AI can boost business performance, but 85% of AI projects fail, often due to poor model training.1
Challenges such as poor data quality, limited scalability, and compliance issues hinder success.
Check out the top 5 steps in AI training to help businesses and developers train AI models more effectively. Each step targets real-world obstacles to improve reliability, performance, and business alignment.
5 steps to effective AI training
| AI Training Steps | Challenges | Best Practices |
|---|---|---|
| Dataset Prep | Poor data quality, bias, legal issues | Use diverse data, automate pipelines, apply MLOps, ensure versioning and bias checks |
| Model Selection | Wrong architecture, compliance gaps | Match model to task, use pre-trained models, ensure explainability, leverage tools like Vertex AI |
| Initial Training | Overfitting, limited data, high compute needs | Fine-tune, augment data, simplify model, use prompt engineering |
| Training Validation | Poor generalization, hidden overfitting | Use cross-validation, monitor with accuracy/fairness metrics, validate on real-world data |
| Testing the Model | Inconsistent results, drift in production | Use structured test sets, compare to baselines, review errors, monitor drift, ensure env. consistency |
1. Dataset preparation
High-quality data remains the foundation of AI training. Models in machine learning and deep learning rely on accurate, representative datasets to perform tasks aligned with real-world applications. Data collection methods now include synthetic data, generative AI-assisted generation, and automated pipelines supported by Google AI-powered tools and platforms, such as Vertex AI.
Effective AI data collection requires a clear understanding of project goals, legal constraints, and the intended AI work. Key practices include:
- Defining clear and specific instructions for what the data should reflect.
- Using appropriate methods like custom crowdsourcing, in-house generation, or prepackaged datasets.
- Leveraging automated tools for scaling and monitoring the collection.
- Incorporating diverse, inclusive data to minimize bias and improve generalization.
Modern data preprocessing uses MLOps frameworks to clean, structure, and validate inputs. Annotation, especially for natural language processing and image generation tasks, is both manual and automated to prepare data for large models.
Professionals developing AI skills should understand dataset versioning, data augmentation, and bias mitigation as foundational AI concepts.
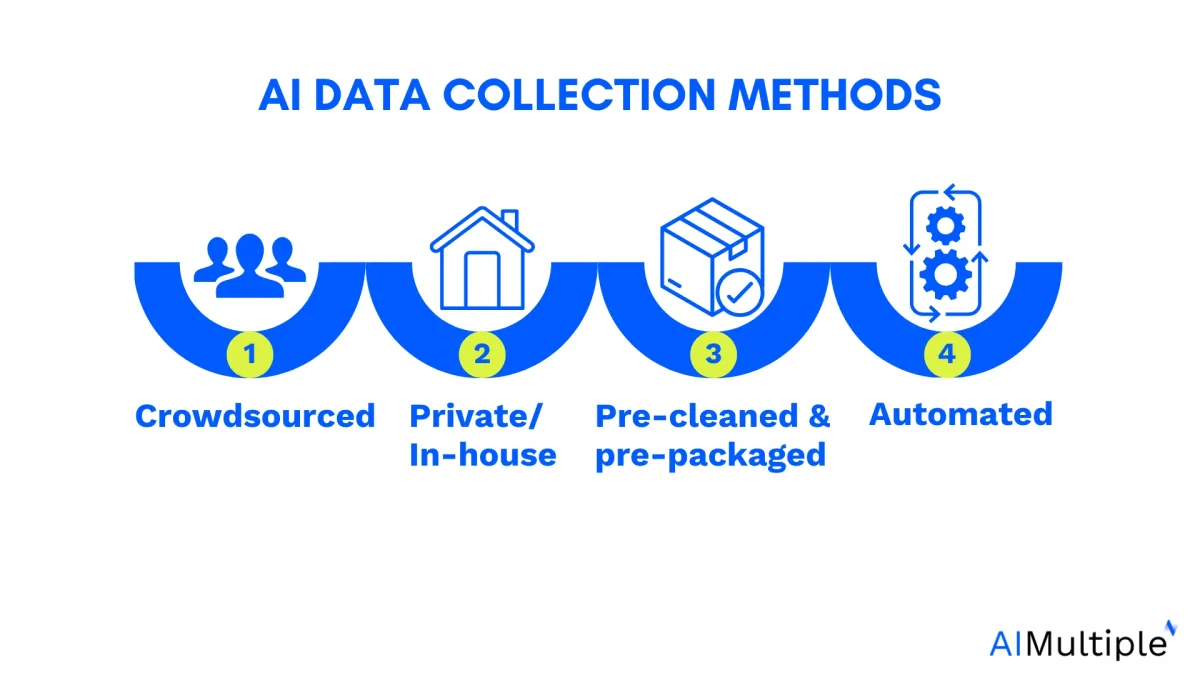
Figure 1: Data collection methods.
2. Model selection
Model architecture remains a critical step in AI training. With the growth of foundational AI concepts and pre-trained models, many teams begin by adapting existing architectures instead of training from scratch.
Model selection depends on:
- The structure and type of data.
- Computational resources.
- Task complexity.
- Required accuracy and generalization.
For image classification, convolutional neural networks are suitable. For natural language tasks, transformer-based models in generative AI tools are widely used. Google Cloud provides access to pre-trained models and custom options on Vertex AI, supporting flexible development.
In areas such as digital marketing or small businesses, using foundation models with prompt tuning or lightweight adaptation helps deliver value more quickly.
AI governance and explainability are also key considerations in model selection to meet ethical and legal requirements. These steps ensure that systems remain accurate and fair over time.
3. Initial training
Initial training introduces the model to the dataset, allowing it to begin learning task-specific patterns. Today, this phase often involves fine-tuning pre-trained models or applying specific instructions, known as prompts, to adapt them to new tasks.
Avoiding overfitting remains essential. A model that memorizes training data will perform poorly on new inputs. Developers address this by:
- Increasing data diversity.
- Applying data augmentation.
- Simplifying model complexity when appropriate.
Techniques such as parameter-efficient fine-tuning and prompt engineering, taught in Google Prompting Essentials Graduate programs, enable effective learning with minimal data and compute resources. These methods are commonly used in high-growth fields such as healthcare, finance, and customer service.
4. Training validation
Validation checks if the model’s behavior aligns with expectations. It uses a separate dataset to surface gaps, errors, and signs of overfitting. This step is essential to ensure generalization and reliable AI performance.
Two main frameworks are used:
- Minimum validation, which applies to one holdout dataset.
- Cross-validation, which involves splitting data into multiple subsets, is commonly used with smaller datasets.
Minimum validation
Minimum validation uses a single split of the dataset into a training set and a validation set. The model is trained on one portion and evaluated on the other. This method is fast and works well when the dataset is large and representative, but it may not fully capture performance variability.
Cross-validation
Cross-validation divides the dataset into multiple equal-sized folds. The model is trained and validated multiple times, each time using a different fold for validation and the rest for training.
This provides a more reliable estimate of model performance, especially for smaller datasets or when testing model stability across data splits. One common form is k-fold cross-validation.
Metrics such as accuracy, precision, recall, and F1 score are used to measure performance. In practical applications, additional indicators, such as fairness, are also monitored.
For example, a natural language processing model trained to identify sentiment in product reviews should be validated on unseen reviews from different sources. Validation confirms whether the model understands tone across varied expressions and formats.
5. Testing the model
Testing evaluates how well the model performs on data it has never seen before. This step confirms the model’s generalization and identifies areas that need adjustment before deployment.
Steps include:
- Preparing the test set with the same structure as training data.
- Applying the model to the test data.
- Comparing predictions to actual values.
- Measuring results with metrics like accuracy or mean absolute error.
- Reviewing errors to identify weaknesses.
- Comparing results to baseline models.
- Recording outcomes for future reference.
For generative AI tasks, such as summarization or image generation, testing is crucial for evaluating performance across edge cases and unusual inputs. It ensures consistent output quality and helps reduce errors in production environments.
Modern systems use continuous evaluation to monitor model drift and accuracy over time. Testing supports the reliability of AI work in upcoming projects and helps maintain performance in dynamic environments.
AI training best practices
Use modular pipelines to isolate training stages:
Dividing the AI training lifecycle into modular, independently executable stages enables better tracking, error isolation, and experimentation. Each stage (data ingestion, preprocessing, model configuration, training, validation, and testing) should have clearly defined input and output contracts. This structure supports faster iteration and reuse across multiple projects or datasets.
Implement configuration-driven training workflows:
Use configuration files or structured templates to manage parameters like model type, optimizer settings, learning rates, data sources, and evaluation metrics. This approach makes AI training more reproducible and minimizes hard-coded logic. Tools like YAML or JSON schemas enable practitioners to test different configurations without modifying core code, allowing for faster tuning and comparison.
Optimize resource usage with batch scheduling and profiling:
Efficient training benefits from analyzing memory use, compute time, and I/O bottlenecks. Use profiling tools to determine the optimal batch size, precision (e.g., float16), and parallelization strategy. Integrate autoscaling and spot instances to reduce cost while maintaining training throughput.
Use version control for data, models, and experiments:
Adopt version control not only for code but also for datasets and model checkpoints. Tools like DVC, MLflow, and Weights & Biases can track every experiment with its associated dataset version, configuration, and metrics. This practice prevents regression and enables rollback in the event of testing or deployment failure.
Automate quality checks with data and model audits:
Build validation steps into CI/CD pipelines for AI. Before training, run automated data audits to check for schema mismatches, missing labels, or skew. After training, validate models against fairness thresholds, performance baselines, or business-specific constraints. This proactive auditing reduces delays caused by manual reviews or model rejection at deployment.
Use ensemble baselines for comparative evaluation:
Instead of relying on a single benchmark model, compare new models against an ensemble of strong baselines. This method provides a more comprehensive understanding of how a model performs across various metrics, helping to identify performance trade-offs. For generative AI tasks, consider incorporating human evaluation or hybrid scoring systems to assess the qualitative outputs.
Maintain test-time consistency with training environments:
Ensure that preprocessing, normalization, and feature engineering used during training are identically applied during testing and deployment. Packaging these transformations into shared modules or using frameworks that preserve feature pipelines prevents mismatches and inference errors.
Schedule model refresh cycles using real-time monitoring triggers:
Rather than retraining at fixed intervals, implement drift detection systems that monitor prediction quality, data distributions, and user feedback to identify and address changes in these metrics. Set thresholds that trigger automated retraining when performance drops below acceptable levels. This approach enables AI systems to remain effective and aligned with evolving inputs or changing business needs.
Validate prompt behavior with structured test cases:
For models using specific instructions called prompts, build a prompt library and maintain test cases that cover edge scenarios, unintended completions, and prompt injection vulnerabilities. Test behavior consistency across prompt templates using version-controlled evaluations to ensure reliable outcomes in genAI applications.
Align training goals with downstream integration requirements:
Early in the AI training process, define how the model will integrate into business systems, APIs, or user workflows. Consider latency, explainability, and inference cost during training design. For example, a model used in customer service should prioritize fast response and clarity over marginal accuracy gains. Aligning design with usage constraints avoids late-stage reengineering.
Operational barriers in AI training
These challenges relate to the infrastructure, workflows, and tooling required to build, train, and maintain AI systems efficiently.
1. Long training cycles and convergence issues
Even with adequate hardware, AI training can require hours to weeks, depending on data size, architecture complexity, and hyperparameter tuning. Convergence may be unstable or delayed due to suboptimal configurations, noisy data, or inadequate learning rate schedules.
Implications:
- Consumes engineering and computing resources inefficiently.
- Delays downstream validation and testing.
- Makes reproducibility and debugging harder.
Mitigation options:
- Profile training runs to identify bottlenecks.
- Use adaptive learning rate strategies.
- Implement early stopping and checkpointing.
2. Lack of standardized MLOps practices
Without consistent MLOps workflows, teams often face fragmented pipelines, manual deployment, inconsistent model versioning, and a lack of experiment traceability. This leads to poor reproducibility, slow debugging, and risky deployments.
Implications:
- Difficult to track which models were trained with what data or parameters.
- Hard to ensure consistency across environments (dev, staging, prod).
- Limit collaboration across data science and engineering teams.
Mitigation options:
- Introduce CI/CD pipelines for ML.
- Use tools like MLflow, DVC, or TFX for model tracking.
- Establish standardized model review and deployment processes.
Organizational barriers in AI training
These challenges stem from internal capacity, skill gaps, and coordination needed to operationalize AI training effectively.
3. Organizational skill gaps
Effective AI training requires multidisciplinary expertise, including data engineering, machine learning theory, software development, and domain knowledge. Many teams lack sufficient depth across all these roles, particularly in fast-paced environments such as startups or smaller enterprises.
Implications:
- Bottlenecks typically occur in areas such as data annotation, model tuning, or deployment.
- Increased reliance on external consultants or managed platforms.
- Risk of misalignment between business needs and AI system behavior.
Mitigation options:
- Invest in cross-training through AI courses or Google Career Certificates.
- Pair domain experts with technical staff early in the project.
- Adopt tools that abstract complexity (e.g., AutoML, low-code platforms).
Legal and compliance barriers in AI training
These challenges involve ethical, regulatory, and policy constraints that govern the use, evaluation, and deployment of data and AI models.
4. Regulatory uncertainty and compliance complexity
AI training activities are increasingly coming under scrutiny from regulators due to concerns over data privacy, model fairness, transparency, and accountability. Legal frameworks, such as GDPR, HIPAA, and the EU AI Act, impose strict requirements on how training data is collected and how models operate.
Implications:
- Increased documentation and audit requirements.
- Need for fairness assessments and explainability tools.
- Risk of fines, delays, or reputational damage due to non-compliance.
Mitigation options:
- Involve legal teams early in the AI training lifecycle.
- Use governance platforms that track model lineage and decision logic.
- Incorporate bias detection and mitigation as part of validation.
FAQs
What training is needed for AI?
Training for AI involves comprehensive learning in artificial intelligence through advanced artificial intelligence courses and self-paced online courses.
Key areas of focus include machine learning, deep learning, natural language processing, computer vision, and data science. Aspiring AI professionals should gain a basic understanding of computer science, programming languages, and data modeling, as well as advanced concepts like neural networks, reinforcement learning, and unsupervised learning.
Hands-on experience with real-world projects and solving real-world problems is crucial. Additionally, familiarity with sophisticated tools, data analysis, data visualization, and exploratory data analysis is essential.
AI training also benefits from understanding cognitive learning theory and human behavior to create more effective AI models. AI professionals, including data scientists and machine learning engineers, should seek to master both narrow AI and strong AI applications, leveraging industry leaders like Google Cloud and IBM Watson for practical insights.
Overall, a combination of academic courses, practical experience, and continuous learning is key to excelling in the field of artificial intelligence.
What are the 4 types of AI learning?
The 4 types of AI learning are supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Each type involves different approaches to training AI models using data, such as labeled data for supervised learning and exploring data patterns for unsupervised learning. Reinforcement learning focuses on decision-making processes, while semi-supervised learning combines elements of both supervised and unsupervised learning.
Further reading
- Sentiment Analysis: How it Works & Best Practices
- Top 5 Open Source Sentiment Analysis Tools
- 3 Ways to Apply a Data-Centric Approach to AI Development
External Links
- 1. Why 85% Of Your AI Models May Fail. Forbes




Comments
Your email address will not be published. All fields are required.