Model Retraining: Why & How to Retrain ML Models? [2024]
The business environment changes with numerous internal and external factors such as changes in the economic circumstances, customer habits and needs, or our way of life, for instance, with unexpected disasters like Covid-19.
As the business environment changes, companies need to adapt to new trends and developments. This includes adapting the ML models that are used in business decision-making as well since the predictive accuracy of deployed models also changes and degrades as incoming data changes. In other words, models need to be retrained to reflect the changes in their underlying environment.
In this article, we will explore what model retraining is and why you need to retrain your models.
What is model retraining?
Model retraining refers to updating a deployed machine learning model with new data. This can be done manually, or the process can be automated as part of the MLOps practices. Monitoring and automatically retraining an ML model is referred to as Continuous Training (CT) in MLOps. Model retraining enables the model in production to make the most accurate predictions with the most up-to-date data.
Model retraining does not change the parameters and variables used in the model. It adapts the model to the current data so that the existing parameters give healthier and up-to-date outputs. This enables businesses to efficiently monitor and continuously retrain their models for the most accurate predictions.
Why is model retraining necessary?
As the business environment and data change, the prediction accuracy of your ML models will begin to decrease compared to their performance during testing. This is called model drift and it refers to the degradation of ML model performance over time. Retraining is required to prevent drift and to ensure that models in production provide healthy results.
There are two main model drift types:
- Concept Drift occurs when the link between the input variables and the target variables changes over time. Since the description of what we want to predict changes, the model provides inaccurate predictions.
- Data Drift happens when the characteristics of the input data changes. The change in customer habits over time and the model’s inability to respond to change is an example.
Figure 1: Data Drift
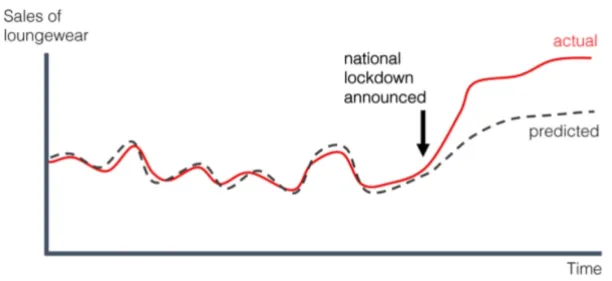
What should be retrained?
How much data will be retrained is a critical issue. If a concept drift has occurred and the old dataset does not reflect the new environment, it is better to replace the entire dataset. This is called batch or offline learning.
However, retraining the model with an entirely new dataset can be costly and often unnecessary if there’s no concept drift in your model. If there’s a constant stream of new training data, you can leverage online learning which involves continuously retraining the model by setting a time window that includes new data and excludes old data. For instance, you can periodically retrain your model with the latest dataset that covers the last 12 months.
When should the models be retrained?
Depending on the business use case, approaches for retraining a model include:
- Periodic retraining: In this approach, the model is retrained at a time interval you specify. Periodic retraining is useful when underlying data changes within measurable time intervals. However, frequent retraining can be computationally costly so determining the correct time interval is important.
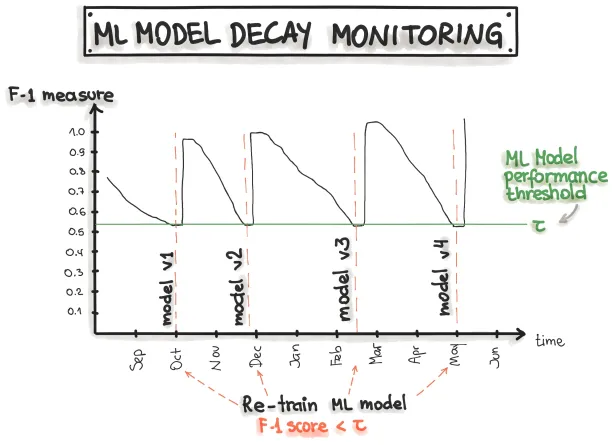
- Trigger-based retraining: This method involves determining performance thresholds. Models can be retrained automatically when the model’s performance drops below this threshold (Figure 2).
Figure 2: Triggering retraining at the threshold
To read more about the entire ML model pipeline and MLOps lifecycle and to be informed about MLOps solutions related to your business, you can check our data-driven list of MLOps platforms. If you have any other questions, please don’t hesitate to contact us:

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow on
Comments
Your email address will not be published. All fields are required.