Model Deployment: 3 Steps & Top Tools in 2024

Cem is the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per Similarweb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Developing a machine learning (ML) model is only a small part of a complete product that provides practical benefits for businesses. Model deployment is one of the last steps of the machine learning lifecycle and it refers to the process of bringing your model to real use where it can add value to your organization. Nonetheless, deploying machine learning models into a production environment has its own challenges. According to a survey by McKinsey, only 36% of companies were able to deploy an ML model beyond the pilot stage.
In this article, we’ll explore 3 steps to efficiently deploy your machine learning models beyond pilots.
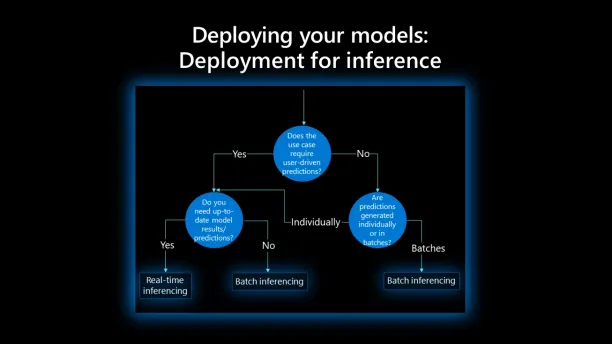
1. Determine the deployment method
The first question you should ask is how you should deploy your ML model into production. There are two common ways to deploy ML models:
Batch inference
Batch inference runs periodically and provides results for the batch of new data generated since the previous run. Batch inference generates answers with some latency so it is useful when there is no need to get model results in real-time. The advantage of batch inference is that since there is no latency constraint, you can deploy more complex models that can provide more accurate results.
For instance, a financial institution can deploy a credit scoring model with batch inference that runs once a day because there’s no need to update scores in real-time. The algorithm would provide credit score predictions of customers based on new data since yesterday.
Online inference
In online inference, also called real-time inference, the model is available 24/7 and provides results in real-time and on-demand, often through an API endpoint.
This sounds like a desirable feature in most cases, but the latency constraint limits the options for which type of ML model you can deploy. Since it should provide results in real-time to end users, you cannot use complex models with online inference. Moreover, it is more computationally demanding since the model should be ready to run at any time.
Consider a food delivery app that provides a delivery time estimation for each order. Since there is no way to know which customer would order food from which restaurant in advance, the ML model should be deployed with the online inference method, providing results in real-time.
To determine which method you should choose, you must answer the following questions:
- How often do you need model predictions?
- Should model results be based on individual cases or a batch of data?
- How much computational power can you allocate to the model?
2. Automate the deployment pipeline and testing workflows
You may be able to manage a single small model manually, but you should automate the data, code, and model pipelines for a successful model deployment at scale. Automation will enable you to:
- Manage the individual components of the lifecycle of your model, from development to validation and deployment, with minimal manual intervention
- Ensure that your deployed model will be trained with high-quality datasets consistently and automatically
- Test model performance, data quality, and pipeline architecture automatically to ensure robustness
- Scale your model without increasing your teams’ workload
To efficiently automate the ML model deployment process, data scientists should benefit from MLOps practices that are inspired from DevOps, such as continuous integration, continuous delivery, and continuous testing. For more on MLOps and how it can help you to streamline ML model construction and deployment, check our article on the topic.
3. Monitor your model after deployment
A successful deployment process doesn’t end with getting a functioning model in a live setting. You should continuously monitor the performance of your model because it is expected to degrade over time. This is called model drift. Drift happens because the environment where the data comes from changes and the accuracy of your model substantially depends on the quality of the data it trains with.
A good example is financial fraud. Since fraud techniques are constantly changing, an ML model trained on data from a couple of years ago can be ineffective to predict fraudulent transactions now.
You should set metrics and get alerted on changes in model performance and data distribution to efficiently monitor and mitigate model drifts. In case of drift, you should retrain your model with fresh data.
You should also monitor your deployment pipeline and perform debugging when necessary.
Tools for model deployment
Some open-source tools and Python libraries for model deployment are:
There are also MLOps platforms that provide tools for end-to-end ML model lifecycle management. You can check our article on MLOps tools to get started.
If you have other questions about machine learning model deployment or model development, we can help:

Cem is the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per Similarweb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised enterprises on their technology decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
Sources:
AIMultiple.com Traffic Analytics, Ranking & Audience, Similarweb.
Why Microsoft, IBM, and Google Are Ramping up Efforts on AI Ethics, Business Insider.
Microsoft invests $1 billion in OpenAI to pursue artificial intelligence that’s smarter than we are, Washington Post.
Data management barriers to AI success, Deloitte.
Empowering AI Leadership: AI C-Suite Toolkit, World Economic Forum.
Science, Research and Innovation Performance of the EU, European Commission.
Public-sector digitization: The trillion-dollar challenge, McKinsey & Company.
Hypatos gets $11.8M for a deep learning approach to document processing, TechCrunch.
We got an exclusive look at the pitch deck AI startup Hypatos used to raise $11 million, Business Insider.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow on

Comments
Your email address will not be published. All fields are required.