We benchmarked top Twitter scrapers on 200 URLs (profile pages and posts), resulting in 400 requests. See the top scrapers and follow the links to see the rationale behind these choices:
| Provider | Focus | |
|---|---|---|
1. | Dedicated API for large-scale, low-cost, compliant data | |
2. | Generous free trial and high success rate | |
3. | Task automation, like posting tweets and automatically liking tweets | |
4. | ||
5. | ||





You can also see best practices for using Twitter (X) scrapers effectively while adhering to X.com’s policies and ethical data scraping practices.
Best Twitter Scrapers in 2025
| Vendors | Solution type | Page types | Formats | Pricing/mo | Free trial | PAYG |
|---|---|---|---|---|---|---|
| Bright Data | Dedicated API | Posts Profiles | JSON JSON Lines NDJSON CSV | $499 | 7 days | ✅ |
| Apify | Dedicated API | Posts Profiles | JSON HTML CSV | $49 | Unlimited | ✅ |
| NetNut | General-purpose API | N/A | N/A | Custom offering | 7 days | ❌ |
| PhantomBuster | No code dedicated scraper | Posts Profiles | JSON CSV | $59 | 14 days | ❌ |
| Octoparse | No code dedicated scraper | Posts Profiles | CSV Excel | $89 | 14 days | ❌ |
- Solution type: Detailed in the “how to scrape Twitter data” section.
- Page types: Certain providers offer pre-built scraper API templates tailored for various types of Twitter data, such as Twitter post Scraper API and Twitter profile Scraper API.
Scraper benchmark results
See which providers from the leading web data companies have scrapers for specific X.com pages:
| Provider | X.com post | X.com profile |
|---|---|---|
| Bright Data | ✅ | ✅ |
| Apify | ✅ | ✅ |
| Decodo | ❌ | ❌ |
| NetNut | ❌ | ❌ |
| Oxylabs | ❌ | ❌ |
| Zyte | ❌ | ❌ |
See the benchmark methodology for evaluating the best Twitter scraping tools.
Pricing for top Twitter scraping tools
Prices are monthly, disregarding annual discounts. The pricing chart only shows data for those with a success rate exceeding 50%. Providers are paid based on successful results.

Bright Data
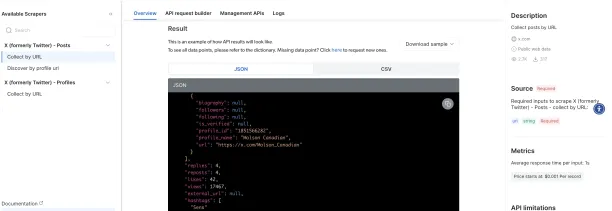
Bright Data provides three pre-built scraping templates for x.com: posts (collect by url), posts (collect by profile URL), and profiles (collect by URL). The provider gives snapshot list for each scraping project that returns metadata for each snapshot. You can Monitor the current state of data collection by its ID and cancel a running collection.
Due to website limitations, the scraper APIs can only get up to 100 posts per URL. The basic plan starts from $ 0.7 per 1000 records.

Apify
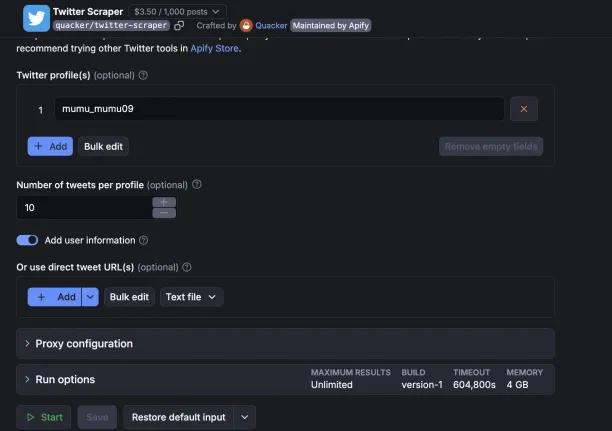
Apify’s Twitter scraper extracts publicly available Twitter information, including hashtags, threads, replies, images, and historical data. You can download the extracted data in any format. The tool allows users to scrape Twitter data either by a search term or URL input.
You can choose which proxies to use, including custom proxies and automatic proxies. You can either pick your proxy servers or use residential and datacenter proxies offered by the provider.

NetNut
NetNut offers a social media scraping API to extract live and on-demand data from sites such as LinkedIn. This social scraping solution supports proxy use and includes automatic proxy rotation to enhance data gathering efficiency.

Phantombuster
PhantomBuster offers a Twitter Follower Scraper that allows users to extract the follower information from a public Twitter profile. The scraper will enable users to scrape public follower information by a URL input.
You can scrape the URL of a single user account or a Google Sheet containing a list of Twitter account URLs. However, you cannot collect data using a keyword or hashtag as the input.

Octoparse
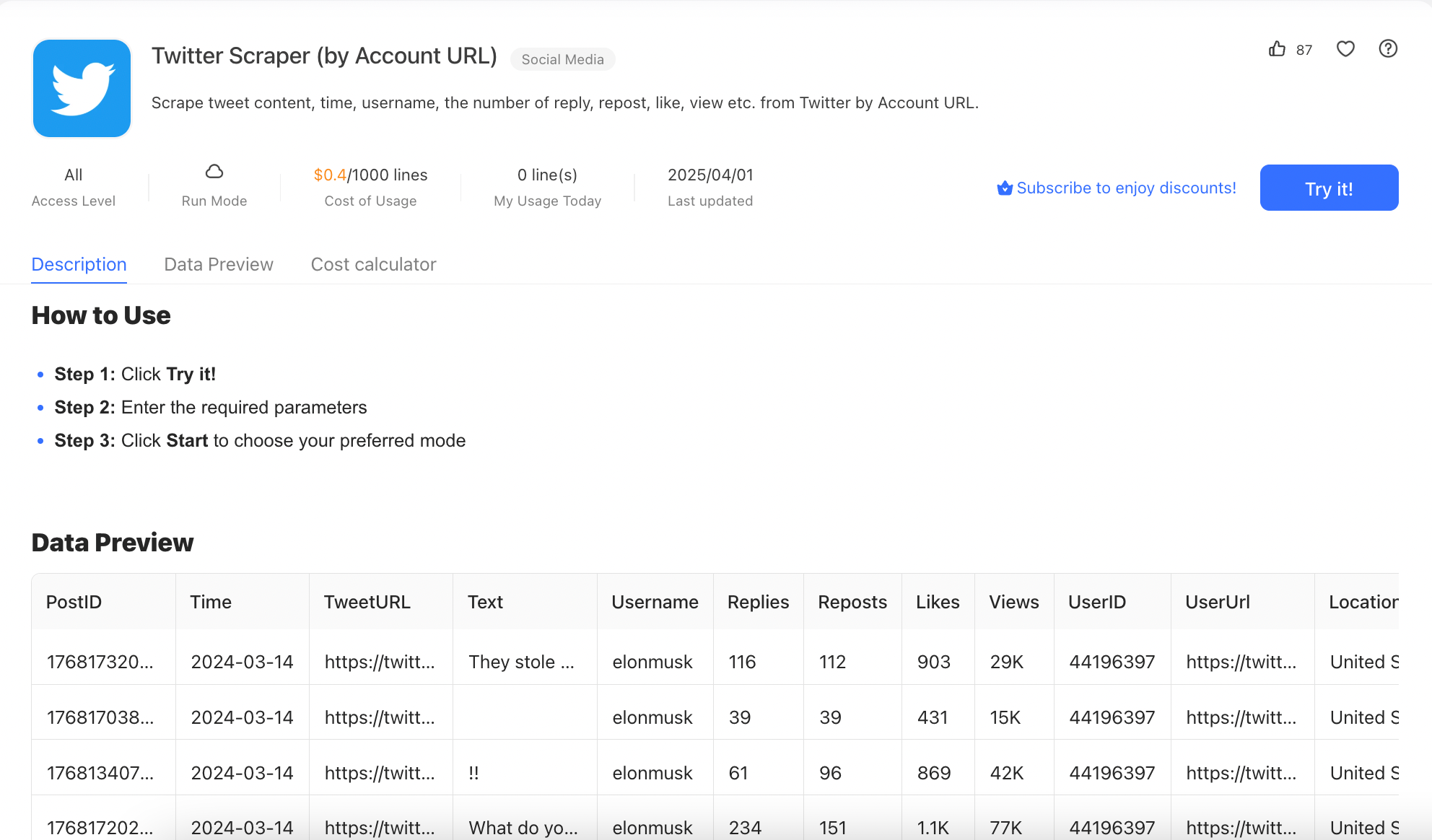
Octoparse’s social media scraper enables users to scrape data from social media platforms, including Twitter, Instagram, and TikTok. The scraper performs Twitter scraping on the cloud, saves the scraped Twitter data on the cloud rather than on the user’s local machine.
Benchmark methodology
We leveraged top web scraping API solutions to collect data from pre-selected URLs. Each provider processed each URL once, and the responses were recorded. Asynchronous methods were used for every API request.
The benchmark involved 200 URLs, including on 2 types of pages: profiles and posts. All providers are charged only for successful results.
- Bright Data and Apify returned JSON in all their responses from their dedicated Twitter APIs.
- However, Nimble offers a general-purpose API that returns
- Profiles as JSON ~60% of the time and HTML for the rest
- Posts as HTML
In our benchmark, we compared the leading dedicated Twitter scrapers (see the table below) based on their response times and pricing offerings for different request needs.
| Page type | Apify | Bright Data | Oxylabs | Decodo | Zyte |
|---|---|---|---|---|---|
| Twitter post | quacker/twitter-scraper | Twitter – Posts – collect by URL | ❌ | ❌ | ❌ |
| Twitter profile | quacker/twitter-scraper | Twitter – Posts – collect by URL | ❌ | ❌ | ❌ |
For more on methodology, please see social media scraping methodology.
What is a Twitter scraper?
A Twitter scraper is software that extracts data from Twitter. It enables users to collect various types of data associated with Twitter content and users, such as user profiles, hashtags, and tweets.
Which Twitter data can you scrape?
It is essential to respect Twitter’s Terms of Service and follow their guidelines when collecting their data. That being said, you may be able to extract the following types of data:
- Twitter profiles: Profile description, image, username, and follower/following counts.
- Tweets: Metadata associated with the content of a tweet, including likes, retweets, and replies.
- Hashtags: You can collect tweets containing specific hashtags.
- Twitter lists: List names, descriptions, and memberships.
How to scrape Twitter data
Twitter is one of the most difficult websites to scrape. Based on your goals, we recommend using:
- Web scraping APIs to scrape fewer than a few million pages/month.
- Proxies to crawl tens of millions of pages/month or send tweets or likes automatically.
- Web unblockers, if you need data points that are not returned by web scraping APIs.
- Twitter API if you need to post or like tweets and don’t have the technical capabilities to achieve this via proxies.
- Twitter datasets if you don’t need real-time data.
Web scraping APIs
Web scraping APIs minimize the technological effort on the client side by delivering structured data, making them a more cost-effective option than developing custom solutions.
Python Twitter scraper solutions take significant resources to manage proxy rotation, avoid CAPTCHA, and scale properly. If you’re building your web scraper to retrieve raw HTML, your technical team will need familiarity with proxy management to get beyond anti-scraping methods and HTML parsing. However, this strategy introduces the difficulty of regularly updating and re-parsing web pages as page designs change.
Third-party scraping APIs, on the other hand, return responses that vary in depth of detail. Before picking a provider, get sample API results for each type of page you want to scrape. By doing so, you can ensure that the API collects the necessary data from your target pages.
Begin by listing the page types you need to gather, such as profile pages, posts, or search results, and ensure that the API solution meets those requirements. Some web scraping service providers offer ready-to-use templates for popular websites (such as X.com), which you can alter as needed. Here are the main types of web scraper APIs:
1. Dedicated APIs
Some web scraping services provide specialized API solutions tailored to specific websites, making data extraction more efficient. Platforms like Bright Data and Apify offer dedicated APIs for scraping Twitter data, allowing for streamlined and reliable access to Twitter data.
2. General-purpose APIs
Many web scraper providers offer APIs that can be used across various websites. For instance, an eCommerce scraper API might extract data from platforms like Amazon, Walmart, or eBay. Similarly, social media scraper APIs can target multiple platforms, including Twitter, Instagram, TikTok, and LinkedIn.
3. No-code scraping tools
Platforms like Octoparse offer no-code scraping solutions, providing a marketplace of pre-built scrapers designed for specific websites like Twitter, TikTok, and Facebook. These tools provide point-and-click interfaces that let you select the data you want to scrape (Figure 1).
Figure 1: Showing how visual data selection works
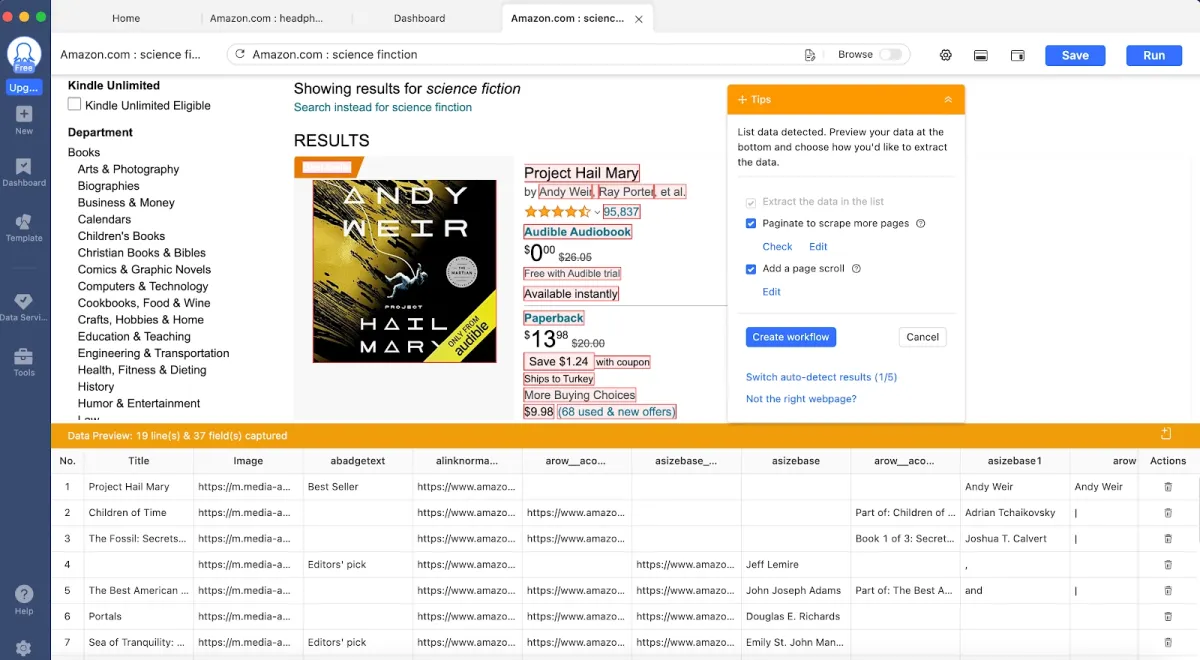
Source: Octoparse
Proxies
Proxies can be cost-effective at a high scale for Twitter scraping.
This is because the constant effort to keep your custom parser up-to-date gets distributed over many large-scale changes. For example, if you scrape more than ten million pages per month, choosing proxies and investing part of the savings in managing your custom Twitter parser can be cost-effective.
To promote its API, Twitter relies on anti-scraping features. Therefore, you should rely on rotating residential proxies and your team’s constant effort on proxy configuration to help you bypass restrictions and collect data.
Web unblockers
Unblockers return all of the data on the website in unstructured form. Therefore, you can rely on unblockers if you need data fields that web scraping APIs do not provide.
Some websites, such as X.com, are challenging to crawl because they deploy various anti-scraping techniques. In these circumstances, web unblockers are required to collect data consistently with high success rates.
Unblockers often achieve high success rates by utilizing complex technologies such as browser fingerprinting, JavaScript rendering, and scraping capabilities. These technologies assist in bypassing limitations and accessing restricted websites.
Twitter API
This API is more expensive (i.e., Pro level with read access starts at $5k/month) than other options.1
The most significant advantage of getting the Twitter API Key is that, since Twitter supports it, there is no risk of being blocked if you pull the data by following their API guidelines. However, the API has certain limitations regarding how far back in the past you can pull data and how many tweets you can pull in a minute. These rules can change year by year and should be double-checked directly from Twitter’s most up-to-date guidelines.
Free write-only API for developers
Twitter provides free API access for write-only use cases.2 You need to register your use case at the Twitter Developer website, and they will share your API key in a few days if your use case is confirmed.
Twitter datasets
Data sets are a great solution if you are okay with data that is updated frequently. Most web data providers provide data sets that can be queried.
However, if you need real-time data, you need to rely on one of the other options.


Comments
Your email address will not be published. All fields are required.