Web scraping is an effective method for collecting and analyzing data from any web source. However, the growing use of anti-scraping technologies by websites, such as CAPTCHA, make web scraping more challenging and time-consuming. CAPTCHAs can prevent automated bots and scripts from accessing and interacting with websites. However, there are best practices to bypass them.
In this article, we’ll explore the different types of CAPTCHA challenges, why they’re used, and the techniques that web scrapers can use to bypass CAPTCHAs. Whether you’re a seasoned web scraper or just starting out, knowing how to circumvent CAPTCHAs is essential for efficiently collecting and analyzing web data.
What is CAPTCHA?
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a challenge-response test used to differentiate human users from automated computer programs, also known as bots.
CAPTCHA is an effective tool for preventing bots from accessing web services and ensuring that web services are accessed by humans rather than bots such as web scraping bots or spam bots.

Why are CAPTCHAs used?
CAPTCHA is used by many web services, including Google, to protect their sites and resources from unwanted or malicious activity. Here are some examples of CAPTCHAs that are commonly used:
- Stopping fake registrations: CAPTCHAs enable website owners to detect fake registrations and fraudulent accounts. They safeguard login pages against automated attacks such as credential stuffing, in which bad actors access accounts using stolen lists of usernames and passwords.
- Preventing spam: CAPTCHAs help website owners identify bots such as credential stuffing or spam bots and allow user-generated content. Websites, for example, can reduce the amount of spam generated by bots by requiring users to identify and fill in a CAPTCHA correctly. CAPTCHAs can be used before a visitor posts a comment, buys something, or creates an account to prevent bots from adding malicious URLs and spamming.
- Blocking web scrapers: Websites use CAPTCHAs as an anti-scraping method to manage web crawling traffic and prevent their servers from overloading with a large number of requests.
- Enhancing website security: CAPTCHAs can be incorporated into a multi-factor authentication (MFA) process to protect online services from unauthorized access and data breaches. It is much more difficult for unauthorized users to access sensitive information or resources.
Why are CAPTCHAs a challenge for web scraping?
CAPTCHAs present a challenge for web scrapers because they are designed to prevent automated bots from accessing and interacting with websites. A web page containing a CAPTCHA test prevents bots and scripts from accessing the site content and scraping data. If a web scraper encounters a CAPTCHA challenge, it will be unable to solve it automatically, and the scraping process will be halted.
Even if you have accessed the target site, a test will continue to run in the background, monitoring your activities and behaviors on the site. If you perform rapid clicks or unusually high pageviews, the website you are scraping will likely suspect your activities and require you to pass a CAPTCHA verification test.
Some web scrapers can solve certain types of CAPTCHAs, such as image-based or audio-based CAPTCHAs. However, more complex CAPTCHAs, such as interactive CAPTCHAs or “No CAPTCHA” reCAPTCHA, can also be difficult for a real person to solve.
Bypassing CAPTCHA: techniques and tips for web scrapers
It is essential to keep in mind that CAPTCHA challenges without permission are generally considered unethical and may be an illegal activity. However, several techniques, including CAPTCHA, have been developed to bypass anti-scraping technologies. Here are some common techniques for bypassing CAPTCHA challenges:
1. Technical Solutions:
- Improving web scraper’s fingerprint: Browser fingerprinting is a tracking technique used by websites to collect data from their visitors’ devices. When you visit a website, for example, your device sends an HTTP request to the target site in order to access and display the content. The target site can access and collect information your browser sends about your devices, such as your web browser, timezone, and IP address.
Improving your web scraper’s fingerprint is important to avoid detection and blocking by websites. To make your browser fingerprint less unique, you can use a user agent and rotate the user agent string.
- Using a CAPTCHA solving service: There are numerous paid and free third-party services that provide CAPTCHA-solving capabilities. Therefore, it is essential to research to identify a reputable service provider. Make sure the CAPTCHA-solving service you use is in accordance with the scraped website’s terms of service, as some websites prohibit their use.
Sponsored
Bright Data’s CAPTCHA solver uses machine learning algorithms to recognize and solve CAPTCHA challenges. The CAPTCHA solver enables web scrapers to circumvent CAPTCHA challenges without interrupting the scraping process.
Figure 8: How to avoid CAPTCHA using Bright Data’s CAPTCHA solution
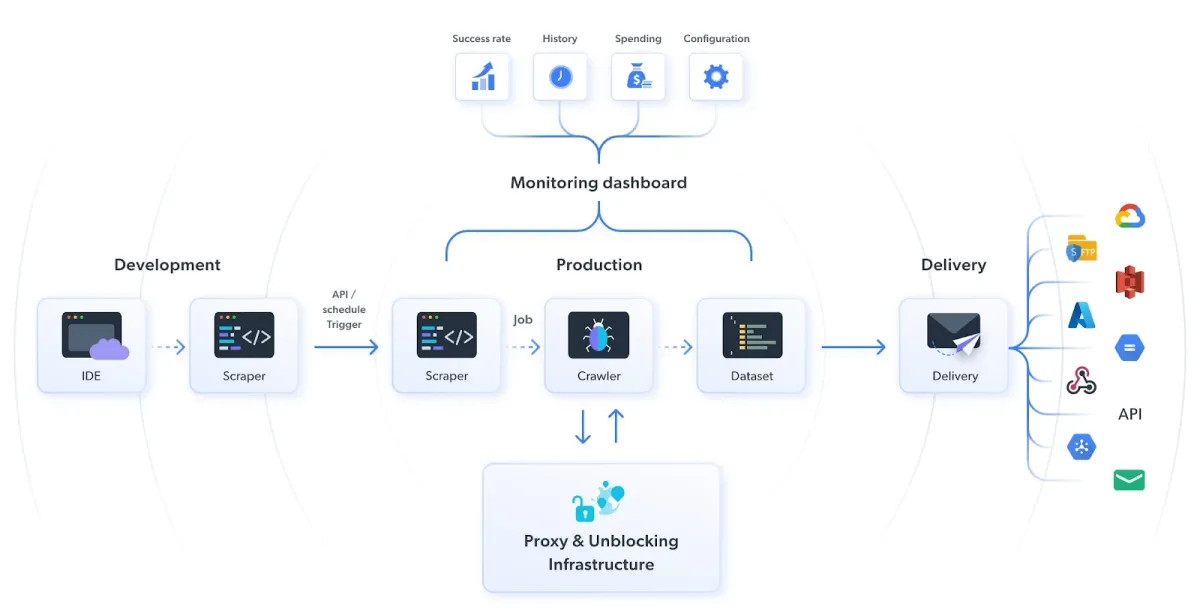
- Browser automation tools: Browser automation tools like Selenium and Playwright can handle CAPTCHA challenges in a testing environment. Users can use browser automation tools to automate the process of filling out forms and interacting with websites.
- Headless browser: A headless browser is a regular web browser that operates without a graphical user interface (GUI), such as icons, buttons, and tabs. There are several open-source headless browsers that you can leverage, including Puppeteer, Selenium, and Playwright. Using a headless browser, you can automate the signup for the web pages that use CAPTCHA technology.
- Proxies: When you make repeated requests to a target server without changing your IP address, the website you are scraping will detect suspicious activity. Then, it will present you with CAPTCHA tests to confirm that you are a bot. Proxies enable users to hide their actual IP addresses and prevent websites from revealing their real identities.
Check out “Top 10 Proxy Service Providers for Web Scraping” to determine which proxy provider is best suited to your needs.
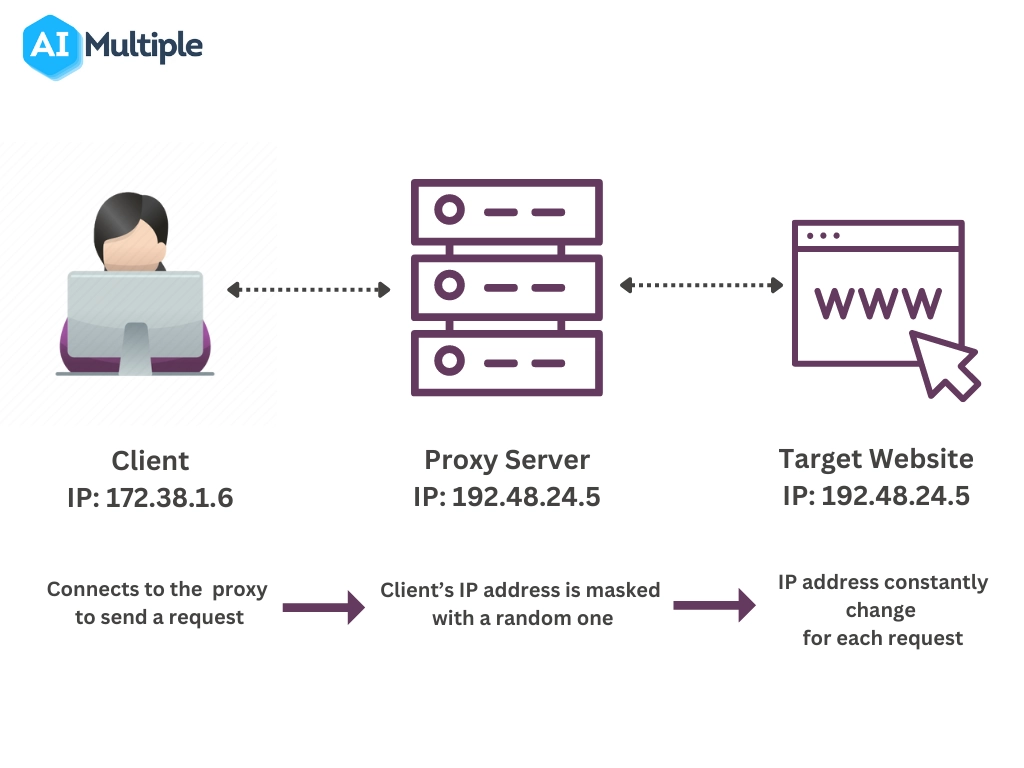
If you intend to scrape a well-protected website, we recommend using a rotating proxy server rather than a static proxy. A rotating proxy continuously rotates client IP addresses and assigns a new IP address for each connection request (Figure 7).
Figure 7: The process flow of rotating proxies
Sponsored
Oxylabs’ Rotating ISP Proxies changes the IP address from a pool of datacenter and residential for every connection or at a specified interval. Because each request appears to come from a different IP address, it is difficult for websites to flag your activities as suspicious.

- Optical Character Recognition(OCR): OCR(Optical Character Recognition) is a technology that recognizes and interprets printed or handwritten characters from scanned images or documents. It can be used to analyze the CAPTCHA image and convert it to a text format that a computer can understand.
OCR technology may recognize and solve a text CAPTCHA challenge by identifying the characters in the image. However, it is typically ineffective at handling more complex CAPTCHA challenges, such as image or audio.
- Machine learning algorithms: It is the process of training a machine learning model to recognize the patterns and features in images and audio of CAPTCHAs and generate a response that can bypass CAPTCHA. The trained data enable the machine learning model to differentiate between the various characters and words in a CAPTCHA challenge.
2. Manual Solutions:
- Solving CAPTCHA by hand: The easiest way to bypass a CAPTCHA is to solve it manually using a human operator. This can be done in-house or outsourced to a third-party CAPTCHA service that employs human solvers. A manual solution can be more cost-effective than outsourcing to a dedicated service. However, it is important to note that this is time-consuming and hard to tackle with advanced CAPTCHA challenges.
- Limiting the rate of requests: Human behavior mimicking, such as scrolling and clicking on links, can make your scraper appear more human when crawling a website. You can limit the rate of requests to a reasonable level, making your scraper appear more like a human browsing a website. For example, rapid-fire connection requests can trigger crawl rate limits and other anti-scraping measures.
How do CAPTCHAs work?
We have complied how CAPTCHAs work in 3 steps:
- Websites challenge the visitor using CAPTCHAs, typically in distorted misaligned text, image recognition puzzles, or an audio clip of a word or series of characters.
- The visitor is expected to correctly identify the word or characters shown in the image or audio clip.
- If the user’s response matches the correct answer, the user is granted access to the website or service.
You’ve likely seen “I’m not a robot” checkboxes on many sites (Figure 2). It is a less intrusive type of CAPTCHA compared to CAPTCHA tests. The “I’m not a robot” checkbox, also known as “No CAPTCHA,” is a newer version of Google’s reCAPTCHA technology.
Unlike traditional CAPTCHAs, which require users to enter distorted words or characters, “No CAPTCHA” analyzes user behavior. It uses machine learning algorithms to understand how users move their mouse or interact with the page.
If the system detects suspicious behavior, such as rapid-fire clicks or many connection requests from a single IP address, the user may be required to solve a more traditional CAPTCHA challenge.
Figure 2: Google reCAPTCHA technology

Different types of CAPTCHAs
There are six different types of CAPTCHAs, each designed to offer a unique level of protection against bots and automated programs. The following are some of the most common CAPTCHA types:
1. Image-based CAPTCHAs
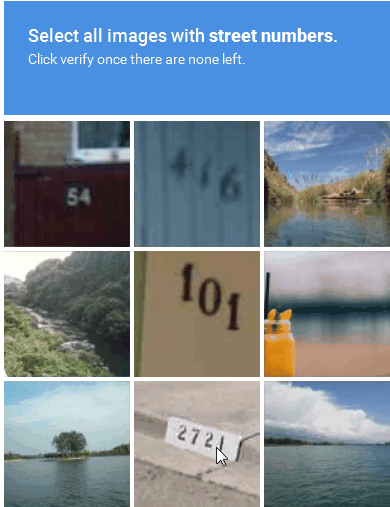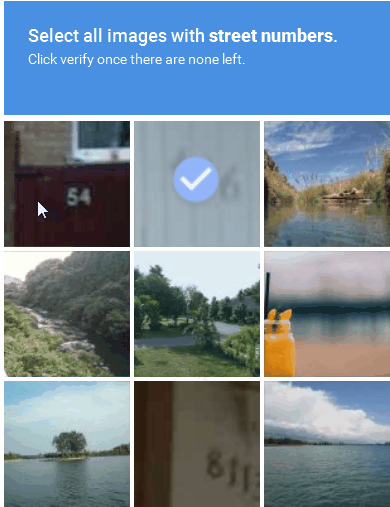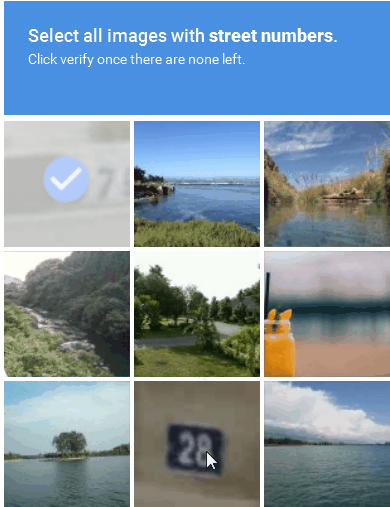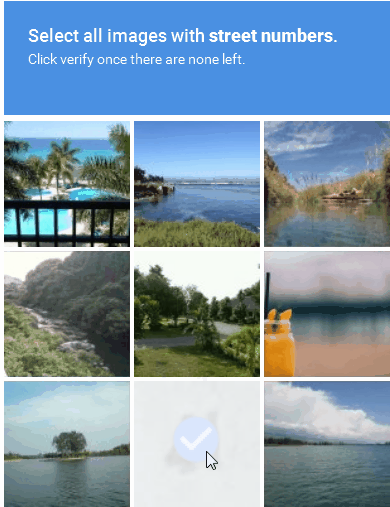
Image-based CAPTCHA displays a distorted image of a word or sequence of characters that the user must recognize and enter into a text field (Figure 3). The image distortion is intended to make it more difficult for automated programs to identify the characters while remaining solvable by a real person. Image-based CAPTCHAs are effective at preventing bots from accessing websites, despite being more difficult and time-consuming for users to solve.
However, some machine learning algorithms, such as CNNs and SVMs, can accurately solve a variety of image-based CAPTCHAs. These algorithms function by analyzing many CAPTCHA large image datasets and training a model to recognize the patterns of the characters within the image. As a result, many websites have adopted more advanced CAPTCHA challenges, such as interactive CAPTCHA and “No CAPTCHA”. These CAPTCHAs use different challenges to differentiate between real people and bots.
Figure 3: An example of an image-based CAPTCHA solution
2. Audio-based CAPTCHAs
Audio-based CAPTCHA presents a distorted audio clip of a word or series of characters (Figure 4). The user must listen to the audio clip and correctly identify the word or characters given in the clip. This type of CAPTCHA is often used for users with visual impairments.
Figure 4: An example of audio-based CAPTCHA
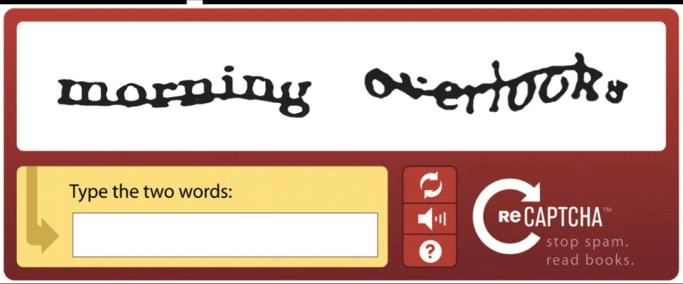
3. Text-based CAPTCHAs
Text CAPTCHA is displayed in odd and distorted formatting. The user must correctly identify and enter into a text field to pass the test.
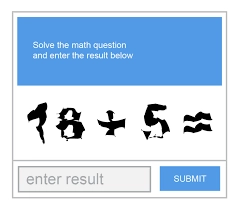
4. Math-based CAPTCHAs
Math-based CAPTCHA presents the user with a simple math problem to solve and enter into a text field, such as “What is 3 + 2?”.
Figure 5: Example of a math-based CAPTCHA
5. Interactive CAPTCHAs
Interactive CAPTCHA presents a series of puzzles or games the user must complete to prove they are human beings.
6. Checkbox-based CAPTCHAs
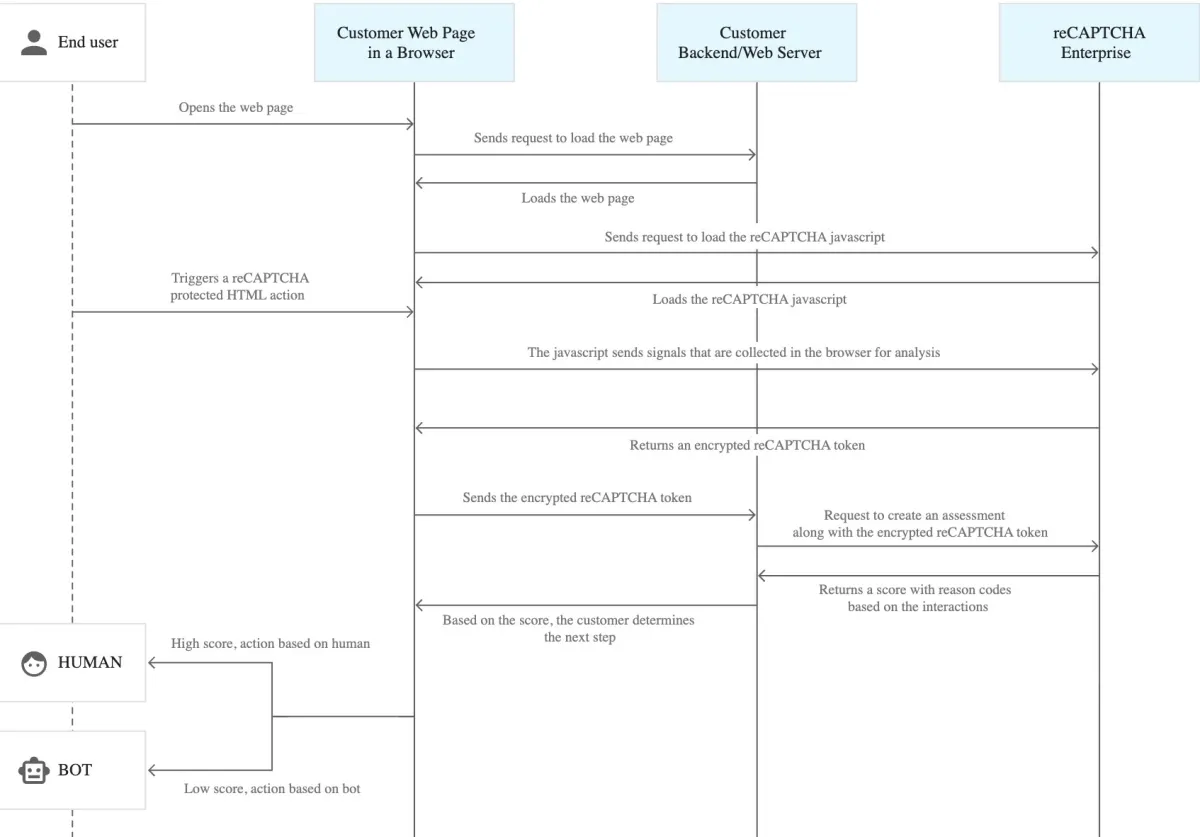
Checkbox-based CAPTCHA is a type of reCAPTCHA. reCAPTCHA is a free service developed by Google to help websites protect their websites from unwanted and malicious activities.
Checkbox reCAPTCHA requires users to check a box to confirm they are not robots. It may present additional challenges, such as selecting all images that match specific criteria or performing a simple math problem.
Figure 6: Process flow diagram of Google reCAPTCHA
Further reading
- 7 Web Scraping Best Practices You Must Be Aware of
- Top 7 Antidetect Browsers
- Top 5 Web Scraping Case Studies & Success Stories
For guidance to choose the right tool, check out data-driven list of web scrapers, and reach out to us:
External Links
- 1. Medium



Comments
Your email address will not be published. All fields are required.