LLM Fine Tuning Guide for Enterprises in 2024
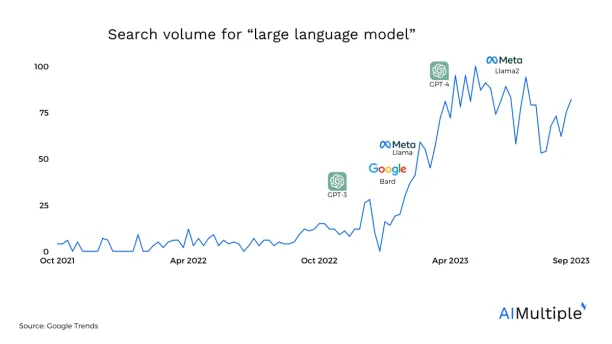
The widespread adoption of large language models (LLMs) has improved our ability to process human language (Figure 1). However, their generic training often results in suboptimal performance for specific tasks. To overcome this limitation, fine-tuning methods are employed to tailor LLMs to the unique requirements of different application areas.
This article explains the reasons, methods, and processes behind the LLM fine tuning, to refine these tools to better suit the intricacies and needs of specific tasks for enterprises.
What is a large language model (LLM)?
A large language model is an advanced artificial intelligence (AI) system, more specifically an enterprise generative AI model, designed to process, understand, and generate human-like text based on massive amounts of data. These models are typically built using deep learning techniques, such as neural networks, and are trained on extensive datasets that include text from a broad range, such as books and websites, for natural language processing.
One of the key aspects of a large language model is its ability to understand context and generate coherent, relevant responses based on the input provided. The size of the model, in terms of the number of parameters and layers, allows it to capture intricate relationships and patterns within the text. This enables it to perform various tasks, such as:
- Answering questions
- Text generation
- Summarizing text
- Translation
- Creative writing
Prominent examples of large language models include OpenAI’s GPT (Generative Pre-trained Transformer) series, with GPT-3 and GPT-4 being the latest iterations.
Foundation models, like large language models, are a core component of AI research and applications. They provide a basis for building more specialized, fine-tuned models for specific tasks or domains.
Figure: Foundation models

Source: Madrona News
What is LLM fine tuning?
Fine-tuning a large language model involves adjusting and adapting a pre-trained model to perform specific tasks or to cater to a particular domain more effectively. The process usually entails training the model further on a smaller, targeted dataset that is relevant to the desired task or subject matter.
The original large language model is pre-trained on vast amounts of diverse text data, which helps it to learn general language understanding, grammar, and context. Fine-tuning leverages this general knowledge and refines the model to achieve better performance and understanding in a specific domain.
Figure: Capabilities of an LLM after the fine tuning
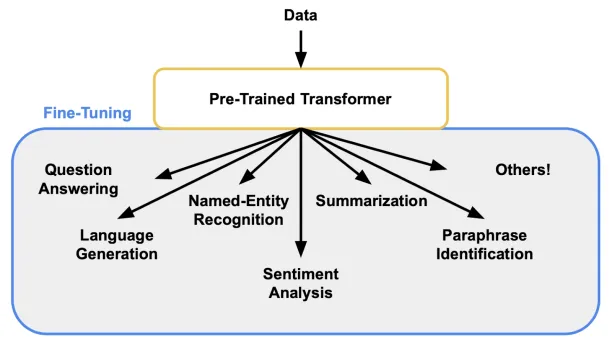
Benefits of LLM fine tuning
Source: AssemblyAI
For example, a large language model might be fine-tuned for tasks like sentiment analysis in product reviews, predicting stock prices based on financial news, or identifying symptoms of diseases in medical texts. This process customizes the model’s behavior, allowing it to generate more accurate and contextually relevant outputs for the task at hand.
- Sentiment analysis
- Chatbot development
- Question answering
What are the methods used in the fine tuning process of LLMs?
Few-shot learning method
Few-shot learning (FSL) can be considered as a meta-learning problem where the model learns how to learn to solve the given problem. In this approach, the model is provided with a very limited number of examples (i.e., “few shots”) from the new task, and it uses this information to adapt and perform well on that task.
Figure: Few-shot learning scenario where the model learns to classify a set of images from the tasks it was trained on
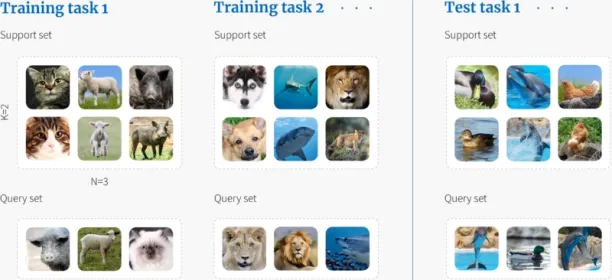
Source: Borealis AI
Source: Borealis AI
This is particularly useful when there’s not enough data available for traditional supervised learning. In the context of LLMs, fine-tuning with a small dataset related to the new task is an example of few-shot learning.
Few-shot learning is a scenario where an LLM is fine-tuned using a small amount of task-specific data, enabling it to perform better on that task with limited examples.
Fine-tuning methods
Fine-tuning is a process that involves adapting a pre-trained model to a specific task or domain by training it further on a smaller, task-specific dataset. Several fine-tuning methods can be used to adjust a pre-trained model’s weights and parameters to improve its performance on the target task:
- Transfer Learning: Transfer learning is a fine-tuning method that involves reusing a pre-trained model’s weights and architecture for a new task or domain. The pre-trained model is usually trained on a large, general dataset, and the transfer learning approach allows for efficient and effective adaptation to specific tasks or domains.
- Sequential Fine-tuning: Sequential fine-tuning is a method where a pre-trained model is fine-tuned on multiple related tasks or domains sequentially. This allows the model to learn more nuanced and complex language patterns across different tasks, leading to better generalization and performance.
- Task-specific Fine-tuning: Task-specific fine-tuning is a method where the pre-trained model is fine-tuned on a specific task or domain using a task-specific dataset. This method requires more data and time than transfer learning but can result in higher performance on the specific task.
- Multi-task Learning: Multi-task learning is a method where the pre-trained model is fine-tuned on multiple tasks simultaneously. This approach enables the model to learn and leverage the shared representations across different tasks, leading to better generalization and performance.
- Adapter Training: Adapter training is a method that involves training lightweight modules that are plugged into the pre-trained model, allowing for fine-tuning on a specific task without affecting the original model’s performance on other tasks.
Differences between few-shot learning & fine-tuning
- The primary difference between fine-tuning methods and few-shot learning is the amount of task-specific data required for the model to adapt to a new task or domain. Fine-tuning methods require a moderate amount of task-specific data to optimize the model’s performance, while few-shot learning methods can adapt models to new tasks or domains with only a few labeled examples.
- Another key difference is that fine-tuning methods generally involve pre-trained models, while few-shot learning methods can be applied to models with or without pre-training. Fine-tuning methods typically provide a better starting point for adapting models to new tasks or domains, while few-shot learning methods are useful when training data is scarce or expensive to obtain.
What are some fine-tuning examples?
OpenAI’s base models are suitable for fine-tuning:
- Davinci
- Curie
- Babbage
- Ada
Figure: GPT-3 base models and their features
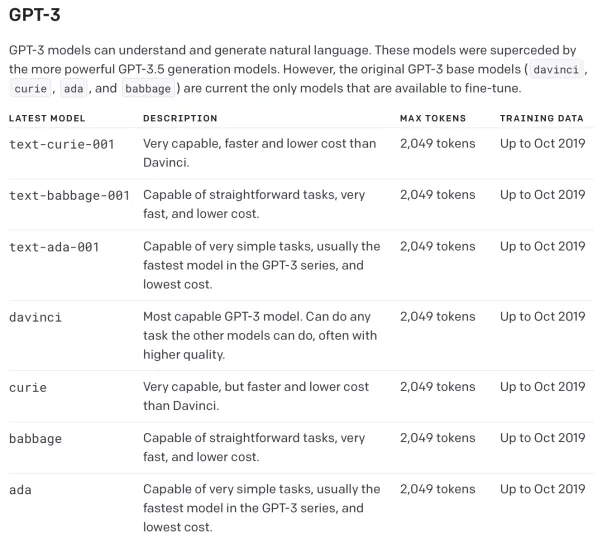
Source: OpenAI
The pricing of these models for fine tuning differs based on the model and the tokens used.
Figure: Pricing of OpenAI’s base models for fine tuning
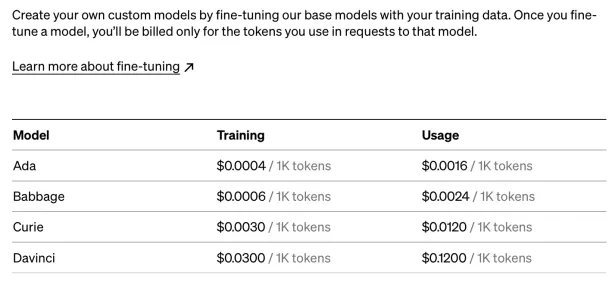
Source: OpenAI
For example, Bloomberg has developed BloombergGPT, a large-scale language model tailored for the financial industry. This model focuses on financial natural language processing tasks such as sentiment analysis, named entity recognition, and news classification.
The BloombergGPT was created using a combination of finance and general-purpose datasets, and led to high scores in benchmark tests (Figure 7).
Figure: How BloombergGPT performs across two broad categories of NLP tasks: finance-specific and general-purpose
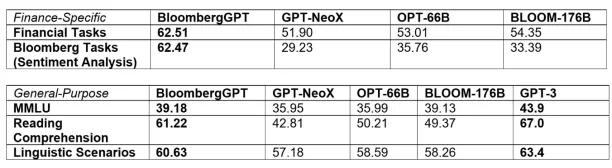
Source: Bloomberg
Why or when does your business need a fine tuned LLM?
Businesses may need fine-tuned large language models for several reasons, depending on their specific requirements, industry, and objectives. Here are some common reasons:
1- Customization
Businesses often have unique needs and goals that may not be addressed by a generic language model. Fine-tuning enables them to tailor the model’s behavior to suit their specific objectives, such as generating personalized marketing content or understanding user-generated content on their platform.
Learn how fine-tuning LLMs can deliver customized products and marketing strategies, improving generative AI in Retail, marketing or insurance experience.
2- Data sensitivity and compliance
Businesses handling sensitive data or operating under strict regulatory environments might need to fine-tune the model to ensure it respects privacy requirements, adheres to content guidelines, and generates appropriate responses that comply with industry regulations.
3- Domain-specific language
Many industries use jargon, technical terms, and specialized vocabulary that may not be well-represented in the general training data of a large language model. Fine-tuning the model on domain-specific data allows it to understand and generate accurate responses within the context of the business’s industry.
Domain specific language can streamline developing SEO strategies with Generative AI for every business.
4- Enhanced performance
Fine-tuning improves the model’s performance on specific tasks or applications relevant to the business, such as:
- Sentiment analysis
- Document classification
- Information extraction
This can lead to better decision-making, higher efficiency, and improved outcomes.
5- Improved user experience
A fine-tuned model can offer a better user experience by generating more accurate, relevant, and context-aware responses leading to increased customer satisfaction, in applications like:
What are the steps involved in the fine tuning of a LLM?
1- Preparing the dataset
This step involves preparing the task-specific dataset for fine-tuning. This may include data cleaning, text normalization (e.g., stemming, tokenization), and converting the data into a format that is compatible with the LLM’s input requirements (i.e. data labeling). It is essential to ensure that the data is representative of the task and domain, and that it covers a range of scenarios that the model is expected to encounter in production.
OpenAI states that each doubling of the dataset size leads to a linear increase in model quality. So, it is better to feed the language model with more data.1
2- Choosing a foundation model and a fine tuning method
Selecting the appropriate base model and fine-tuning method depends on the specific task and data available. There are various LLM architectures to choose from, including GPT-3, BERT, and RoBERTa, each with its own strengths and weaknesses. The fine-tuning method can also vary based on the task and data, such as transfer learning, sequential fine-tuning, or task-specific fine-tuning.
While choosing the base model, you should consider:
- whether the model fits your specific task
- input and output size of the model
- your dataset size
- whether the technical infrastructure is suitable for the computing power required for fine tuning
3- Loading the pre-trained model
Once the LLM and fine-tuning method have been selected, the pre-trained model needs to be loaded into memory. This step initializes the model’s weights based on the pre-trained values, which speeds up the fine-tuning process and ensures that the model has already learned general language understanding.
4- Fine-tuning
This step involves training the pre-trained LLM on the task-specific dataset. The training process involves optimizing the model’s weights and parameters to minimize the loss function and improve its performance on the task. The fine-tuning process may involve several rounds of training on the training set, validation on the validation set, and hyperparameter tuning to optimize the model’s performance.
5- Evaluating
Once the fine-tuning process is complete, the model’s performance needs to be evaluated on the test set. This step helps to ensure that the model is generalizing well to new data and is performing well on the specific task. Common metrics used for evaluation include accuracy, precision, recall, and F1 score.
6- Deploying
Once the fine-tuned model is evaluated, it can be deployed to production environments. The deployment process may involve integrating the model into a larger system, setting up the necessary infrastructure, and monitoring the model’s performance in real-world scenarios.
For a detailed technical guide for creating fine tuned models, we recommend checking OpenAI’s fine tuning guideline.
If you have other questions, please book a call. Would love to answer your questions if you can answer a couple questions about your AIMultiple experience. We are currently offering this service for businesses based in the US or EU.
What are LLM finetuning services?
LLM builders and LLMOps platforms provide services for LLM finetuning. Given the nascent nature of the market, there is a large variation in pricing between different providers:
OpenAI‘s service includes not just finetuning pre-trained models which is already available via API. It also includes training models from scratch using internal data. Interested parties are notified that it may cost $2-3M and take several months.2
MosaicML claims to offer similar services for $200-800k within days or weeks.3
LLMOps refer to a distinct category within MLOps tools, providing essential infrastructure and tools to simplify the construction and deployment of LLMs.
Further reading
- Uncover the various methods employed in fine-tuning large language models with a focus on real-world examples: Large Language Models Examples.
- While fine-tuning improves the efficacy of large language models, it’s essential to address the Risks of Generative AI.
- Fine-tuning large language models comes with legal considerations. Explore the legal landscape surrounding these advanced AI systems in our dedicated article on Generative AI Legal.
External Links
- 1. “Fine-tuning – OpenAI API.” OpenAI Platform. Accessed 16 April 2023.
- 2. “Custom models“. OpenAI. Retrieved November 12, 2023.
- 3. “Post | Linkedin“. Linkedin. November 10, 2023. Retrieved November 12, 2023.

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
5 Risks of Generative AI & How to Mitigate Them in 2024
Generative AI Legal Use Cases & Examples in 2024
Generative AI Ethics in 2024: Top 6 Concerns
Related research

Top 12 ChatGPT Survey Research Use Cases in 2024
Comments
Your email address will not be published. All fields are required.