Deep learning is currently the most effective AI technology for numerous applications. However, there are still differing opinions on how capable deep learning can become. While deep learning researchers like Geoffrey Hinton believe that all problems could be solved with deep learning, there are numerous scientists who point to flaws in deep learning where remedies are not clear.1 2
With increasing interest in deep learning from the general public as well as developer and research communities, there could be breakthroughs in the field. Experts such as recent Turing prize winners expect such breakthroughs come from areas such as capsule networks, deep reinforcement learning and other approaches that complement deep learning’s current limitations. For detailed answers:
What is the level of interest in deep learning?
General public
Interest in deep learning is continuing to increase. Reasons of this interest include deep learning’s capacity to
- Improve accuracy of predictions, enabling improved data driven decisions
- Learn from unstructured and unlabelled datasets, enable analysis of unstructured data
As a result of these, deep learning solutions provide operational and financial benefits to companies. In 2012, later Turing award recipient George Hinton’s team demonstrated that deep learning could provide significant accuracy benefits in common AI tasks like image recognition. 3 4
After this, companies started investing in deep learning, and interest in the area exploded. Interest in deep learning has appeared stable since 2017.
Number of times a phrase is searched on a search engine is a proxy for its popularity. You can see the frequency with which “deep learning” was searched on Google below.
Research community
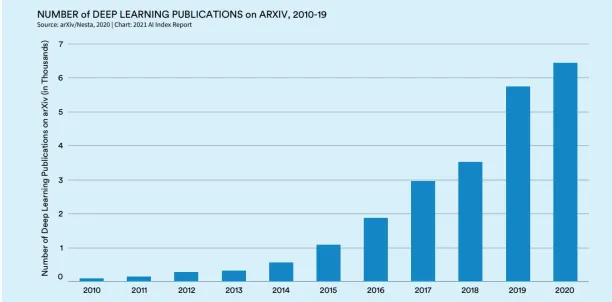
According to AI Index, which provides globally sourced data to develop AI applications, the number of deep learning publications on arXiv has increased almost sixfold in the last five years. ArXiv is an open-access platform for scientific articles in physics, mathematics, computer science, etc. It includes both peer-reviewed and non-peer-reviewed articles.
Developer community
TensorFlow and Keras are the most popular open source libraries for deep learning. Other popular libraries are PyTorch, Sckit-learn, BVL/caffe, MXNet and Microsoft Cognitive Toolkit (CNTK). These open source platforms help developers easily build deep learning models. As can be seen below, PyTorch, released by Facebook in 2016, is also rapidly growing in popularity.
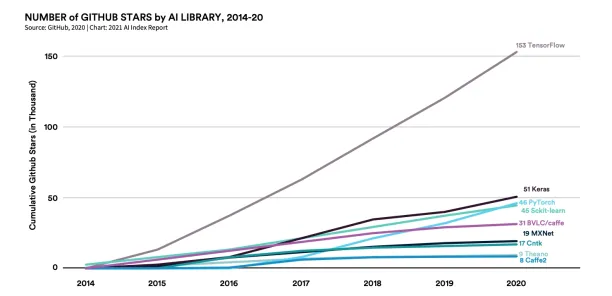
Open source libraries for deep learning are generally written in JavaScript, Python, C++ and Scala.
What are the technologies that can shape deep learning?
Deep learning is a rapidly growing domain in AI. Due to its challenges with the size and diversity of data, AI experts like Geoffrey Hinton, Yoshua Bengio, and Yann LeCun, who received the Turing prize for their work on deep learning, and Gary Marcus suggest new methods to improve deep learning solutions. 5
These methods include introducing reasoning or prior knowledge to deep learning, self-supervised learning, capsule networks, etc.
Introduction of non-learning-based AI approaches to deep learning
Gary Marcus, one of the pioneers in deep learning, highlights that deep learning techniques are data-hungry, shallow, brittle, and limited in their ability to generalize
- Gary Marcus states four possibilities for the future of deep learning:
- Unsupervised learning: If systems can determine their own objectives, and do reasoning and problem-solving at a more abstract level, great improvements could be achievedSymbol-manipulation & the need for hybrid models: Integration of deep learning with symbolic systems, which excel at inference and abstraction could provide better results
- More insight from cognitive and developmental psychology: Better understanding the innate machinery in humans minds, gaining common sense knowledge and human understanding of narrative could be valuable for developing learning models
- Bolder challenges: Generalized artificial intelligence could be multi-dimensional like natural intelligence to deal with the complexity of the world
- He proposes a four-step program:
- Hybrid neuro-symbolic architectures: Gary claims that we should embrace other AI approaches such as prior knowledge, reasoning, and rich cognitive models along with deep learning for transformational change
- Construction of rich, partly-innate cognitive frameworks and large-scale knowledge databases
- Tools for abstract reasoning for effective generalization
- Mechanisms for the representation and induction of cognitive models
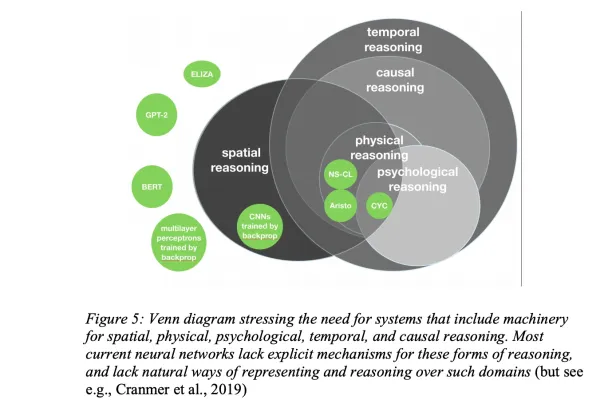
For more on Gary Marcus’ ideas, feel free to read his articles: Deep Learning: A Critical Appraisal from 2018 and The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence from 2020.6 7
Capsule networks
Capsule networks (CapsNets) are a new deep neural network architecture introduced by Geoffrey Hinton and his team in 2017. Capsules work with vectors and make calculations on the inputs. They encapsulate their results into a vector. So, when the orientation of the image is changed, the vector is moved.
Geoffrey Hinton thinks that CNNs’ approach to object recognition is very different from human perception. 8 CNNs need to be improved to deal with problems like rotation and scaling, and capsule networks can help generalize better in deep learning architecture.
Deep reinforcement learning algorithms
Deep reinforcement learning is a combination of reinforcement learning and deep learning. Reinforcement learning normally works on structured data. On the other hand, deep reinforcement learning makes decisions about optimizing an objective based on unstructured data.
Deep reinforcement learning models can learn to maximize cumulative reward. It is good for target optimization actions, such as complicated control problems. Yann LeCun thinks that reinforcement learning is good for simulations but it needs lots of trials and provides weak feedback. However, reinforcement learning models do not require large data sets compared to other supervised models.
Few-shot learning (FLS)
The advantage of few-shot learning (FSL), which is a subfield of machine learning, is being able to work with a small amount of training data. Few-shot learning algorithms are useful to handle data shortage and computational costs.
Few-shot learning models can be beneficial in healthcare to detect rare diseases with inadequate images in the training data. Few-shot learning models have the potential to strengthen deep learning models with new research and developments.
GAN-based data augmentation
Generative adversarial networks (GANs) are popular in data augmentation applications, and they can create meaningful new data by using unlabelled original data. They work in these steps:
- Deep learning models use GANs based data augmentation to generate synthetic data
- This synthetic data is used as training data
A study about insect pest classification shows that GAN-based augmentation method can help CNNs9
- perform better compared to classic augmentation method
- reduce data collection needs.
Self-Supervised learning
According to Yann LeCun, self-supervised learning models would be a key component of deep learning models. Understanding how people learn quickly could allow to utilize full potential of self-supervised learning and reduce deep learning’s reliance on large, annotated training data sets.
Self-supervised learning models can work without labeled data and make predictions if they have quality data and inputs of possible scenarios.
Other approaches
- Imitation learning: If there are few rewards in reinforcement learning models, imitation learning is used as an alternative method. The agent can learn performing a task by imitating supervisor’s demonstrations including observations and actions. It is also called as Learning from Demonstration or Apprenticeship Learning.
- Physics guided/informed machine learning: Physics laws are integrated into training process to induce interpretability and improve accuracy of predictions in deep learning models.10
- Transfer learning which is used to help machines transfer knowledge from one domain to another
- Others: Motor learning and brain areas like cortical and subcortical neural circuits may be new fields of inspiration for machine learning models.11 12
5 deep learning applications could make an impact in the future
1- Climate crisis
Deep learning models like GPTs can analyze business documents like invoices and utility bills to automatically generate detailed carbon footprint calculations. For example:
- Transportation data in invoices reveals fuel consumption and CO2 emissions.
- Electricity usage in utility bills highlights energy inefficiencies.
Such detailed calculations can drive more sustainable practices in addressing climate change.
Also, some deep learning models can predict renewable energy generation from wind and solar sources. These models can be utilized for climate forecasting and change prediction.13
2- Transportation
Tesla Tesla’s Autopilot and Full Self-Driving (FSD) system can be a good example to make the point.
They use deep learning algorithms to optimize driving behavior. This allows them to learn patterns and make decisions that reduce energy consumption. The key sustainability benefits include. Tesla’s Autopilot and FSD can adjust the car’s speed to maintain optimal battery efficiency and reduce energy consumption over long trips.
The cars also use real-time data to find the most energy-efficient routes, taking into account traffic, elevation changes, and other variables that impact energy use.
3-Agriculture
John Deere integrates deep learning models into its machinery, like tractors and harvesters. Here’s how deep learning is applied:
- Deep learning models analyze satellite and drone imagery to assess crop health, identify pests, and detect diseases early.
- Autonomous tractors and planters use deep learning to make real-time decisions on seed planting depth, spacing, and speed. This minimizes soil disruption.
- Deep learning models predict crop yields based on various factors like weather, soil conditions, and historical data.
4-Mining
Some companies use deep learning in autonomous haul trucks to optimize routes in mining operations. Reducing fuel consumption in mining process is one of the main goals. These trucks can operate 24/7 with minimal human oversight, making mining operations more energy-efficient and reducing their environmental impact.
5-Waste management
Companies like ZenRobotics use deep learning in robotic arms to sort and separate recyclables from waste. The AI system identifies and classifies different materials (plastics, metals, paper, etc.). This reduces the waste sent to landfills.
If you want to read more about deep learning, check our article on deep learning use cases.
If you are ready to use deep learning in your firm, we prepared a data driven list of companies offering deep learning platforms.
If you need help in choosing among deep learning vendors who can help you get started, let us know:
For more, you can watch 3 AI experts share their views during AAAI 20:
External Links
- 1. AI pioneer Geoff Hinton: “Deep learning is going to be able to do everything” | MIT Technology Review. MIT Technology Review
- 2. Why AI can’t solve everything.
- 3. 2018 Turing Award.
- 4. Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). “Imagenet classification with deep convolutional neural networks.” Communications of the ACM, 60(6), 84-90.
- 5. 2018 Turing Award.
- 6. [1801.00631] Deep Learning: A Critical Appraisal.
- 7. [2002.06177v1] The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence.
- 8. https://arxiv.org/pdf/1710.09829
- 9. ScienceDirect.
- 10. https://arxiv.org/pdf/2003.04919
- 11. Frontiers | Machine Learning Approaches for Motor Learning: A Short Review. Frontiers
- 12. The unreasonable effectiveness of deep learning in artificial intelligence | PNAS.
- 13. Achieving net zero emissions with machine learning: the challenge ahead | Nature Machine Intelligence. Nature Publishing Group UK


Comments
Your email address will not be published. All fields are required.