHVs), (e.g. AMD,NVIDIA or other AI hardware brands), can be utilized. This classification also applies if different models of the same GPU brand are mixed within the cluster.
Homogeneous cluster: This type refers to a GPU cluster where every single GPU is identical in terms of hardware class, brand, and model.
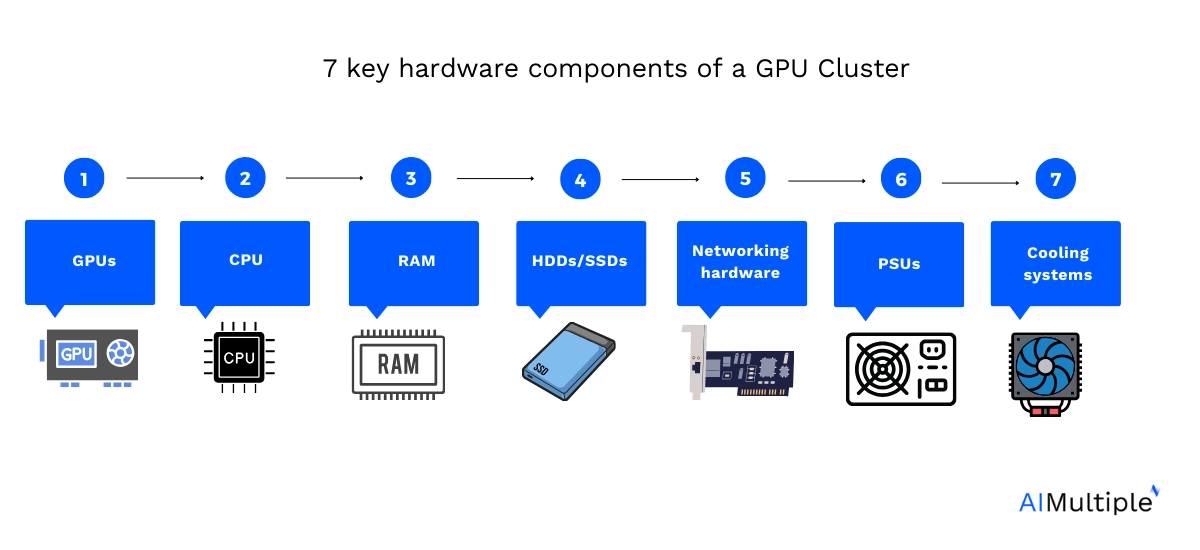
Key hardware components
- GPUs (Graphics Processing Units): The core components of a GPU cluster. GPUs are specialized hardware designed for parallel processing of complex calculations. GPUs are commonly used in tasks such as machine learning, scientific simulations, and rendering.
- CPU (Central Processing Unit): CPUs work in conjunction with GPUs. They handle tasks that are not optimized for parallel processing.
- Memory (RAM): RAMs are high-speed memory modules that store data temporarily for quick access by the CPU and GPUs.
- Storage devices (HDDs/SSDs): For storing data and software. SSDs are preferred for faster data access speeds.
- Networking hardware: This includes NICs and switches. They are essential for the communication between different nodes in the cluster and for connecting the cluster to external networks.
- Power supply units (PSUs): PSUs provide the necessary electrical power to all components, and their reliability and efficiency are crucial for the stable operation of the cluster.
- Cooling systems: They are critical for maintaining the operational integrity of the cluster. GPUs and CPUs generate significant heat, and effective cooling is necessary to prevent overheating and ensure long-term reliability.
Key software components
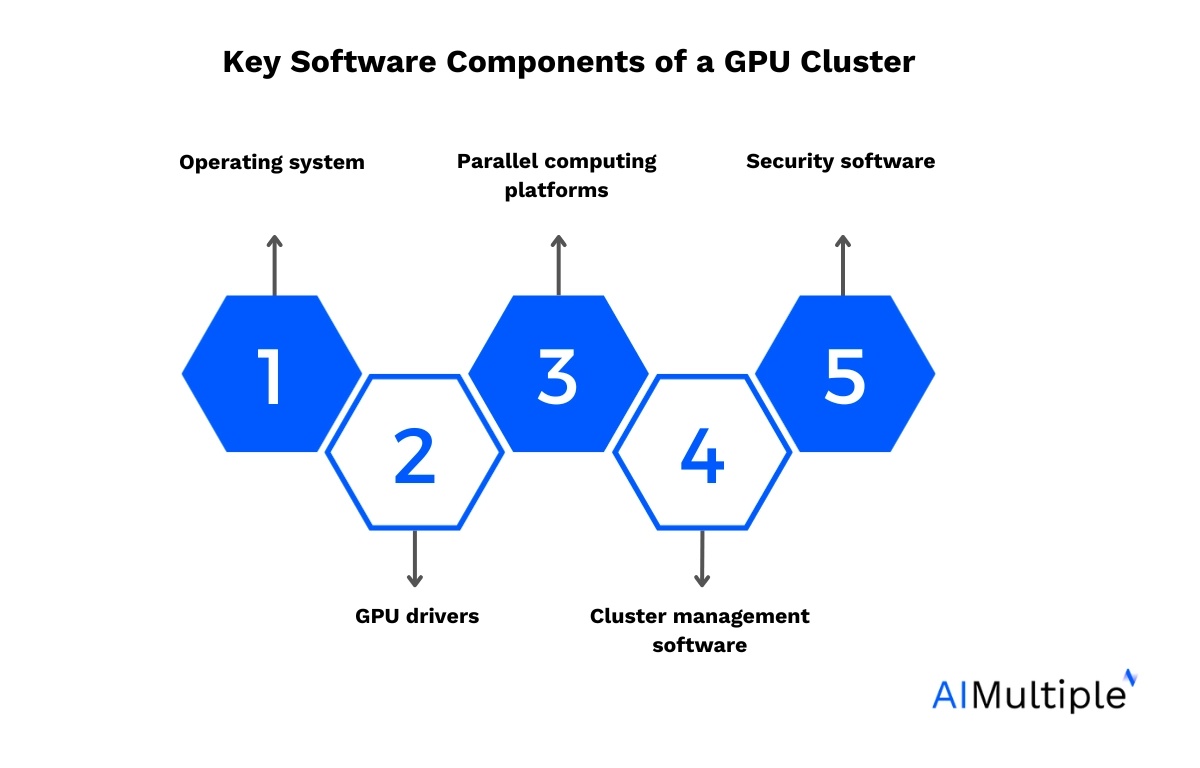
- Operating system: The foundational software that manages the hardware resources and provides the environment for running other software. Typically, a Linux-based system can be used.
- GPU drivers: These drivers are necessary for the operating system and applications to effectively utilize the capabilities of the GPUs.
- Parallel computing platforms (e.g., CUDA, OpenCL): These allow developers to use GPUs for parallel processing tasks. CUDA is especially well-known for NVIDIA GPUs, providing libraries for developers.
- Cluster management software: Important for configuring, managing, and monitoring the hardware components. It helps in maintaining the health of the cluster and ensures optimal performance.
- Security software: They mainly guarantee the protection of the cluster from external threats.
How does a GPU cluster operate?
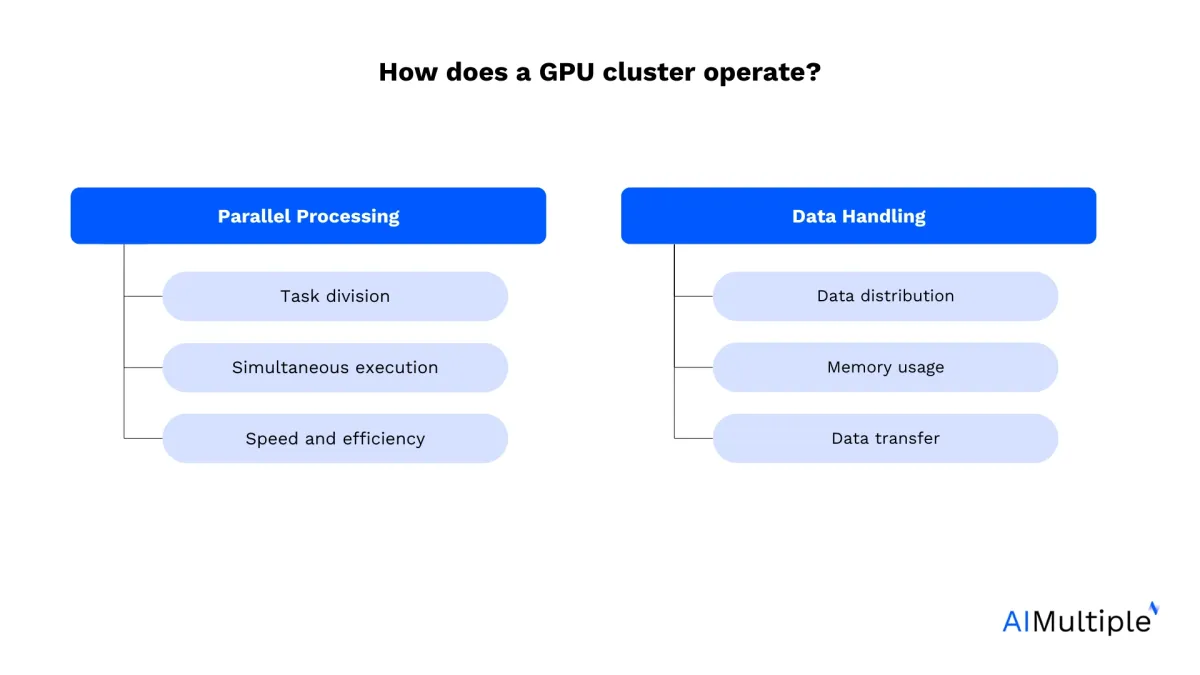
GPU clusters use multiple GPUs to perform complex computations more efficiently than traditional CPUs. They rely on parallel processing (as with AI chips) and efficient data handling.
Parallel processing
Task division: In a GPU cluster, large computational tasks are divided into smaller sub-tasks. This division is based on the nature of the task and its suitability for parallel processing.
Simultaneous execution: Each GPU in the cluster processes its assigned sub-tasks simultaneously. Contrary to CPUs, which typically have a smaller number of cores optimized for sequential serial processing, GPUs have hundreds or thousands of smaller cores designed for parallel processing. This architecture allows them to handle multiple operations simultaneously.
Speed and efficiency: This parallelism significantly speeds up processing, especially for tasks like image processing, scientific simulations, or machine learning algorithms, which involve handling large amounts of data or performing similar operations repeatedly.
Data handling
Data distribution: Data to be processed is distributed across the GPUs in the cluster. Efficient data distribution is crucial to ensure that each GPU has enough work to do without causing data bottlenecks.
Memory usage: Each GPU has its own memory (VRAM), which is used to store the data it is currently processing. Efficient memory management is vital to maximize the throughput and performance of each GPU.
Data transfer: Data transfer between GPUs, or between GPUs and CPUs, is managed via the cluster’s high-speed interconnects. This transfer needs to be fast to minimize idle time and ensure that all units are efficiently utilized.
A practical example:
Consider a task like rendering a complex 3D scene, a typical operation in computer graphics and animation:
- The scene is divided into smaller parts or frames.
- Each GPU works on rendering a part of the scene simultaneously.
- The rendered parts are then combined to form the final scene.
Steps to build a GPU cluster
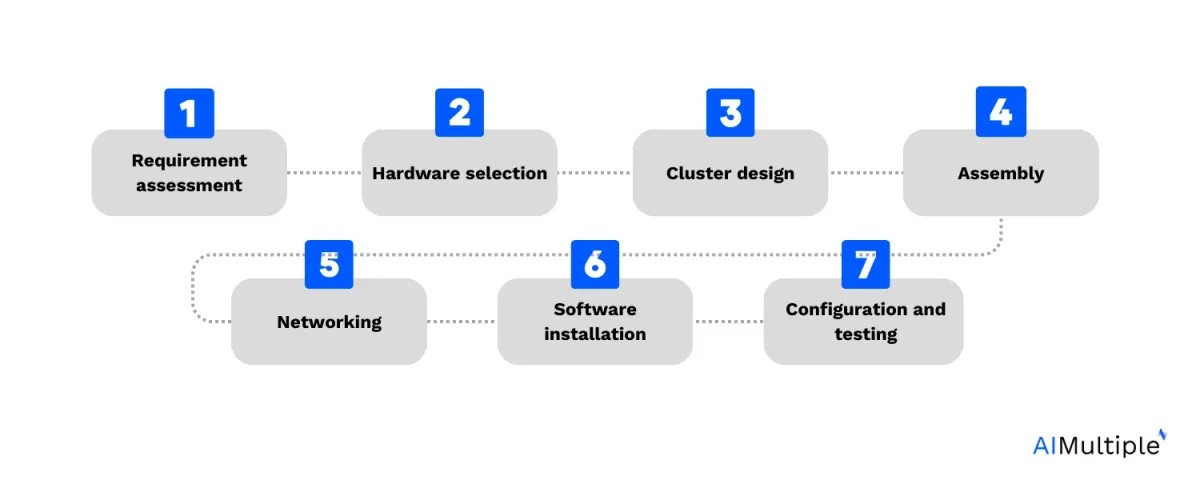
Requirement assessment: Determine the purpose of the GPU cluster (e.g., AI, scientific computing) and assess the computational needs. This will guide the scale and specifications of the cluster.
Hardware selection: Select the right hardware components mentioned above (Figure 1) according to your needs.
Cluster design: Decide on the number of nodes (individual computers) in the cluster. Each node will house one or more GPUs. Plan the physical layout considering space, power, and cooling requirements.
Assembly: Assemble the hardware components. This includes installing CPUs, GPUs, memory, and storage on the motherboards and mounting them in a rack or enclosure.
Networking: Connect the nodes using the networking hardware. Ensure high bandwidth and low latency for efficient communication between nodes.
Software installation: Install an operating system, typically a Linux distribution for its robustness in cluster environments. Install GPU drivers, necessary libraries (like CUDA for NVIDIA GPUs), and cluster management software.
Configuration and testing: Configure the network settings, cluster management tools, and distributed computing frameworks. Test the cluster for stability, performance, and efficiency. This may include running benchmarking tools and stress tests.
5 real-world GPU cluster use cases
- Google brain project
Google has implemented GPU clusters for its Google Brain project, which focuses on deep learning and artificial intelligence research. These clusters are used to train neural networks for applications such as image and speech recognition, improving the capabilities of services like Google Photos and Google Assistant.1
- Weather forecasting at the National Oceanic and Atmospheric Administration (NOAA)
NOAA uses GPU clusters for high-resolution climate and weather modeling. These clusters enable faster and more accurate weather forecasts by rapidly processing enormous datasets, crucial for predicting severe weather events and understanding climate change impacts.2
- Risk analysis and algorithmic trading
Major investment banks and financial institutions employ GPU clusters for complex risk analysis and algorithmic trading. These clusters can process vast amounts of market data in real-time; allow rapid trading decisions and advanced financial modeling to maximize returns and mitigate risks.3
- Large hadron collider (LHC) at CERN
The European Organization for Nuclear Research (CERN) utilizes GPU clusters to process data from the Large Hadron Collider. These clusters help in analyzing the vast amounts of data generated by particle collisions, aiding in discoveries in particle physics, like the Higgs boson detection.4
- Pharmaceutical research and drug discovery
Pharmaceutical companies leverage GPU clusters for molecular dynamics simulations, critical in drug discovery and development. These simulations help understand drug interactions at the molecular level, speeding up the development of new medications and therapies.5
Top Companies in GPU Cluster Area
| System Builder | Server Model | NVIDIA GPU | GPU Connectivity | Max GPU | CPU | Max CPU |
|---|---|---|---|---|---|---|
| ASRock Rack | 4U8G-ROME2/2T | H100 PCIe | PCIe Gen 5 | 8 | AMD Milan | 2 |
| ASUS | ESC4000-E10S | H100 PCIe | PCIe Gen 5 | 4 | Intel Ice Lake | 2 |
| Cisco | UCS C240 M7 | H100 PCIe | PCIe Gen 5 | 2 | Intel Sapphire Rapids | 2 |
| Compal | SR220-2 | H100 PCIe | PCIe Gen 5 | 2 | Intel Sapphire Rapids | 2 |
| Dell Technologies | PowerEdge R760xa | H100 PCIe | PCIe Gen 5 | 4 | Intel Sapphire Rapids | 2 |
| Fujitsu | PRIMERGY RX2540 M7 | H100 PCIe | PCIe Gen 5 | 2 | Intel Sapphire Rapids | 2 |
| Gigabyte | G292-280 | H100 PCIe | PCIe Gen 5 | 8 | Intel Ice Lake | 2 |
| Hitachi | HA8000V / DL380 Gen10 Plus | H100 PCIe | PCIe Gen 5 | 2 | Intel Ice Lake | 2 |
| HPE | ProLiant DL380 Gen10 Plus | H100 PCIe | PCIe Gen 5 | 2 | Intel Ice Lake | 2 |
*This table includes NVIDIA’s ready-made system offerings. Table consists of only representative examples of systems built by each vendor in certain filters.6
Apart from NVIDIA, providers such as Lambda also offer cluster system/structures on cloud. 7
For more solutions, check out:
- Cloud GPU Platforms
- Top Cloud Collaboration Tools
- Amazon Web Services Alternatives with focus on Compute & AI
Businesses and individuals can also build their on premise clusters through NVIDIA, SuperPOD and BasePOT
| Vendor | Market Value | Cluster Management Solution |
|---|---|---|
| NVIDIA | $1.277 trillion | ✅ |
| AMD | $236.63 billion | ✖ |
| Intel | $204.37 billion | ✖ |
| Dell | $56.49 billion | ✖ |
| HPE | $23.02 billion | ✅ |
*Vendors are sorted according to their market value.8
GPU clusters vs CPUs
Computational architecture: GPU clusters are designed for parallel processing. This makes them fit for tasks involving large data sets or computations that can be performed in parallel. Traditional CPU clusters, on the contrary, are better suited for sequential task processing.
Performance: For tasks that can be parallelized, GPU clusters typically offer better stability than CPU clusters.9
Application suitability: GPU clusters excel in areas like deep learning, scientific simulations, and real-time data processing, whereas CPU clusters are often preferred for general-purpose computing and tasks requiring high single-threaded performance.
Are GPU clusters costly to form?
Initial setup costs: High upfront investment in purchasing GPUs, which are generally more expensive than CPUs. Additional costs include networking equipment, storage, cooling systems, and power supplies.
Operational costs: Significant power and cooling requirements lead to higher ongoing operational costs compared to CPU clusters.
Maintenance and upgrade Costs: Regular maintenance and potential upgrades for keeping up with technological advancements can add to the total cost of ownership.
GPU clusters can be costly. Yet, data shows that the general throughput trends for GPU clusters differ from CPU clusters in that adding more GPU nodes to the cluster increases throughput performance linearly.10 In that sense, GPU clusters can perform with more stability with lover costs compared to CPUs.
What security considerations to know about GPU clusters?
Data security: Ensuring the confidentiality and integrity of data processed within the cluster can be especially important for sensitive information in fields like healthcare and finance.
Network security: Protection against external threats is also crucial, given the high volume of data transfer within and outside the cluster.
Physical security: Securing the physical hardware against theft, tampering, or damage, especially in shared or public environments like data centers.
Software security: Regular updates and patches for the operating system, drivers, and other software components to protect against vulnerabilities.
FAQ
What is a GPU kernel, and how is it relevant to GPU clusters?
A GPU kernel is a small program that runs on a GPU and executes many parallel threads to process data quickly. It’s commonly used in AI, scientific computing, and graphics tasks.
In the context of GPU clusters, GPU kernels are the basic units of work distributed across the cluster. Each GPU in the cluster runs many instances of the kernel in parallel, allowing massive workloads to be processed efficiently.
For example, training a large AI model uses a GPU cluster to run GPU kernels simultaneously on different chunks of data, significantly speeding up computation.
Further reading:
- 40+ Cloud Computing Stats From Reputable Sources
- Cloud GPUs for Deep Learning: Availability & Price / Performance
- Cloud Deep Learning: 3 Focus Areas & Key Things to Know in ’24
External links:
- 1. nytimes.com.
- 2. “NOAA Technical Report NESDIS 139”. Retrieved on January 11, 2024.
- 3. Accelerating Trustworthy AI for Credit Risk Management | NVIDIA Technical Blog. NVIDIA Technical Blog
- 4. Scientist Speeds CERN’s HPC With GPUs, AI | NVIDIA Blogs.
- 5. The transformational role of GPU computing and deep learning in drug discovery | Nature Machine Intelligence. Nature Publishing Group UK
- 6. “Qualified System Catalog”. NVIDIA. Retrieved on January 11, 2024.
- 7. Lambda | The Superintelligence Cloud.
- 8. Companies ranked by Market Cap - CompaniesMarketCap.com.
- 9. GPUs vs CPUs for deployment of deep learning models | Microsoft Azure Blog. Microsoft Azure Blog
- 10. GPUs vs CPUs for deployment of deep learning models | Microsoft Azure Blog. Microsoft Azure Blog


Comments
Your email address will not be published. All fields are required.