Multimodal AI processes diverse data—audio, visual, and text—to deliver richer insights with greater accuracy. To maximize its value without overcommitting, businesses should assess their needs, data quality, and strategic goals.
There are two distinct areas where multimodal learning is applied: machine learning and education. If you’re interested in:
- Exploring the role of multimodal learning in machine learning, check out the technology of multimodal learning,
- Understanding the VARK model in education, check out multimodal learning in education.
What is multimodal learning?
The rise of affordable sensors has caused a rapid growth in visual data, enhancing many computer vision tasks. This data includes images and videos, which are essential for developing multimodal models.
Unlike static images, videos offer detailed insights by combining spatial and temporal information from successive frames, making them ideal for applications like video synthesis and facial expression recognition.
Spatiotemporal processing involves analyzing both the spatial and temporal dimensions of video sequences. In multimodal learning, audio, visual, and text features from videos are integrated to create unified representations. Efficiently handling large datasets across multiple levels speeds up the analysis and recognition of the vast number of videos produced daily.
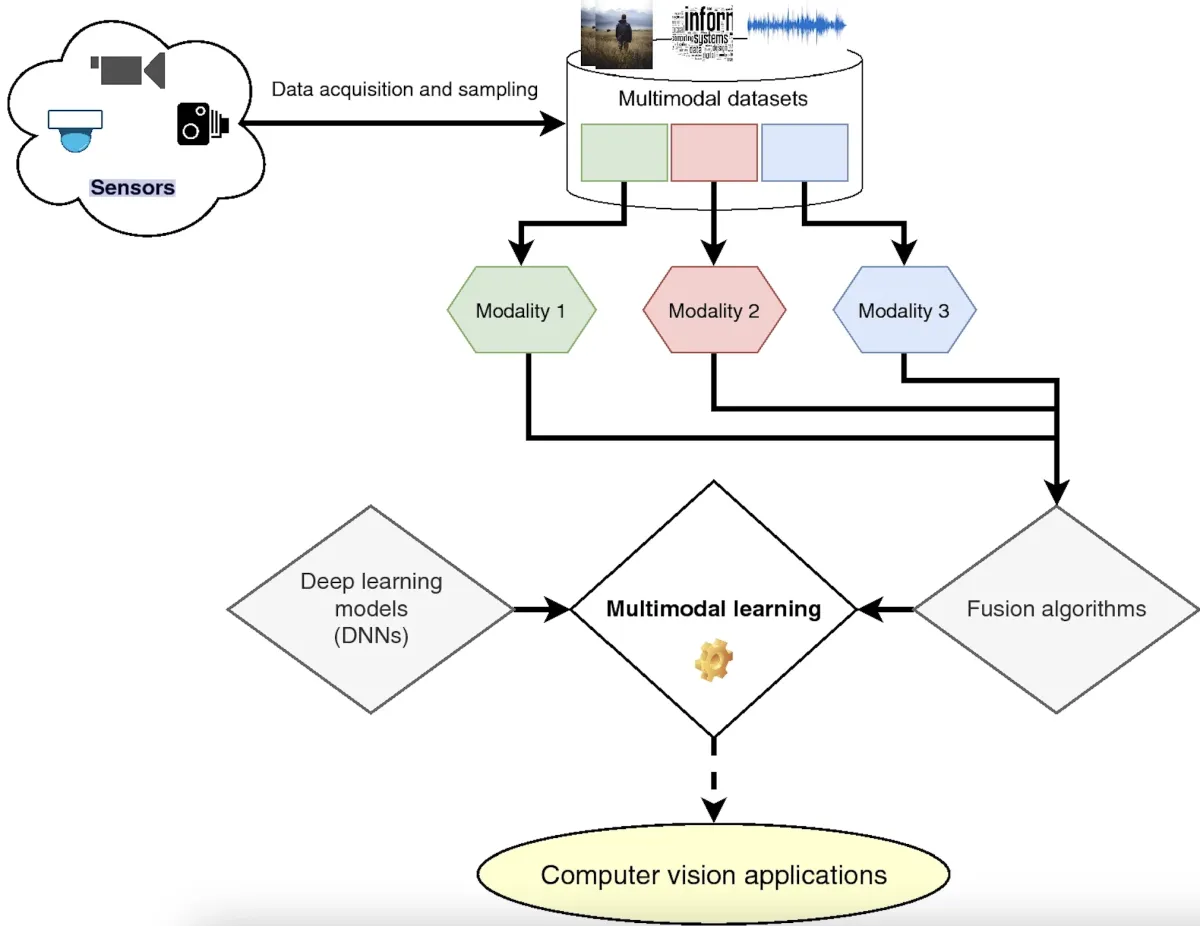
Figure 1: Multimodal model example with three modalities.1
How does Multimodal Learning compare to Unimodal AI?
All traditional AI models are unimodal since they are developed for and required to perform a single task. For instance, a facial recognition system provides a single input, such as an image of a person, that analyzes and compares with other images to find a match.
Doctors do not provide a full diagnosis until they have analyzed all available data, such as medical reports, patient symptoms, patient history, etc. Similarly, the output of an unimodal system fed with a single data type will be limited.
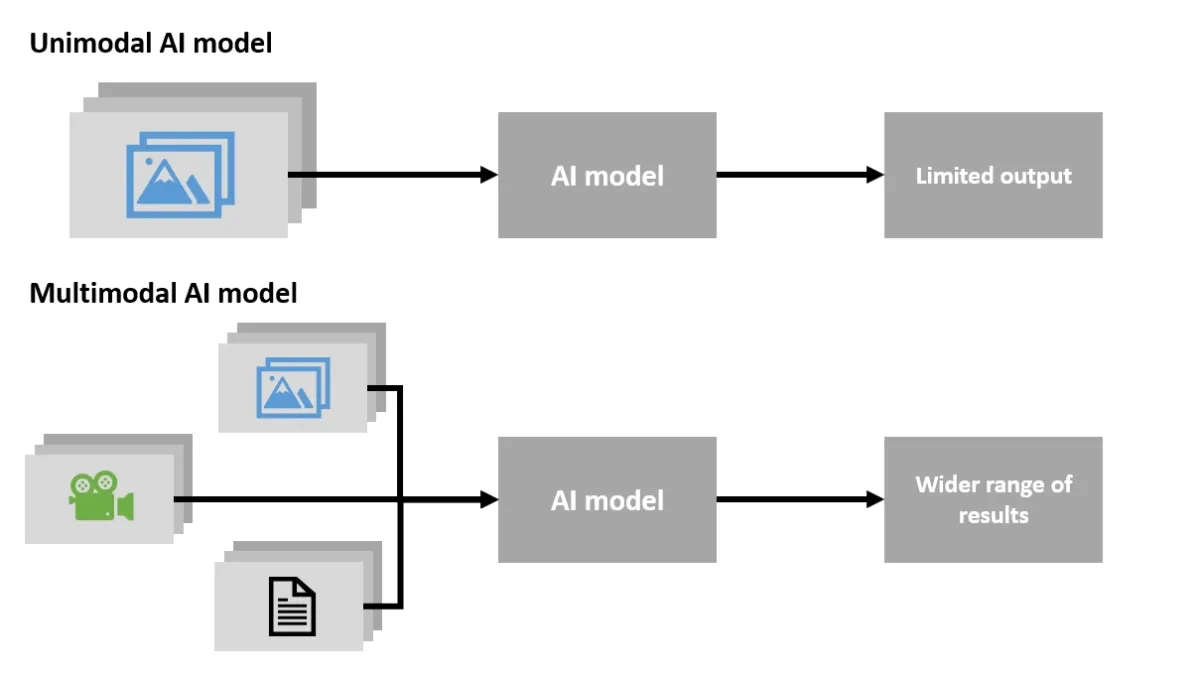
Figure 2: Unimodal vs multimodal AI model comparison.
The technology of multimodal learning
Multimodal learning is powered by fusion strategies, models such as transformers, multimodal variational autoencoders, graph neural networks, and self-supervised learning techniques:
Fusion strategies for multimodal learning
Early fusion: This approach combines data from multiple modalities (e.g., text, audio, images) at the input stage, forming a unified representation before further processing.
Example: Speech recognition systems integrate both text (e.g., transcriptions) and audio waveforms to improve accuracy.
Similarly, frame sequences and audio signals are fused early to enhance comprehension in video understanding.
Late fusion: Each modality is processed independently using specialized models, and the results are merged later. This allows individual models to be optimized for their respective data types.
Example: Autonomous driving systems process camera feeds, radar signals, and LiDAR data separately, then merge the extracted information to make driving decisions.
Hybrid fusion: A combination of early and late fusion, leveraging the strengths of both strategies. Certain features are combined early to provide richer input representations, while final decisions are made after analyzing modalities separately.
Example: Medical AI applications integrate textual radiology reports (early fusion with images) and additional patient metadata (late fusion) to provide a more holistic diagnosis.
Architectures for multimodal AI
Transformer-based models: Transformers use self-attention mechanisms to capture relationships between different data types.
- CLIP (Contrastive Language-Image Pretraining): Aligns text and image embeddings for tasks like zero-shot image classification.
- Flamingo (DeepMind): Processes visual and textual inputs in a unified manner, useful for multimodal reasoning.
- Gemini (Google DeepMind): Designed for multimodal understanding, capable of handling complex reasoning across text, images, and video.
To learn more about each example, check out large vision models.
Multimodal Variational Autoencoders (VAEs): VAEs are generative models that learn a probabilistic latent space, useful for cross-modal generation.
Example: Used in creative AI applications, such as generating realistic images from textual descriptions (text-to-image synthesis) or reconstructing missing modalities.
Graph Neural Networks (GNNs) for multimodal data: GNNs model relationships between heterogeneous data types by representing them as graph structures.
Example: In drug discovery, GNNs connect molecular structures (chemical data), biological interactions, and clinical trials (textual data) to predict drug efficacy.
Self-supervised learning for multimodal AI
Learning from unlabeled data: Self-supervised learning enables models to learn from vast amounts of data without explicit labels, leveraging contrastive learning or masked prediction techniques.
- CLIP: Learns by matching images with corresponding text descriptions, enabling zero-shot learning capabilities.
- Flamingo: Uses self-supervised learning to align textual and visual contexts for applications like visual question-answering.
Understanding multimodal learning in education
Multimodal learning recognizes that students learn best when exposed to multiple modalities: A combination of sensory channels and learning methods that engage multiple senses. This approach leverages different learning styles, including visual, auditory, reading/writing, and kinesthetic preferences.
The VARK model categorizes these four basic categories to support multimodal learning and enhance the learning experience for diverse learners.
To identify their learning style, students can take the VARK questionnaire, a short assessment that provides insights into their primary or combined learning preferences. Results help students to adapt study techniques that align with their natural inclinations, while teachers can leverage these insights to design more inclusive lesson plans.
By using the VARK model, educators can accommodate diverse classroom needs, enhancing engagement and effectiveness. Similarly, students can use this understanding to tailor their study habits, improving comprehension and retention.
Check out reinforcement learning for more on AI and learning.
Characteristics of different learning styles
By integrating multiple learning styles into training programs, educators cater to students’ learning preferences and optimize the learning process. Below are the key characteristics of each particular learning style:
Visual learners: Visual learning relies on visual elements such as diagrams, charts, and visual representations. These learners process information best through visual cues like color-coded notes or multimodal assignments that include visual representations and different fonts.
Auditory learners: Auditory learning stimulates the learners’ ears through auditory cues like spoken instructions or group discussions. These learners excel in training sessions that involve listening to lectures, podcasts, or verbal explanations.
Reading/writing learners: These learners prefer written communication and often excel in tasks that require note-taking or text-heavy materials. Multimodal learning strategies for these learners include training content like reports, essays, and written assignments.
Kinesthetic learners: Kinesthetic learning is an approach that primarily stimulates the learners’ hands. Kinesthetic learners prefer hands-on activities like experiments, simulations, or educational games to connect concepts to real-world applications.
Educators and trainers must design training programs that leverage multiple channels and learning modes to create an inclusive multimodal learning environment. Examples of multimodal learning include:
- Blended learning techniques: Combining in-person classes with online resources through a learning management system.
- Multimedia presentations: Using audio, video, and visual cues to cater to visual auditory learners.
- Tactile cues: Incorporating hands-on exercises to engage kinesthetic learners.
- Group discussions: Encouraging collaborative learning that supports auditory learners and enhances student understanding.
- Multimodal assignments: Offering tasks in different formats, such as video submissions, written reports, and interactive projects.
Real-life examples of multimodal learning
Autonomous vehicles & robotics
- Tesla and Waymo use multimodal AI by integrating camera vision, radar, LiDAR, and audio sensors for real-time decision-making.2
- Boston Dynamics’ robots process video, tactile sensors, and environmental sound to improve human-like interaction and navigation.3
Healthcare innovations
- Multimodal large language models (MLLMs) like Med-PaLM 2 integrate medical texts, imaging data (X-rays, CT scans), and genomic sequencing for precise diagnostics.4
- AI-powered prosthetics: BrainCo uses EEG signals, haptic feedback, and computer vision to enhance prosthetic limb control.5
Multimodal AI for business & productivity
- Microsoft’s Copilot integrates text, voice, and visual data for document creation, data analysis, and AI-assisted meetings.
- AI-powered CRM Systems like Salesforce Einstein use customer sentiment analysis from emails, calls, and video interactions to improve sales forecasting.6
Other examples
Meta’s project CAIRaoke
Meta, Facebook’s parent company, claims to be working on a digital assistant project based on multimodal AI, which can interact with a person like a human. The assistant is planned to be able to turn images into text and text into images.7
For instance, if a customer writes, “I want to purchase a blue polo shirt; show me some blue polo shirts,” the model will be able to show some images of blue polo shirts.
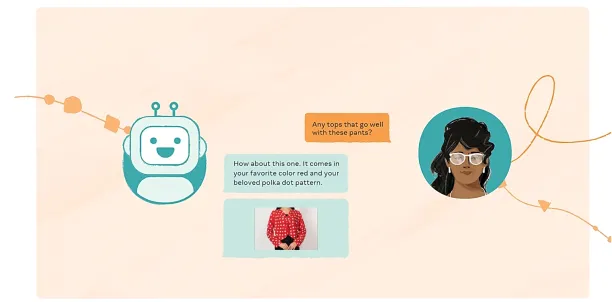
Figure 3: An example conversation between a person and a chatbot trained with multimodal learning.
Google’s video-to-text research
Google’s recent study claims to have developed a multimodal system that can predict the next dialogues in a video clip.8
The model successfully predicted the next dialogue line that would be spoken in a tutorial video on assembling an electric saw (See image below).

Figure 4: The model prediction of the next dialogue in an electric saw assembly tutorial video with subtitles and snapshots.
Automated translator for Japanese comics
Scientists and researchers at Yahoo! Japan, the University of Tokyo, and the machine translation company Mantra developed a prototype of a multimodal system.
The system can translate comic book text from speech bubbles which require an understanding of the context to be translated. It was initially developed to translate Japanese comics. It can also identify the gender of the speaking character in the comic.9
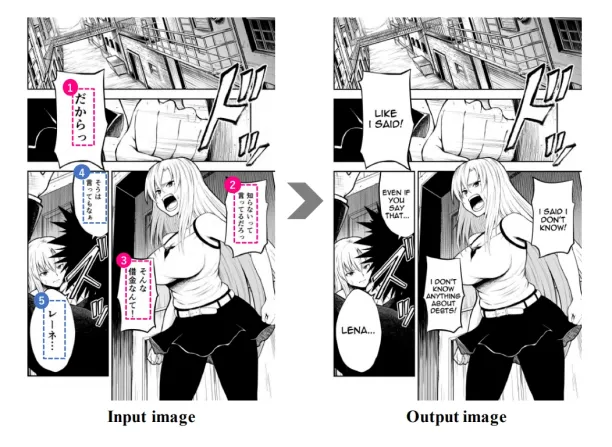
Figure 5: A Japanese comic book illustration with multimodal learning.
You can also check out data collection and sentiment analysis services to find the option that best suits your business needs.
What are the benefits of multimodal learning?
1. Improved capabilities
Multimodal learning for AI/ML expands a model’s capabilities. A multimodal AI system analyzes many types of data, giving it a wider understanding of the task and making the AI/ML model more human-like.
For instance, a smart assistant trained through multimodal learning can use imagery data, audio data, pricing information, purchasing history, and even video data to offer more personalized product suggestions.
2. Improved accuracy
Multimodal learning can also improve the accuracy of an AI model. For example, an apple can be identified visually and through the sound of it being bitten or its smell.
Similarly, when an AI model is shown an image of a dog and combines it with audio data of a dog barking, it can re-assure itself that this image is, indeed, of a dog.
3. Enhanced human-AI interaction
Multimodal learning enhances the quality of interactions between humans and AI systems.
For instance, a virtual assistant that integrates voice recognition, facial expressions, and gesture detection can respond more intuitively to a user’s emotional state or intent, making interactions feel more natural and human-like.
4. Better user experiences in applications
Multimodal AI supports innovative applications that deliver more engaging user experiences.
For instance, in gaming or virtual reality, integrating audio, video, haptic feedback, and motion sensing creates a more immersive and realistic environment for users.
5. Improved real-time decision making
Multimodal systems can make faster and more informed decisions by processing and synthesizing data from multiple sources simultaneously.
For example, integrating patient data such as medical images, lab results, and health records enables quicker diagnosis and personalized treatment planning in healthcare.
External Links
- 1. A survey on deep multimodal learning for computer vision: advances, trends, applications, and datasets | The Visual Computer . Springer Berlin Heidelberg
- 2. AI & Robotics | Tesla.
- 3. Atlas | Boston Dynamics.
- 4. Med-PaLM: A Medical Large Language Model - Google Research.
- 5. Hangzhou's BrainCo starts producing smart bionic prosthetics .
- 6. AI for Sales | Salesforce EMEA.
- 7. Project CAIRaoke: Building the assistants of the future with breakthroughs in conversational AI.
- 8. https://arxiv.org/pdf/2012.05710.pdf
- 9. https://arxiv.org/pdf/2012.14271.pdf



Comments
Your email address will not be published. All fields are required.