Sentiment Analysis: How it Works & Best Practices in 2024
According to IBM’s 2021 survey with IT professionals, more than 50% of them consider using natural language processing for business use cases. A key insight that NLP unlocks for businesses is turning raw, unstructured text data into interpretable insights for business through sentiment analysis. However, that’s not always clear to business leaders what tangible use cases there are for sentiment analysis and what are the fundamental steps of this method. In this research, we summarized the top business use cases, provided a step by step guide and also top challenges of sentiment analysis.
What is sentiment analysis?
Sentiment analysis is the practice of measuring the negative, neutral or positive attitude in a text. Using natural language processing, the online text data about a certain keyword is analyzed in terms of the intensity of negative or positive words that they contain. The result of sentiment analysis can be an average score of overall positivity, a word cloud of the most popular words in a text or a detailed analysis of associations that can be inferred from the data.
What are the top business use cases of sentiment analysis?
- Excel in customer satisfaction
- Turn web data into market intelligence
- Be the employer of choice
To learn more about real-life examples of sentiment analysis, feel free to check out our detailed blog on the topic.
How does sentiment analysis work?
Step 1) Acquire data:
Sentiment analysis is applied on text data which often requires a rigorous cleaning and processing. Regardless of using a scraping API or web scraping bot, the text data collected from the web will first need to be cleaned from parts that convey no meaning, such as “the” or conjugations of a word. After that, the text needs to be tokenized into words or word groups that can be labeled as positive or negative.
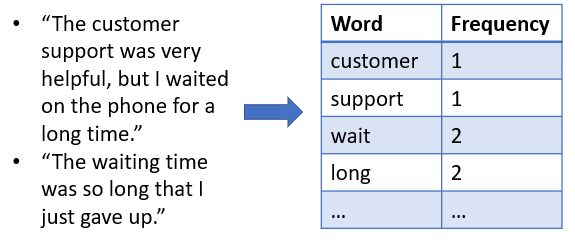
Step 2) Select your model:
- A rule-based model is the simplest approach for sentiment analysis, which is data labeling, either manually or using a data annotation tool. Data labeling classifies words in the extracted text as negative or positive. For example, the reviews that contain the words “good, great, amazing” would be labeled as positive reviews, while the ones that contain “bad, terrible, useless” would be labeled as negative words. This heuristic idea can give a high-level idea very quickly but would miss comments that contain less frequent words or complicated meanings that contain both negative and positive words.

- A machine learning model requires a bit of manual effort during building the model but would give more accurate and automated results over time. Once you have a big amount of text data to analyze, you would split a certain part of it as the test set and manually label each comment as positive or negative. Later on, a machine learning model would process these inputs and compare new comments to the existing ones and categorize them as positive or negative words based on similarity. One advantage of that model is, since the training data would cover more examples of less frequent words or figurative phrases, the model would be able to recognize these patterns in the new data and classify more complex comments accurately.
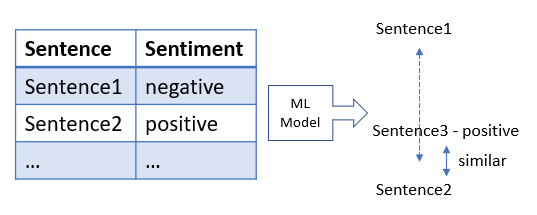
Feel free to check our article to learn more about sentiment analysis methods.
Step 3) Analyze and evaluate:
Both rule-based and machine learning models can be improved over time. For example, a dictionary of negative and positive words can be updated as a live source of reference to classify the new data more accurately. Similarly, there are multiple machine learning models that you can apply on your data and compare to each other in order to fine tune your models over time.
Challenges of Sentiment Analysis:
Nuances and punctuations:
Human language is very rich in expression. Especially with emojis gaining popularity, punctuations in online text data carries a significant amount of meaning. Similarly, different versions of smiley faces can convey a different intensity of a feeling.
Recommendation: Leverage open source dictionaries that can enable you to record punctuations or emojis in a way that natural language processing algorithms can understand.
Fake reviews and misinformation:
Fake product reviews or bot-generated content is a growing concern for many businesses. When you work with a large amount of text data, it may be difficult to identify such fabricated content and whether it is a significant amount of your data that could eventually deviate the results of your analysis.
Recommendation: Use the most up-to-date tips to identify and disseminate fake reviews right on the spot so that they are neither a part of your data set nor visible to your customers. Check out our detailed article about brand protection tools and methods.
Overfitting:
A common pitfall of all machine learning algorithms is overfitting which means your model would fit your training data so well that it considers that data set as the complete sample of possible instances and does not perform well with new data sets. This can happen due to many reasons, such as the sample being too small or high variance in the training data.
Recommendation: Compare different models. This is why the “Analyze and evaluate” step is especially important for machine learning models because this step can help detect overfitting and fine-tune the model by using various methods such as using cross-validation, data augmentation or holding out some part of the data.
To learn more about the challenges of sentiment analysis and the solutions, read our article.
Further reading
- Natural Language Generation (NLG): What it is & How it works
- Top 3 Web Scraping Challenges Solved by AI
- Quick guide to data collection
- 4 Benefits of Using Sentiment Analysis with Your Chatbots
For guidance to choose the right tool, check out data-driven lists of web scrapers and sentiment analysis services and reach out to us:
This article was drafted by former AIMultiple industry analyst Bengüsu Özcan.

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
Top 3 Sentiment Analysis Services in 2024
Sentiment Analysis Stock Market in 2024: 3 Data Sources
Top 4 Benefits of Social Media Sentiment Analysis in 2024
Related research

Comments
Your email address will not be published. All fields are required.