Machine Learning Operations (MLOps) brings DevOps principles into machine learning to simplify workflows from model development to deployment and maintenance.
Explore the landscape of MLOps tools for different components of the ML lifecycle, such as:
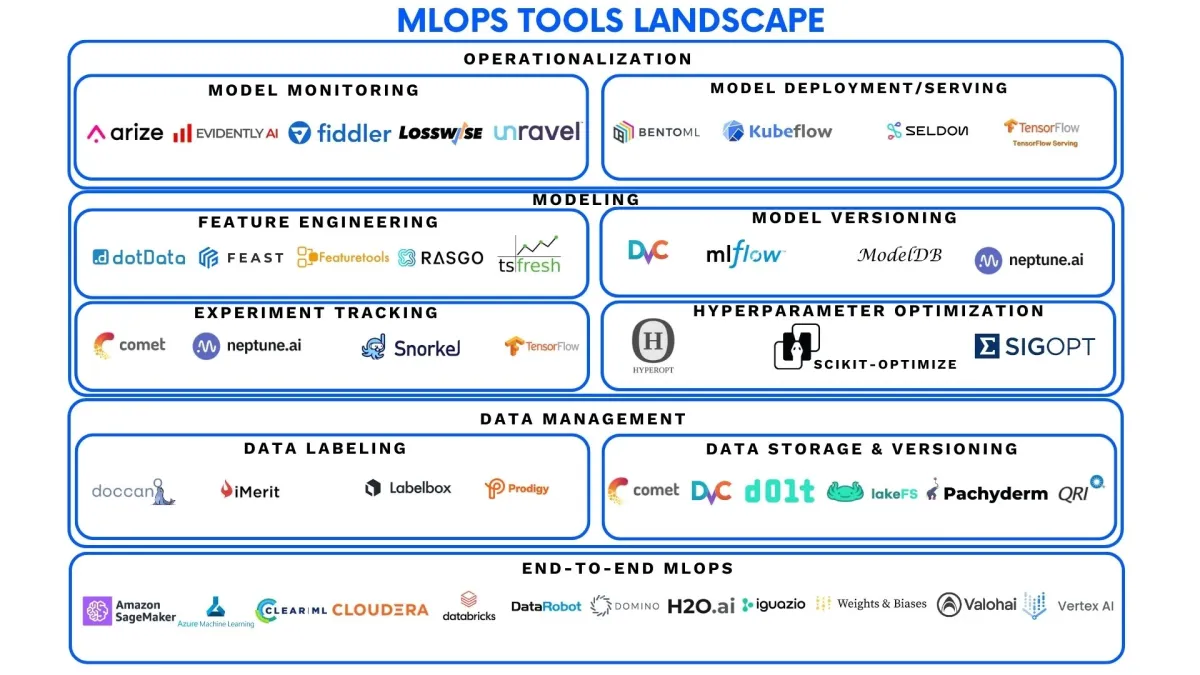
What are the types of MLOps solution providers?
Open source MLOps
Half of IT organizations use open-source tools for AI and ML and the figure is expected to be around two-thirds in 2023. On GitHub alone, there are 65 million developers and 3 million organizations contributing to 200 million projects.
Therefore, it is no surprise that there are advanced open-source toolkits in AI and ML landscape. Open-source tools concentrate on specific tasks within MLOps rather than providing end-to-end machine learning lifecycle management. These tools and platforms typically require a development environment in Python and R.
Startups that offer MLOps
Like open-source tools, most startups in the MLOps landscape provide tools for specific tasks within MLOps. Unlike open-source, startups tend to offer tools that target non-technical users.
Tech Giants that deliver MLOps
There are open-source tools developed by tech giants that address specific use cases in MLOps practices. However, the end-to-end MLOps solutions (or MLOps platforms) landscape is dominated by tech giants such as Google, Microsoft, or Alibaba.
What are the different types of MLOps tools?
MLOps tools typically fall into three categories:
- Data management
- Modeling
- Operationalization
There are also tools that can be considered as “MLOps platforms”, providing end-to-end machine learning lifecycle management.
We’ll explore tools for individual tasks within the major areas and MLOps platforms in turn.
Major data management solutions
Top data labeling tools
Data labeling tools (also called data annotation, tagging, or classification tools) are used to label large volumes of data such as texts, images, or audio. Labeled data is then used to train supervised machine learning algorithms in order to make predictions about new, unlabeled data. Some examples of data labeling tools include:
| Name | Status | Launched In |
|---|---|---|
| Doccano | Open Source | 2019 |
| iMerit | Private | 2012 |
| Labelbox | Private | 2017 |
| Prodigy | Private | 2017 |
| Segments.ai | Private | 2020 |
| Snorkel | Private | 2019 |
| Supervisely | Private | 2017 |
For more, check our article on how to choose a data labeling vendor. Also, don’t forget to check our data annotation services list.
Top data versioning
Data versioning (also called data version control) tools enable managing different versions of datasets and storing them in an accessible and well-organized way. This allows data science teams to gain insights such as identifying how data changes impact model performance and understanding how datasets are evolving.
Some popular data versioning tools are:
| Name | Status | Launched In |
|---|---|---|
| Comet | Private | 2017 |
| Data Version Control (DVC) | Open Source | 2017 |
| Delta Lake | Open Source | 2019 |
| Dolt | Open Source | 2020 |
| LakeFS | Open Source | 2020 |
| Pachyderm | Private | 2014 |
| Qri | Open Source | 2018 |
| Weights & Biases | Private | 2018 |
Modeling solutions
Top feature engineering tools
Feature engineering tools automate the process of extracting useful features from raw datasets to create better training data for machine learning models. These tools can accelerate the process of feature engineering for common applications and generic problems. However, it may be necessary to improve machine-generated feature engineering results using domain knowledge. Some feature engineering tools include:
| Name | Status | Launched In |
|---|---|---|
| AutoFeat | Open Source | 2019 |
| dotData | Private | 2018 |
| Feast | Open Source | 2019 |
| Featuretools | Open Source | 2017 |
| Rasgo | Private | 2020 |
| TSFresh | Open Source | 2016 |
Top experiment tracking tools
Developing machine learning projects involves running multiple experiments with different models, model parameters, or training data. Experiment tracking tools save all the necessary information about different experiments during model training. This allows tracking the versions of experiment components and the results and allows comparison between different experiments. Some examples of experiment tracking tools are:
| Name | Status | Launched In |
|---|---|---|
| Comet | Private | 2017 |
| Guild AI | Open Source | 2019 |
| ModelDB | Open Source | 2020 |
| Neptune.ai | Private | 2017 |
| TensorBoard | Open Source | 2017 |
| Weights & Biases | Private | 2018 |
| MLFlow Tracking | Open Source | 2018 |
Top hyperparameter optimization tools
Hyperparameters are the parameters of the machine learning models such as the size of a neural network or types of regularization that model developers can adjust to achieve different results. Hyperparameter tuning or optimization tools automate the process of searching and selecting hyperparameters that give optimal performance for machine learning models. Popular hyperparameter tuning tools include:
| Name | Status | Launched In |
|---|---|---|
| Google Vizier | Public | 2017 |
| Hyperopt | Open Source | 2013 |
| Optuna | Open Source | 2018 |
| Scikit-Optimize | Open Source | 2016 |
| SigOpt | Public | 2014 |
| Talos | Open Source | 2018 |
Top model versioning tools
Model versioning tools help data scientists manage different versions of ML models. Information such as model configuration, provenance data, hyperparameters, validation loss scores, and other metadata is stored in an easily accessible model registry. This metadata store helps data scientists quickly identify the configuration they used to build a particular model, ensuring that they don’t inadvertently use an incorrect or outdated model.
Model versioning systems also have mechanisms for capturing model outputs during training, providing a snapshot of how well a given model performed for each iteration. Versioning helps promote reproducibility, ensuring that published results can be verified in future iterations or investigations.
Some tools that enable model versioning are:
| Name | Status | Launched In |
|---|---|---|
| Data Version Control (DVC) | Open Source | 2017 |
| Neptune.ai | Private | 2017 |
| MLFlow | Open Source | 2018 |
| ModelDB | Open Source | 2020 |
| ML Metadata (MLMD) | Open Source | 2021 |
Operationalization solutions
Top model deployment / serving tools
Machine learning model deployment tools facilitate integrating ML models into a production environment to make predictions. Some tools in this category are:
| Name | Status | Launched In |
|---|---|---|
| Algorithmia | Private | 2014 |
| BentoML | Open Source | 2019 |
| Kubeflow | Open Source | 2018 |
| Seldon | Private | 2020 |
| TensorFlow Serving | Open Source | 2016 |
| Torch Serve | Open Source | 2020 |
Top model monitoring
Machine learning model monitoring is crucial for the success of ML projects, as model performance can decay over time due to changes in input data. Monitoring tools detect data and model drifts, or other anomalies, in real-time and trigger alerts based on performance metrics. This allows data scientists and ML engineers to take action, such as model retraining, to maintain its effectiveness.
Model monitoring tools include:
| Name | Status | Launched In |
|---|---|---|
| Arize | Private | 2020 |
| Evidently AI | Open Source | 2020 |
| Fiddler | Private | 2018 |
| Losswise | Private | 2018 |
| Superwise.ai | Private | 2019 |
| Unravel Data | Private | 2013 |
Shortlisted MLOps platforms
As mentioned above, there are also tools that cover the machine learning lifecycle end-to-end. These platforms are often provided by startups or tech giants but there’re also open-source platforms. Popular MLOps platforms include:
| Name | Status | Launched In |
|---|---|---|
| Alibaba Cloud ML Platform for AI | Public | 2018 |
| Amazon SageMaker | Public | 2017 |
| Cloudera | Public | 2020 |
| Databricks | Private | 2015 |
| DataRobot | Private | 2019 |
| Google Cloud Platform | Public | 2008 |
| H2O.ai | Open Source | 2012 |
| Iguazio | Private | 2014 |
| Microsoft Azure | Public | 2010 |
| MLFlow | Open Source | 2018 |
| OpenML | Open Source | 2016 |
| Polyaxon | Private | 2018 |
| Valohai | Private | 2016 |
Explore leading MLOps platforms in our curated, data-backed selection to find the best fit for your ML needs.
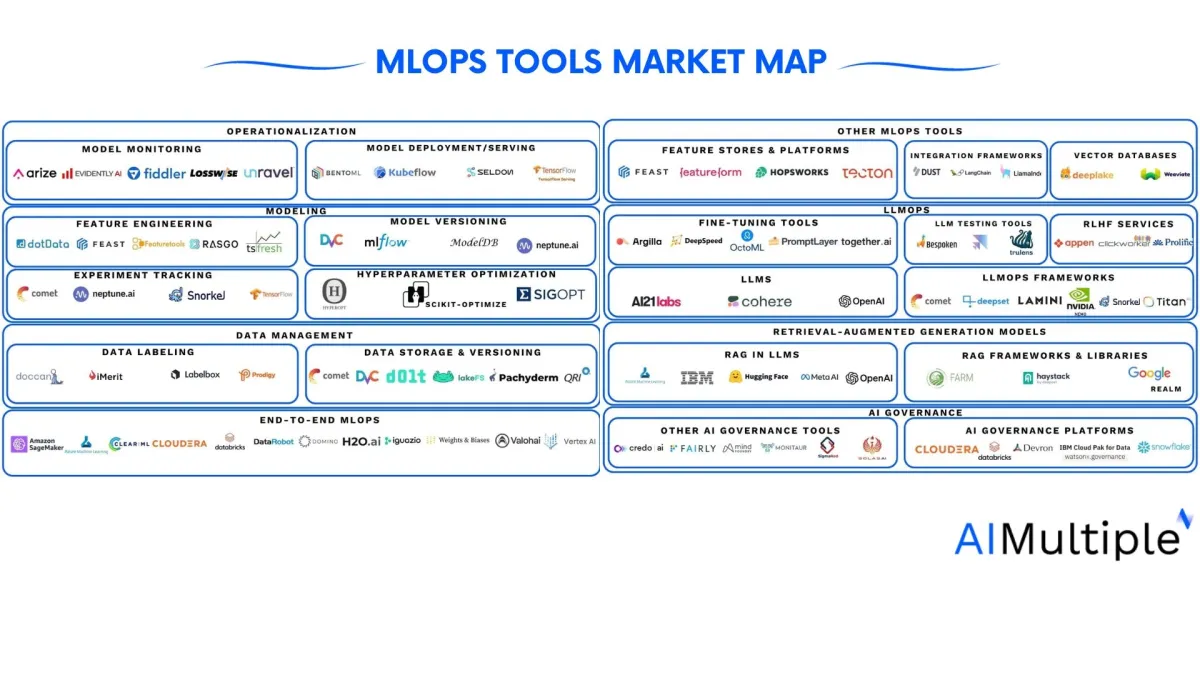
Other categories related to MLOps
MLOps assistant tools
These tools are used to assist MLOps and LLMOps developers in specific aspects of MLOps and LLMOps deployment. These tools include:
- Feature stores:Feature stores serve as a centralized hub for storing, managing, and delivering ML features. They facilitate the discovery and sharing of feature values, supporting both model training and serving. Key features include the ability to create feature engineering pipelines, efficient feature serving, scalability, versioning, validation, metadata management, and integration with ML workflows for reproducibility.
- Integration frameworks: These frameworks help developing LLM applications such as document analyzers, code analyzers, chatbots etc.
- Vector databases (VD): Vector databases store complex, multi-dimensional data like patient records that combine symptoms, lab results, and behavioral patterns. VDs can search and retrieval unstructured data (like images, video, text, and audio) by content rather than labels or tags. VDs can help with model versioning and management in MLOps and LLMOps.
LLMOps
Large Language Models Operations is a specialized subset of machine learning operations (MLOps) tailored for the efficient development and deployment of Large Language Models (LLMs).
LLMOps ensures that the model quality remains high and that the data quality maintained throughout data science projects by providing infrastructure and tools.
LLMOps encompasses platforms and utilities for managing LLMs—from fine-tuning and evaluation to deployment and monitoring. Explore more on other LLMOps tools by checking out our data-driven market guide.
AI governance
AI governance establishes the frameworks and policies that shape how AI technologies are developed, deployed, and regulated. The key aim is to promote ethical AI practices and societal benefit while reducing risks like bias and unintended consequences.
AI governance is a crucial aspect of ML projects, which is why end-to-end MLOPs platforms offer AI governance capabilities. Discover other AI governance tools by reading our comprehensive market guide.
FAQs
What is MLOps?
MLOps applies repeatable practices to make ML development, deployment, and monitoring more efficient and reliable.
If you still have questions about MLOps tools and vendors or artificial intelligence in general, we would like to help:


Comments
Your email address will not be published. All fields are required.