

Training AI systems to align with human values can be a challenge in machine learning. To mitigate this, developers are advancing AI through reinforcement learning (RL), allowing systems to learn from their actions. A notable trend in RL is Reinforcement Learning from Human Feedback (RLHF), which combines human insights with algorithms for efficient AI training.
Explore what RLHF is, its real-world applications, benefits, and challenges.
What is Reinforcement Learning from Human Feedback (RLHF)?
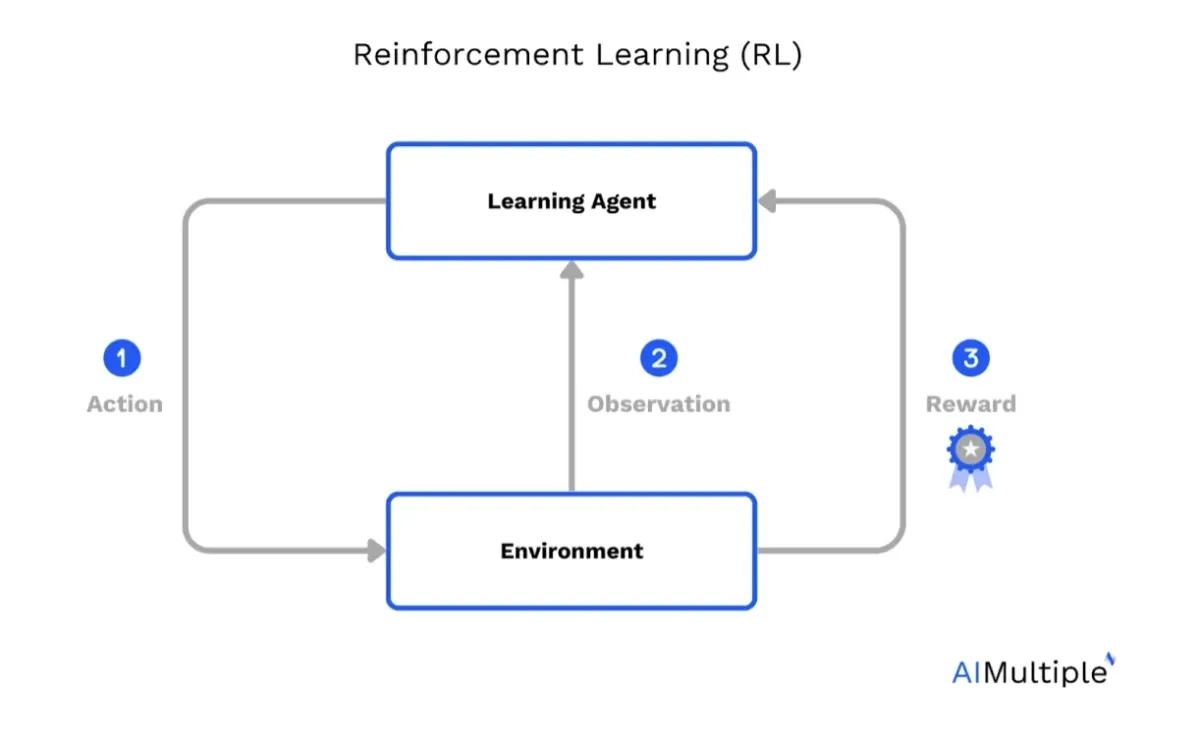
Figure 1: A basic reinforcement learning model.
Reinforcement Learning from Human Feedback (RLHF) is a machine learning approach that enables artificial intelligence (AI) models to align more closely with human values and preferences by incorporating human feedback during the training process.
This method combines elements of supervised learning, reinforcement learning, and human input to optimize the model’s output. RLHF is especially significant in improving large language models (LLMs) for tasks like natural language generation, dialogue agents, and other generative AI applications.
Understanding reinforcement learning and RLHF
Reinforcement learning (RL) is a learning process where an agent interacts with an environment, observes its current state (observation space), and selects actions to maximize a reward function. The reward function guides the agent toward achieving the desired objective function.
Coffee-making analogy to simplify the concept of RLHF
Imagine teaching a robot to make a cup of coffee. Using traditional RL, the robot would experiment and figure out the process through trial and error, potentially leading to many suboptimal cups or even some disasters.
With RLHF, a human can provide feedback, steering the robot away from mistakes and guiding it towards the correct sequence of actions, reducing the time and waste involved in the learning process. To visualize the concept, see the image below.
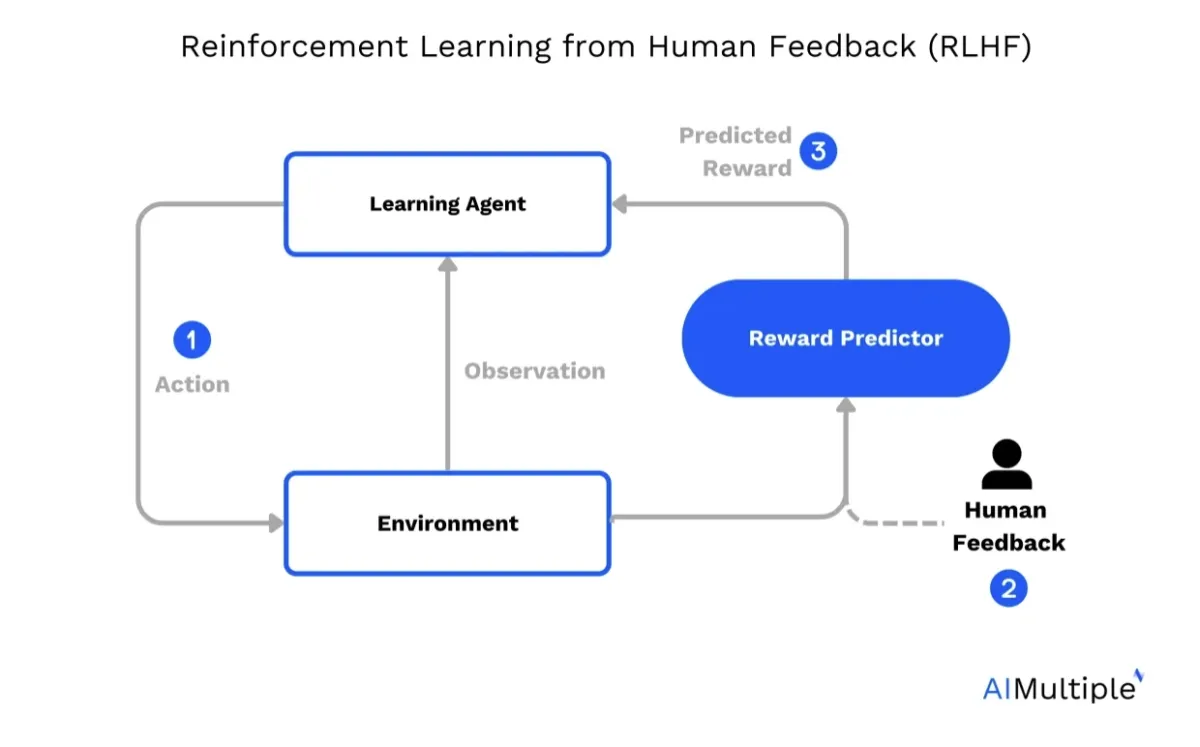
Figure 2: An RLHF model.
In RLHF, the reward function is augmented with human preferences, to enable the AI to learn behaviors that align with human goals. RLHF consists of the following key steps:
Pre-trained model and initial training: A base model or pre-trained model (e.g., a language model) is fine-tuned using supervised learning with human-provided training data to create an initial model. This step ensures that the AI can generate text and responses that are technically correct and relevant to the given prompt.
Collecting human feedback: Human annotators or human labelers provide human feedback by ranking different responses to the same prompt or annotating outputs to indicate alignment with human values and preferences. This creates human preference data, which forms the foundation of RLHF training.
Reward model: A reward model is trained using human preference data, ranking data, and human annotations. This model learns to predict the reward function based on how closely the model’s output matches human preferences. It is an essential component for training language models to optimize their behavior.
Reinforcement learning with human feedback: Using the reward model, the AI is further fine-tuned through reinforcement learning.
Policy gradient methods, which form the foundation of this phase, work by treating the AI model as a probabilistic policy that outputs responses based on a given input or prompt.
These methods compute the gradient of the expected reward (as predicted by the reward model) with respect to the model’s parameters, effectively measuring how a slight change in the model’s behavior would influence the expected quality of its outputs.
By following policy gradients, the model is iteratively updated to increase the likelihood of generating responses that receive higher rewards.
This direct optimization of the response distribution enables the AI to better learn and align with nuanced human preferences, even when those preferences are challenging to encode using traditional supervised learning methods.
Techniques like Proximal Policy Optimization (PPO) help optimize the model’s output to align with the reward function. This learning process enables the AI to generate responses that align better with human goals and preferences.
Imitation learning as a complementary approach
Imitation learning is a training method where AI models learn by replicating expert behavior. Rather than exploring an environment through trial and error, the model observes demonstrations of desired behavior and learns to imitate them. These demonstrations typically consist of input-action pairs recorded from a human or expert system.
While imitation learning alone can produce effective models, it can be combined with RLHF to improve performance and alignment with human expectations.
This hybrid approach leverages the strengths of both methods: imitation learning provides a foundation for competent behavior, and RLHF fine-tunes that behavior using human preference signals.
In practice, imitation learning is frequently used to initialize the model’s policy before reinforcement learning begins. This reduces the need for extensive random exploration, which can be inefficient or unsafe.
For example, in robotics or interactive AI systems, using demonstrations ensures the model begins with a reasonable understanding of the task. Reinforcement learning, guided by a reward model trained on human preferences, then refines the behavior to optimize for goals that go beyond mere replication.
This combination is particularly useful when demonstrations are available but not sufficient to capture all aspects of the desired behavior.
RLHF allows the model to adapt beyond what was shown by incorporating evaluative feedback on its outputs. As a result, the system can generalize better, avoid undesirable actions, and align more closely with nuanced human values.
Despite the benefits, combining imitation learning with RLHF introduces additional challenges, such as ensuring consistency between demonstration data and preference-based feedback.
However, when implemented effectively, the joint use of these techniques leads to more efficient learning and better-aligned AI behavior across a range of applications, including dialogue systems, robotics, and generative tasks.
How can RLHF enhance language models?
RLHF can improve the capabilities of dialogue agents and other generative AI systems by integrating human guidance and fine-tuning the model’s behavior. It ensures that the AI is both technically correct and sensitive to human values and natural language understanding.
Use cases of RLHF
This section highlights some ways you can use the RLHF approach.
1. Natural language processing (NLP)
RLHF has proved to be effective in diverse NLP domains, including crafting more contextually appropriate email responses, text summarization, conversation agents, and more. For instance, RLHF enables language models to generate more verbose responses, reject inappropriate queries, and align model outputs with complex human values.
One of the most popular examples of RLHF-trained language models is OpenAI’s ChatGPT and its predecessor, InstructGPT:
InstructGPT
InstructGPT, an earlier example of an RLHF-trained model, marked a significant improvement in aligning language model outputs with user instructions. It incorporated human feedback to refine the generation of outputs based on user-specified prompts. Key features included:
- Aligning outputs with specific instructions provided by users.
- Generating more accurate, clear, and context-sensitive responses.
- Reducing the likelihood of producing harmful or irrelevant content.
ChatGPT
Building upon InstructGPT, ChatGPT further refined the RLHF training process to enhance conversational capabilities. Its advancements include:
- Natural language understanding and generation: ChatGPT leverages RLHF to improve its ability to understand user inputs and generate coherent, human-like responses tailored to the context of the conversation.
- Proactive rejection of unsafe queries: ChatGPT uses human feedback to recognize and reject inappropriate or unsafe queries, to increase user safety.
- Interactive dialogue systems: By generating multiple responses for the same prompt and selecting the one that best matches human preferences, ChatGPT facilitates smoother and more engaging conversations.
- Handling complex queries: ChatGPT is designed to address complex prompts requiring advanced understanding, aligning its responses with human communication norms and preferences.
2. Education, business, healthcare, and entertainment
RLHF is applied to solving math problems, coding tasks, and other domains like education and healthcare.1
Mathematical tasks
RLHF enhances language models’ abilities to solve complex mathematical problems by learning from human feedback on reasoning processes and solutions.
This approach helps models generate step-by-step explanations, verify correctness, and avoid common errors, making them more effective for academic and research applications.
Coding tasks
RLHF improves AI’s performance in coding tasks by incorporating human feedback to refine outputs, debug errors, and adhere to best practices. It enables models to generate code snippets, aid in debugging, and clarify functionality, making them indispensable for software developers and learners alike.
Education
In education, RLHF-trained models act as personalized tutors, providing tailored explanations, answering questions, and generating learning materials. They align their responses with human communication norms and educational goals, offering students contextual and easy-to-understand assistance in various subjects.
Healthcare
RLHF ensures AI models can generate accurate, human-aligned responses for healthcare applications, such as patient education, medical record summarization, or symptom analysis.
By learning from human feedback, models can provide contextually sensitive and reliable information, supporting both healthcare providers and patients
3. Video game development
In the game-developing space, RLHF has been employed to develop bots with superior performance, often surpassing human players.
For example, agents trained by OpenAI and DeepMind to play Atari games based on human preferences showcased strong performance across various tested environments.2
4. Summarization tasks
RLHF has also been applied to train models for better text summarization, showing its potential in enhancing the quality of summarization AI models. This is done by using human feedback to guide the model’s learning process towards generating concise and informative summaries.
By iteratively adjusting the model based on human evaluations of generated summaries, RLHF facilitates a more human-aligned performance in summarization, ensuring the produced summaries are coherent, relevant, and adhere to a high standard of quality
5. Robotics
RLHF is increasingly applied in robotics to align robotic behavior with human preferences and expectations. By incorporating human feedback, robots can learn to perform complex tasks with greater precision, adaptability, and context awareness. Key applications include:
- Human-like behavior: RLHF enables robots to mimic human actions and decision-making processes, to increase their ability to interact naturally in human environments, such as homes, workplaces, or public spaces.
- Complex task assistance: Through iterative learning from human guidance, robots can master complex tasks like assembling components, assisting in surgeries, or handling fragile objects.
- Interactive learning: Robots can engage in playful or interactive scenarios to improve their understanding of human intent and preferences, such as learning via games or collaborative exercises.
- Personalization: RLHF allows robots to tailor their behavior to individual user needs, making them more effective in caregiving, education, and customer service roles.
Key advantages of RLHF
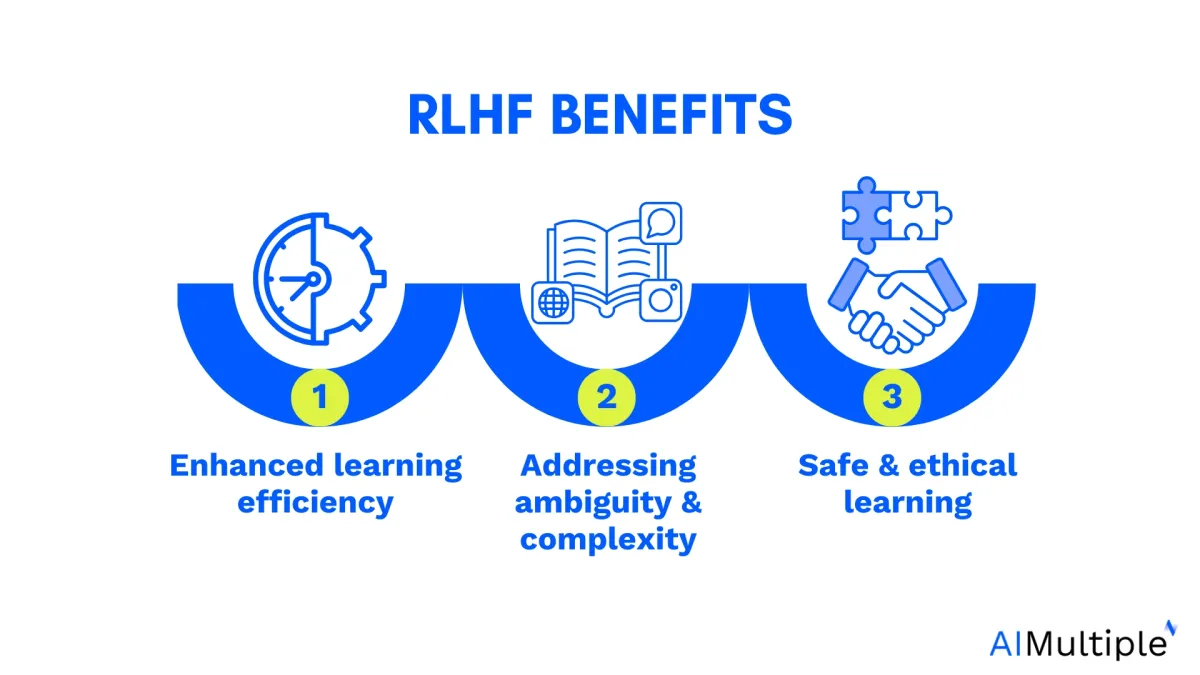
1. Enhancing learning efficiency
One of the primary benefits of RLHF is its potential to boost learning efficiency. By including human feedback, RL algorithms can sidestep the need for exhaustive trial-and-error processes, speeding up the learning curve and achieving optimal results faster.
2. Addressing ambiguity and complexity
RLHF can also handle ambiguous or complex situations more effectively. In conventional RL, defining an effective reward function for complex tasks can be quite challenging. RLHF, with its ability to incorporate nuanced human feedback, can navigate such situations more competently.
3. Safe and ethical learning
Lastly, RLHF provides an avenue for safer and more ethical AI development. Human feedback can help prevent AI from learning harmful or undesirable behaviors. The inclusion of a human in the loop can help ensure the ethical and safe operation of AI systems, something of paramount importance in today’s world.
Challenges and recommendations for RLHF
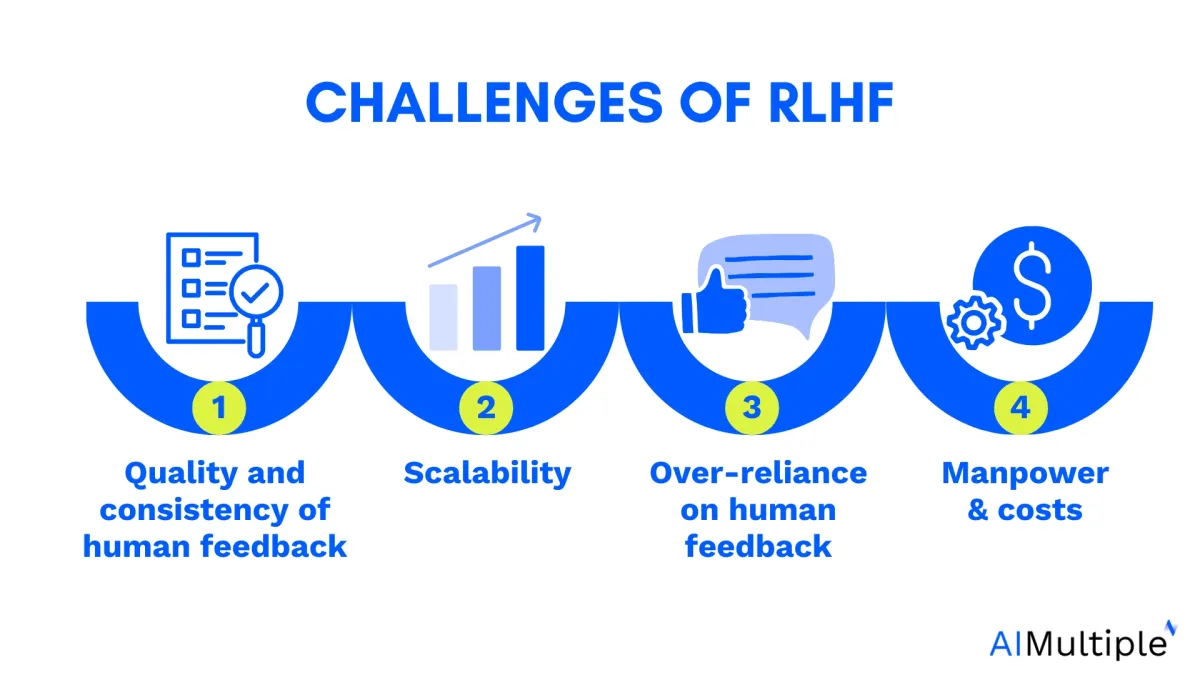
While RLHF holds promise, it also comes with its own set of challenges. However, with every challenge comes an opportunity for innovation and growth.
1. Quality and consistency of human feedback
The efficacy of RLHF heavily relies on the quality and consistency of the human feedback provided. Inconsistent or erroneous feedback can derail the learning process.
Recommendation
This challenge can be mitigated by incorporating multiple feedback sources or by using sophisticated feedback rating systems that gauge the reliability of the feedback providers. Working with an RLHF platform with a large network of contributors can also help, since then the tasks will be divided into many micro-tasks, and the quality can be assured much easily.
2. Scalability
As AI systems handle increasingly complex tasks, the amount of feedback needed for effective learning can grow exponentially, making it difficult to scale.
Recommendation
One way to address this issue is by combining RLHF with traditional RL. Initial stages of learning can use human feedback, while more advanced stages rely on pre-learned knowledge and exploration, reducing the need for constant human input. Outsourcing to a third-party service provider can help manage scalability.
3. Over-reliance on human feedback
There’s a risk that the AI system might become overly reliant on human feedback, limiting its ability to explore and learn autonomously.
Recommendation
A potential solution is to implement a decaying reliance on human feedback. As the AI system improves and becomes more competent, the reliance on human feedback should gradually decrease, allowing the system to learn independently.
4. Manpower and costs
The costs associated with RLHF includes:
- Recruiting experts to provide feedback
- The technology and infrastructure needed to implement RLHF
- Development of user-friendly interfaces for feedback provision
- Maintenance and updating of these systems
Recommendation
Working with an RLHF service provider can help streamline the process of using RLHF for training AI models.



Comments
Your email address will not be published. All fields are required.