7 Web Scraping Best Practices You Must Be Aware of in '24
Web scraping is useful in many industries, including marketing, real estate, travel, finance, and many others, since it offers automated data collection from online sources. Some websites, on the other hand, want to prevent their data from being scraped. In order to prevent and limit web scraping activities to their content, websites employ numerous anti-scraping techniques. Aside from anti-scraping challenges, there are other barriers that limit and disrupt web scraping activities, including CAPTCHAs, dynamic content, honeypot traps, etc.
To help you overcome such challenges, this article highlights the top 7 web scraping best practices.
1. Continously parse & verify extracted data
Parsed data needs to be continuously verified to ensure that crawling is working correctly.
Data parsing is the process of converting data from one format to another, such as from HTML into JSON, CSV, or any other desired format. You need to parse data after extracting it from web sources. This makes it easier for data scientists and developers to analyze and work with the collected data.
Once you collect data from multiple websites, the data will likely be in different formats, such as semi-structured or unstructured, which is impossible to read and understand. A data parsing tool crawls text sources and builds a data structure using predefined rules. Parsing scraped data is a necessary step for further analysis in order to extract value from it.
Data parsing can be left to the end of the crawl process but then users may fail to identify issues early on. We recommend automatically and at regular intervals manually verifying parsed data to ensure that the crawler and parser are working correctly. It would be disastrous to identify that you have scraped thousands of pages but the data is garbage. These problems take place when the source websites identify scraping bot traffic as unwanted traffic and serve misleading data to the bot.
2. Use rotating IPs & proxy servers to avoid request throttling
Websites use different anti-scraping techniques to manage web crawler traffic to their websites and protect themselves from malicious bot activity. Based on visitor activities and behaviors such as the number of pageviews, session duration, etc., web servers can easily distinguish bot traffic from human activities. For example, if you make multiple connection requests to the same website in a short period of time without changing your IP address, the website will label your activities as “non-human traffic” and block your IP address.
Proxy servers hide clients’ real IP addresses to prevent websites from revealing their identities. Based on their IP rotation, proxy servers are classified into two types: static and rotating. Rotating proxies, as opposed to static proxies such as datacenter and ISP proxies, constantly change clients’ IP addresses for each new request to the target website. Bot traffic originating from a single IP address is more likely to be detected and blocked by websites.
We recommend using rotating proxies, such as backconnect and residential proxies, in your web scraping projects to avoid being blocked by websites.
The table below shows a comparison of the leading rotating proxy service providers. To get an in-depth analysis, check out our article.
| Provider | Proxy types | Rotation options | Sticky sessions | Free trial | Starts from** | Cost/GB | Traffic/GB | PAYG/GB |
|---|---|---|---|---|---|---|---|---|
| Smartproxy | Residential Shared datacenter Mobile | Each request | Up to 30 minutes | 3-day | $12 | $6 | 2 | $8.50 |
| Bright Data | Residential ISP Mobile Datacenter | Flexible rotation* | Customizable | 7-day | $10 | $6.30 | 1 | $8.40 |
| Oxylabs | Residential ISP Mobile | Each request | Up to 5 hours | 7-day | $99 | $9 | 11 | $10 |
| Nimble | Residential | Each request | 7-day | $600 | $8 | N/A | ❌ | |
| IPRoyal | Residential | Flexible rotation | Up to 24 hours | For companies | $12 | $6 | 2 | $7 |
| NetNut | Residential Datacenter Mobile | Each request | N/A | 7-day | $300 | $15 | 20 | ❌ |
| Infatica | Residential Datacenter | Flexible rotation | Up to 30 minutes | 3-day trial for $1.99 | $96 | N/A | 8 | ❌ |
| SOAX | Residential ISP | Flexible rotation | Up to 24 hours | 3-day trial for $1.99 | $99 | $6.60 | 15 | ❌ |
3. Check out the website to see if it supports an API
APIs establish a data pipeline between clients and target websites in order to provide access to the content of the target website. You don’t have to worry about being blocked by the website since APIs provide authorized access to data. They are provided by the website you will extract data from. Therefore, you must first check out if an API is provided by the website.
There are free and paid web scraping APIs you can utilize to access and get data from websites. Google Maps API, for example, adjusts pricing based on requester usage and volume of requests. Collecting data from websites via APIs is legal as long as the scraper follows the website’s API guidelines. 1
4. Choose the right tool for your web scraping project
You can build your own web scraper or use a pre-built web scraping tool to extract data from web sources.
Building a custom web scraper
Python is one of the popular programming languages for building a web scraping bot. It is a good choice for beginners because it has a large and growing community, making it easier to solve problems. Python has a large number of web scraping libraries, including Selenium, Beautifulsoup, Scrapy, and others; you need to pick the most appropriate web scraping library for your project. The following are the basic five steps for creating your own web scraper in Python:
- Decide the website from which you want to extract data.
- Inspect the webpage source code to view the page elements and search for the data you want to extract.
- Write the code.
- Run the code to make a connection request to the target website.
- Store the extracted data in the desired format for further analysis.
You can customize your own web scraper based on your particular needs. Building a web scraper, on the other hand, takes time because it requires labor.
Recommendation: If you will extract data from well-protected websites or scrape multiple web pages, you must use a proxy server with your web scraper. Residential and ISP proxies would be ideal solutions to ensure web scraping security and circumvent IP ban issues.
IP addresses of residential and ISP proxies are provided by ISPs (Internet Service Providers) that belong to real people. They provide a higher level of anonymity compared to datacenter proxies.
To help you make an informed decision, we analyzed the top 10 residential proxy providers of 2023 in terms of performance, pricing, and features.
Using a pre-built web scraper
There are numerous open-source and low/no-code pre-built web scrapers available. You can extract data from multiple websites without writing a single line of code. These web scrapers can be integrated as browser extensions to make web scraping tasks easier. If you have limited coding skills, low/no-code web scrapers could be extremely useful for your tasks.
Recommendation: If security is your primary concern in your web scraping activities, you can use a VPN solution in your data extraction process to protect your real IP address and sensitive data. Both proxies and VPNs hide clients’ real IP addresses and assign a new IP address. VPNs, as opposed to proxy servers, encrypt all network traffic between clients and web servers.
5. Respect the ‘robots.txt’ file
A robots.txt file is a set of restrictions that websites use to tell web crawlers which content on their site is accessible. Websites use robots.txt files to manage crawler traffic to their websites and keep their web servers from becoming overloaded with connection requests.
Websites, for example, may add a robots.txt file to their web server to prevent visual content such as videos and images from appearing in Google search results. The source page can still be crawled by the Google bot, but the visual content is removed from search results. By specifying the type of bot as the user agent, you can provide specific instructions for specific bots.
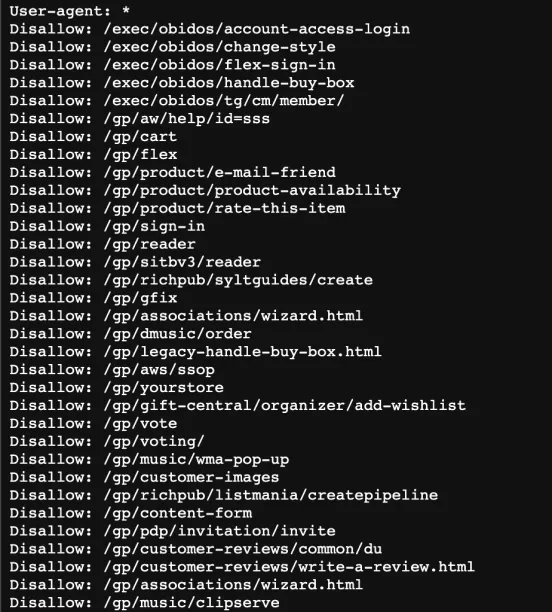
To understand a website’s instructions for web crawlers, view the robots.txt file by typing https://www.example.com/robots.txt (see Figure 1). In the image below, you can see the disallow commands determined by the website. A disallow command instructs a web crawler not to access a specific webpage. This means that your bot is not permitted to crawl the web page(s) specified in the disallow command.
Figure 1: The ‘robots.txt’ file for Amazon
6. Use a headless browser
A headless browser is a web browser without a user interface. All elements of a website, such as scripts, images, and videos, are rendered by regular web browsers. Headless browsers are not required to disable visual content and render all elements on the webpage.
Assume you want to retrieve data from a media-heavy website. A web browser-based scraper will load all visual content on the webpage. Scraping multiple web pages would be time-consuming with a regular web browser-based scraper. The visual content in the page source is not displayed by web scrapers using a headless browser. It scrapes the webpage without rendering the entire page. This speeds up the web scraping process and helps the scraper bypass bandwidth throttling.
7. Utilize antidetect browsers to avoid bot detection
Antidetect browsers allow users to mask their browser’s fingerprint, making it more difficult for websites to detect web scraping bots. However, it’s crucial to be mindful of the implications to perform data collection activities ethically and respectfully. They can automatically rotate user agents to mimic different devices and browsers, enabling bots to evade tracking and detection technologies employed by websites.
For instance, when you make a connection request to the target website, the target server obtains collects information sent by your device such as geolocation and IP address. If you are in restricted location, the server may block your IP address. Antidetect browsers help users change their digital fingerprint parameters, including IP address, operating system, and browser details. This makes it harder for websites to identify and track their activities.
8. Make your browser fingerprint less unique
When you browse the internet, websites track your activities and collect information about you using different browser fingerprinting techniques to provide more personalized content for your future visits.
When you request to view the content of a website, for example, your web browser forwards your request to the target website. The target web server has access to your digital fingerprint details, such as:
- IP address
- Browser type
- Operating system type
- Time cone
- Browser extensions
- User agent and screen dimensions.
If your target web server finds your behavior suspicious based on your fingerprints, it will block your IP address to prevent scraping activities. To avoid browser fingerprinting, use a proxy server or VPN. When you make a connection request to the target website, a VPN and proxy services will mask your real IP addresses to prevent your machine from being revealed.
For more on web scraping
- Top 5 Web Scraping Case Studies & Success Stories
- Web Scraping APIs: How-To, Capabilities & Top 10 Tools
- Web Scraping Tools: Data-driven Benchmarking
- The Ultimate Guide to Proxy Server Types
For guidance to choose the right tool, check out data-driven list of web scrapers, and reach out to us:
External Links

Next to Read
AI-Powered Web Scraping in 2024: Best Practices & Use Cases
Guide To Price Scraping: Best Tools & Legal Issues in 2024
Proxies for Web Scraping: Providers & Best Practices in 2024
Related research
Forward vs. Reverse Proxy: Benefits & Use Cases in 2024

Comments
Your email address will not be published. All fields are required.