Web scraping, extracting required data from web sources, is an essential tool, yet it is a technique fraught with challenges.
See below the most common web scraping challenges and practical solutions to address them.We cover everything from navigating web scraping ethics to overcoming technical barriers such as dynamic content and anti-scraping measures.
What are the major web scraping challenges?
There are many technical challenges that web scrapers face due to the barriers set by data owners or website owners to separate humans from bots and limit non-human access to their information. Web scraping challenges can be divided into two distinct categories:
1. Challenges arising from target websites:
- Dynamic content
- Website structure changes
- Anti-scraping techniques (CAPTCHA blockers, Robots.txt, IP blockers, Honeypots, and browser fingerprinting)
2. Challenges inherent to web scraping tools:
- Scalability
- Legal and ethical issues
- Infrastructure maintenance
1. Dynamic web content
Dynamic websites AJAX (asynchronous JavaScript and XML) to dynamically update the page’s content without requiring a full page reload. Many websites use dynamic content to display customized content based on users’ historical data and search queries. For instance, Netflix tracks users’ preferences and screen time in order to make personalized recommendations according to their behavior.
Dynamic content improves the user experience and loading speed but presents challenges for web scrapers which are programmed to scrape static HTML elements. Standard scraping tools that retrieve HTML don’t process JavaScript.
Certain types of dynamic content rely on user actions like clicks, scrolling, and logins, or on specific session states. Therefore, web scrapers must be capable of mimicking these user interactions while scraping such websites.
Solution: Consider using headless browsers such as Puppeteer, Selenium, or Playwright, which are well-suited for sites that depend on JavaScript and necessitate user interactions. Develop or obtain web scraping tools that can render content embedded within JavaScript components.
2. Website structure changes
Alterations to a website’s structure can be in its layout, design, or or underlying code of a website. Web crawlers are programmed to crawl a website based on its JavaScript and HTML elements which can be altered by the website designer to optimize the look and attractiveness of the website.
If changes happen to the HTML elements, even a minor change, data parser will no longer be able to extract accurate data, and will require adjustments to the code to match the new changes in the target website.
Data parsers are tailored to function with the initial layout of a web page. Alterations in this layout can hinder their capability to precisely identify and scrape the necessary data. To ensure the scraper remains functional, it’s essential for these parsers to be examined and modified by the developer to align with the updated page structure.
Solution: Utilize a specialized parser that is specifically designed for a specific target, and ensure it is adaptable, allowing for fine-tuning to effectively accommodate any changes as they occur.
3. Anti-scraping techniques
Many websites employ anti-scraping technologies to prevent or hinder data scraping activities. The following points provide an overview of some of the most common anti-bot measures encountered in the scraping process:
3.1 CAPTCHA blockers
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a type of website security measure created to identify bots and deny them access to websites. CAPTCHAs are mostly used to limit service registrations to humans and prevent ticket inflation.
However, they represent a challenge to good bots as well, such as Google bot which crawls documents from the web to build a searchable index for the Google Search engine, thus, has a negative impact on SEO practices.
Solution: To tackle this problem, web scrapers can implement a CAPTCHA solver to bypass the test and allow the bot access.
3.2 Robots.txt
In order to start crawling a website, users need to check the website’s robots.txt which provides or denies access to URLs and specific content on a website. Robots.txt files state whether the content is crawlable or not, and identify a crawl limit to avoid network congestions. A scraper bot will not be able to reach URLs or contents which are blocked by the robots.txt file.
Solution: Check if the website offers an API for accessing data or contact the data owner, provide them with legitimate reasons of why they need the data, and ask for permission to scrape websites.
3.3 IP blocking
Websites use IP-based blocking techniques (or IP bans) to prevent malicious access. The website identifies requests from specific IP addresses. If a web scraper is detected to scrape a website from the same IP address frequently, the website can block the IP and restrict its access to the data temporarily and permanently.
Solution: To tackle IP blocking measures, you can leverage rotating proxies or residential proxies. Integrate them to your web scraping tool to send access requests from a different IP address for every time.
Sponsored
Bright Data provides access to a vast network of 72 million residential IPs, both shared and dedicated, featuring targeting options at the level of city, ZIP Code, carrier, and ASN.
3.4 Honeypot traps
Honeypots are computer systems created to attract hackers and block them from accessing websites. A honeypot trap typically appears like a legitimate part of the website and contains data which an attacker may target. If a crawling bot tries to extract the content of a honeypot trap, it will go into an infinite loop of requests and fail to extract further data.
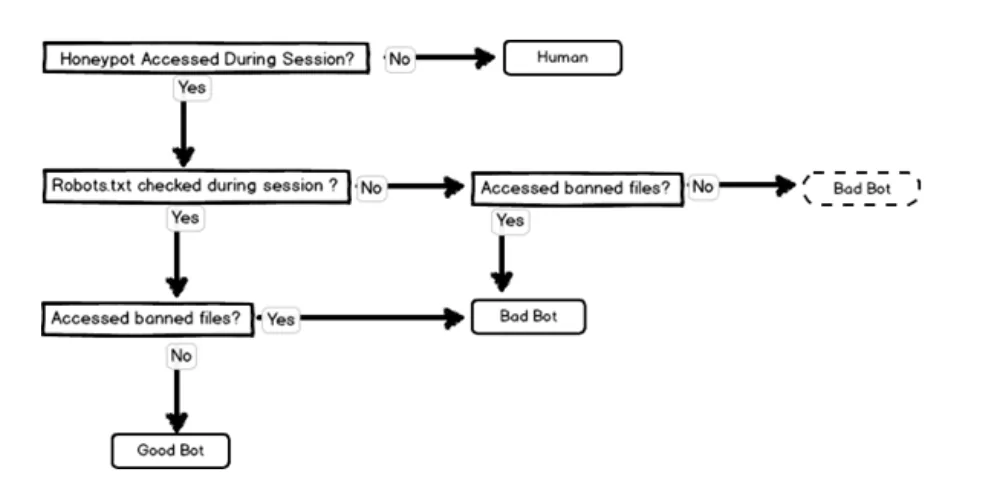
Solution: Check the CSS properties of each link or code elements that are set to display: none or visibility: hidden.
3.4 Browser fingerprinting
Browser fingerprinting is a method used by websites to gather information about their visitors through their IP addresses. Whenever you access a website, your device issues a request for connection to the site to load its content. This allows the website to retrieve and store data transmitted by your browser regarding your device.
Websites can accumulate extensive details about a user’s device, enabling them to customize suggestions for their visitors using browser fingerprinting. For instance, the target website can extract data about your user agents, HTTP header, language settings, and installed plugins.
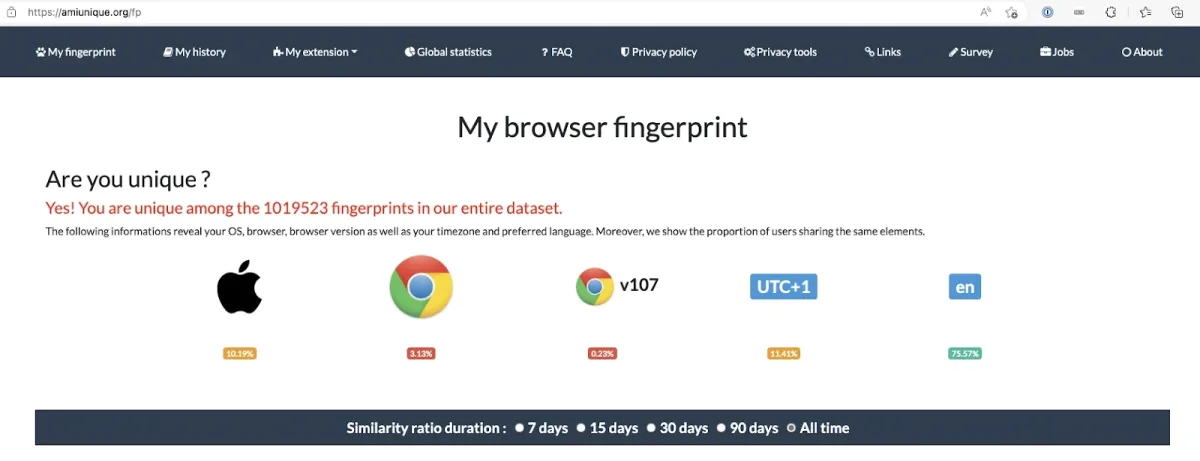
Source: AmIUnique
Solution: Anonymize or lower your browser uniqueness, or you you can use a shared proxies or a headless browser to acquire continuous data feeds.
4. Scalability
You might need to scrape a large amount of web data from multiple websites to gain insights into the pricing intelligence, market research and customer preferences. As the amount of data to be scraped increases, you need a highly scalable web scraper to make multiple parallel requests.
Solution: Utilize a web scraper designed to handle asynchronous requests to enhance scraping speed and gather large quantities of data more quickly.
5. Ethical and legal issues
Web scraping is not an illegal act itself if the extracted data is not used for unethical purposes. In many legal cases where businesses were using web crawlers to extract competition’s public data, judges did not find a legitimate reason to rule against the crawlers, even though crawling was frowned upon by the data’s owners.
For example, in the case of eBay vs. Bidder’s Edge, an auction data aggregator who used a proxy to crawl eBay’s data, the judge did not find Bidder’s Edge guilty of breaking federal hacking laws. 2
However, if using the scraped data causes either direct or indirect copyright infringement, then web scraping would be found illegal, such as in the case of Facebook vs. Power Ventures. 3
In short, web scraping and using web scraping software are not illegal, but they have been regulated in the past 10 years via privacy regulations which limit the crawl rate for a website, such as the General Data Protection Regulations (GDPR).
Solution: Check website Terms & conditions, and respect the ‘robots.txt’ file. To review a website’s instructions for web crawlers, view the robots.txt file by typing https://www.example.com/robots.txt.
6. Infrastructure maintenance
To maintain optimal server performance, it’s essential to regularly upgrade or expand resources such as storage to accommodate increasing data volumes and the complexities of web scraping. You must continuously update your web scraping infrastructure to keep pace with evolving demands.
Solution: When outsourcing your web scraping requirements, ensure the service provider offers built-in features such as a proxy rotator and data parser. Additionally, the provider should offer easy scalability options and regularly update their infrastructure to meet changing needs.
More on web scraping
Web scraping can be done manually, via training RPA bots to extract target data, or by outsourcing the crawling tasks to a service provider. To learn more, feel free to read our articles:
And if you want to invest in an off-the-shelf web scraping solution, check out our data-driven list of web scrapers.
And we can guide you through the process
External resources
- 1. Detection and Classification of Web Robots with Honeypots.
- 2. EBay v. Bidder's Edge - Wikipedia. Contributors to Wikimedia projects
- 3. Facebook, Inc. v. Power Ventures, Inc. - Wikipedia. Contributors to Wikimedia projects


Comments
Your email address will not be published. All fields are required.