Large language models (LLMs) can handle textual tasks well but struggle with non-textual inputs, such as speech or video. In contrast, large multimodal models (LMMs) are emerging to handle various data types, including text, images, and audio.
However, their technical complexity and data demands present potential challenges. Innovations in AI research are aiming to overcome these challenges.

Explore large multimodal models and compare them to large language models:
What are leading LMMs?
General purpose LLMs UI & API features
ChatGPT
Perplexity
Claude
Grok
Gemini
| Provider | Context window (tokens) | Per File Upload Limit (MB) |
|---|---|---|
| ChatGPT | 128K | 512 |
| Perplexity | Model-dependent (e.g., 200K via Claude 3.5 Sonnet) | 25 |
| Claude | 200K | 30 |
| Grok | 1,000K | 1024 |
| Gemini | 2,000K | 100 |
Vendors are selected among the most popular multimodal LLMs based on comparability, data availability, and timeliness.
LMMs with their price per tokens:
| Large multimodal models | Input Price / 1M tokens | Output Price/ 1M tokens |
|---|---|---|
| GPT-4.5 | $75.00 | $150.00 |
| Claude 3 Opus | $15.00 | $75.00 |
| Claude 3.5 / 3.7 Sonnet | $3.00 | $15.00 |
| GPT-4o | $2.50 | $10.00 |
| Gemini 1.5 Pro | $1.25 | $5.00 |
| Claude 3.5 Haiku | $0.80 | $4.00 |
| GPT-4o mini | $0.15 | $0.6 |
To select the most suitable model, consider factors such as your budget, the required capabilities and performance level, and the expected volume of input/output tokens needed for your specific use case.
You can read more about the pricing of llms.
What are the latest advancements in multimodal models?
Recent advancements in multimodal models have introduced new capabilities and efficiencies in AI development.
Llama 4 Scout and Llama 4 Maverick by Meta AI
Llama 4 Scout is a multimodal model with 17 billion active parameters and 16 experts. This model outperforms previous generation Llama models and is designed to operate on a single H100 GPU. It features a 10 million token context window for processing large amounts of information. Benchmark results indicate Llama 4 Scout achieves better results than Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 across a range of widely reported benchmarks.
Llama 4 Maverick is a multimodal model with 17 billion active parameters and 128 experts. This model is presented as a top performer in its class, outperforming GPT-4o and Gemini 2.0 Flash across a range of benchmarks. It achieves comparable performance to DeepSeek v3 in reasoning and coding, while using fewer active parameters. An experimental chat version of Llama 4 Maverick achieved an ELO score of 1417 on the LMArena platform.1
4o Image Generation by OpenAI
OpenAI’s latest image-generation model, embedded within GPT-4o, integrates text and visual creation into a unified system. This multimodal capability allows GPT-4o to generate images while drawing on its text-based knowledge and chat context, creating an interplay between language and visuals.
Through multi-turn generation, users can refine images conversationally as shown in the figures below. The model builds upon prior text inputs and uploaded images to maintain consistency. By analyzing user-provided visuals and learning in context, GPT-4o adapts to specific details, enhancing its ability to produce context-aware imagery.
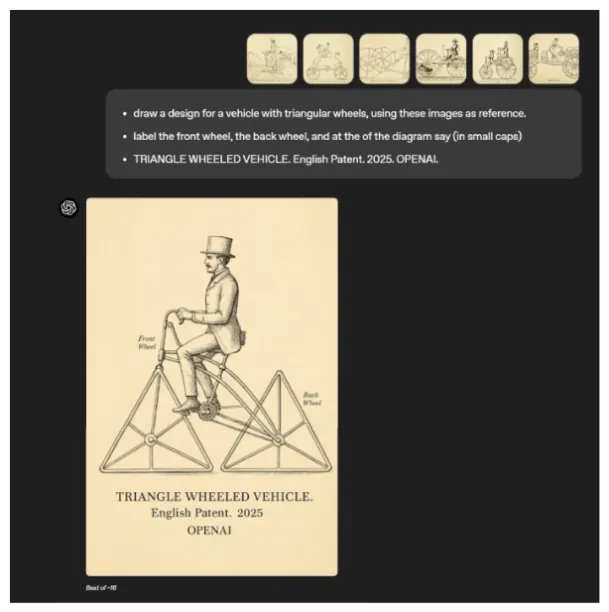
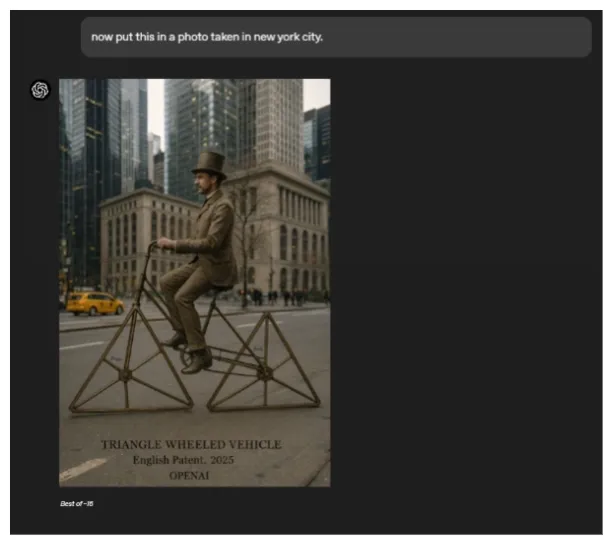
Qwen2.5-VL-32B-Instruct by Alibaba
Alibaba’s Qwen2.5-VL-32B-Instruct builds on the Qwen2.5 language model with visual processing features. The 32B parameter model focuses on image understanding and reasoning. It was pretrained on 18T tokens with a 128K token context window and includes multilingual support. The model improves image parsing, content recognition, and visual reasoning, making it useful for applications that combine image and text analysis.
Gemma 3 by Google
Google’s Gemma 3 builds on technology from their Gemini 2.0 models. It comes in four sizes (1B, 4B, 12B, and 27B) for different hardware requirements and offers a 128k-token context window. Gemma 3 performs well on single-accelerator setups and includes text and visual reasoning, function calling, and support for over 35 languages, with pretraining for more than 140. Quantized versions reduce model size and computing needs. The ShieldGemma 2 system provides content safety classification.
Phi-4-multimodal by Microsoft
Microsoft’s Phi-4-multimodal is a 5.6B parameter model that processes speech, vision, and text in a unified architecture. It uses cross-modal learning for context-aware interactions between different input types. The model handles multiple input formats without requiring separate processing systems and is designed for device deployment and edge computing. Applications include smartphone AI, automotive systems, and multilingual services.
What are open-source large multimodal models?
Open source LMMs with their number of GitHub stars:
The graph shows that the GitHub popularity of various open-source LMMs has been increasing, with some models experiencing rapid adoption shortly after their release.
Janus-Series by DeepSeek gained thousands of GitHub stars within days after the release of Janus-Pro on January 27, 2025, surpassing its competitors, which took months to reach similar numbers. This rapid rise was not only due to Janus-Pro’s success but also influenced by the momentum created by DeepSeek-R1.
- Gemma 3 by Google: Gemma 3 is a family of lightweight, state-of-the-art open models derived from Gemini 2.0 technology. These models offer advanced text and visual reasoning capabilities, a 128k-token context window, function-calling support, and quantized versions for optimized performance. It includes ShieldGemma 2 for image safety and supports diverse tools and deployment options.3
- Janus-Pro by DeepSeek: Janus-Pro is an advanced version of the Janus model, designed to both understand and generate text and images. It features an optimized training strategy, expanded training data, and a larger model size, enhancing its multimodal capabilities.4
- Qwen2.5-VL by Alibaba: Qwen2.5-VL by Alibaba is a multimodal extension of the Qwen2.5 language model, designed for both text and image understanding. It boasts large-scale pretraining (up to 18T tokens), an extended context window (up to 128K tokens), improved instruction following, and robust multilingual support, making it suitable for tasks like image captioning and visual question answering. 5
Building upon the Qwen2.5-VL series, Alibaba optimized and open-sourced Qwen2.5-VL-32B-Instruct, a 32B VL model incorporating enhanced fine-grained image understanding and reasoning. This results in improved performance and detailed analysis within tasks like image parsing, content recognition, and visual logic deduction.6 - CLIP (Contrastive Language–Image Pretraining) by OpenAI: CLIP is designed to understand images in the context of natural language. It can perform tasks like zero-shot image classification, where it can accurately classify images even in categories it hasn’t explicitly been trained on by understanding text descriptions.7
- Flamingo by DeepMind: Flamingo is designed to leverage the strengths of both language and visual understanding, making it capable of performing tasks that require interpreting and integrating information from both text and images.8
What is a large multimodal model (LMM)?
A large multimodal model is an advanced type of artificial intelligence model that can process and understand multiple types of data modalities. These multimodal data can include text, images, audio, video, and potentially others. The key feature of a multimodal model is its ability to integrate and interpret information from these different data sources, often simultaneously.
These can be understood as more advanced versions of large language models (LLMs) that can work not only on text but diverse data types. Also, multimodal language model outputs are targeted to be not only textual but visual, auditory, etc.
Multimodal language models are considered to be the next step toward artificial general intelligence.
What is a multimodal AI agent?
Multimodal AI agents are systems designed to interact with the world using various types of data, including images, videos, and text, allowing them to operate in both digital and physical environments. Multimodal models are the core component of these agents, providing them with the ability to perceive and understand information from these diverse sources.
For example, models like Magma utilize vision-language understanding and spatial intelligence, achieved through techniques like Set-of-Mark and Trace-of-Mark during pretraining on multimodal datasets.
This enables the agent to perform tasks ranging from understanding video content and answering questions to navigating user interfaces and controlling robots, demonstrating the versatile capabilities that multimodal models bring to AI agents by leveraging different data modalities. The illustration shows Magma planning robot trajectories to accomplish tasks, showcasing its spatial intelligence in action.10
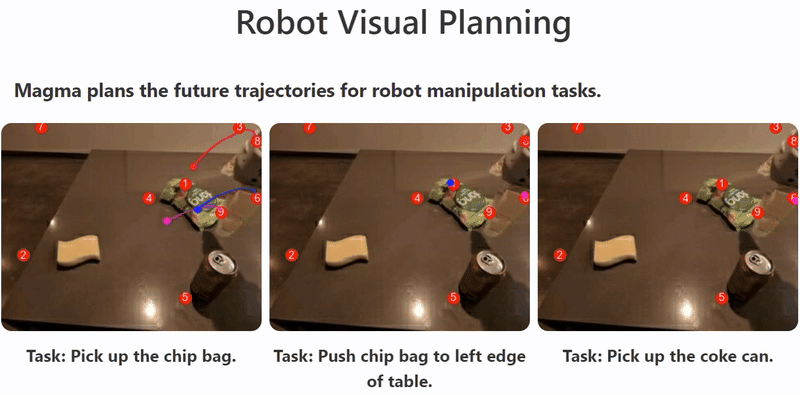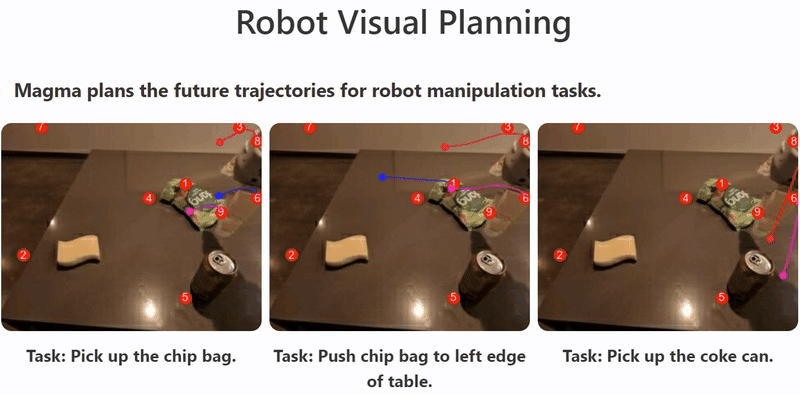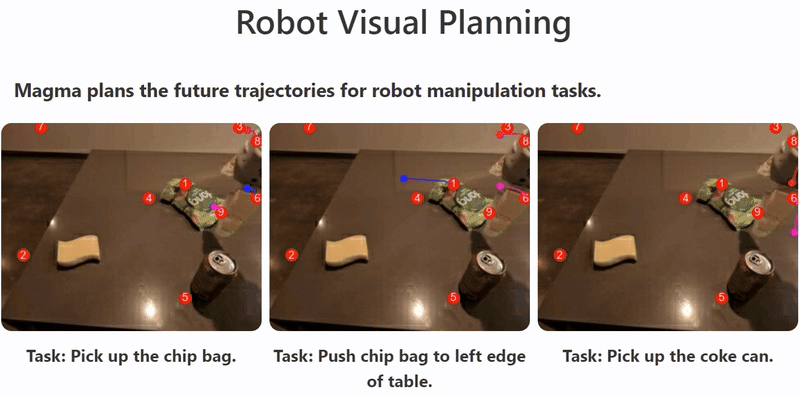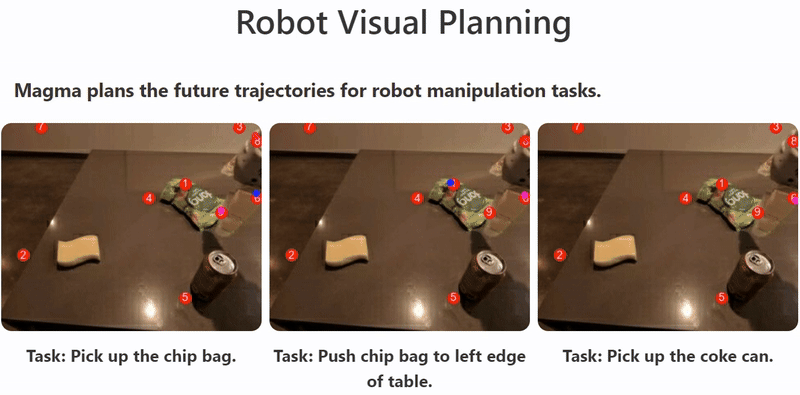
What is the difference between LMMs and LLMs?
| Aspect | Large Multimodal Models (LMMs) | Large Language Models (LLMs) |
|---|---|---|
| Data Modalities | Can handle and make sense of different types of data, such as text, images, audio, video, and sometimes sensor readings. | Focuses only on text. Doesn’t handle other types of data like images or audio. |
| Integration Capabilities | Good at combining and understanding various kinds of data at once. | Works only with text and doesn’t combine it with other data types. |
| Applications and Tasks | Used for tasks that need understanding multiple data types together. For example, analyzing a news article with related photos and videos. | Used for text-based tasks such as writing, translating, answering questions, summarizing, and creating content. |
| Data Collection and Preparation | Involves collecting diverse media—text, images, audio, and video—requiring careful annotation and normalization for integration. | Involves collecting large amounts of text from books, websites, and other sources, focusing on a wide range of language. |
| Model Architecture Design | Uses different types of neural networks, like CNNs for images and transformers for text, and combines them to handle various data types. | Typically uses transformer architectures designed specifically for processing and generating text. |
| Pre-Training | Pre-trained on diverse data to link text with media, enabling tasks like image captioning. | Pre-trained on large text corpora using methods like predicting missing words in sentences. |
| Fine-Tuning | Fine-tuning involves working with specialized datasets for each data type and learning how different types of data relate to each other. | Fine-tuning uses specific text datasets tailored to particular tasks like answering questions or translating languages. |
| Evaluation and Iteration | Evaluated on its ability to recognize images, process audio, and integrate diverse data types. | Evaluated based on performance in understanding and generating text, focusing on fluency, coherence, and relevance. |
1- Data Modalities
- LMMs: They are designed to understand and process multiple types of data inputs, or modalities. This includes text, images, audio, video, and sometimes other data types like sensory data. The key capability of LMMs is their ability to integrate and make sense of these different data formats, often simultaneously.
- LLMs: These models are specialized in processing and generating textual data. They are trained primarily on large corpora of text and are adept at understanding and generating human language in a variety of contexts. They do not inherently process non-textual data like images or audio.
2- Applications and Tasks
- LMMs: Because of their multimodal nature, these models can be applied to tasks that require understanding and integrating information across different types of data. For example, an LMM could analyze a news article (text), its accompanying photographs (images), and related video clips to gain a comprehensive understanding.
- LLMs: Their applications are centered around tasks involving text, such as writing articles, translating languages, answering questions, summarizing documents, and creating text-based content.
What are the data modalities of large multimodal models?
Text
This includes any form of written content, such as books, articles, web pages, and social media posts. The model can understand, interpret, and generate textual content, including natural language processing tasks like translation, summarization, and question-answering.
Images
These models can analyze and generate visual data. This includes understanding the content and context of photographs, illustrations, and other graphic representations. Tasks like image classification, object detection, and even creating images based on textual descriptions fall under this category.
Audio
This encompasses sound recordings, music, and spoken language. Models can be trained to recognize speech, music, ambient sounds, and other auditory inputs. They can transcribe speech, understand spoken commands, and even generate synthetic speech or music.
Video
Combining both visual and auditory elements, video processing involves understanding moving images and their accompanying sounds. This can include analyzing video content, recognizing actions or events in videos, and generating video clips.
While most current large multimodal language models can only process text and images, future research aims to include audio and video data inputs.
How are large multimodal models trained?
Training large multimodal models (LMMs) differs significantly from training large language models (LLMs) in several key aspects:
1- Data Collection and Preparation
- LLMs: Focus on text data from books, websites, and written sources, emphasizing linguistic diversity for LLM training data sources.
- LMMs: Require text, images, audio, and video data. Collection is more complex due to varied formats. Data annotation and alignment between modalities is essential.
2- Model Architecture Design
- LLMs: Use transformer architectures optimized for sequential text processing.
- LMMs: Employ more complex architectures that integrate multiple neural network types (CNNs for images, transformers for text) with mechanisms to connect these modalities.
3- Pre-Training
- LLMs: Pre-train on text corpora using techniques like masked language modeling.
- LMMs: Pre-train across multiple data types, learning to correlate text with images or understand video sequences.
4- Fine-Tuning
- LLMs: Fine-tune on specialized text datasets for specific tasks.
- LMMs: Require fine-tuning on both modality-specific datasets and cross-modal datasets to establish relationships between different data types.
5- Evaluation and Iteration
- LLMs: Evaluation metrics are focused on language understanding and generation tasks like fluency, coherence, and relevance.
- LMMs: Assessed on broader metrics covering image recognition, audio processing, and cross-modal integration capabilities.
How do LLMs work?
Large multimodal models are similar to large language models in the training process, design, and operation. They use the same transformer architecture and training strategies. Large multimodal models are trained on:
- Text data
- Millions or billions of images with text descriptions
- Video clips
- Audio snippets
- Other input data like code
This training involves simultaneous learning of multiple data modalities, enabling the model to:
- Recognize a photo of a cat
- Identify a woof in an audio clip
- Understand concepts and sensory details beyond text
This way, users can upload:
- An image to:
- Get a description of what’s going on
- Use the image as part of a prompt to generate text or images
- Ask follow-up questions about specific elements of the image
- Translate the text of the image to a different language (e.g Menu)

- Charts and graphs to:
- Ask complicated follow-up questions about what they show
- Design mockup to:
- Get the HTML and CSS code necessary to create it.
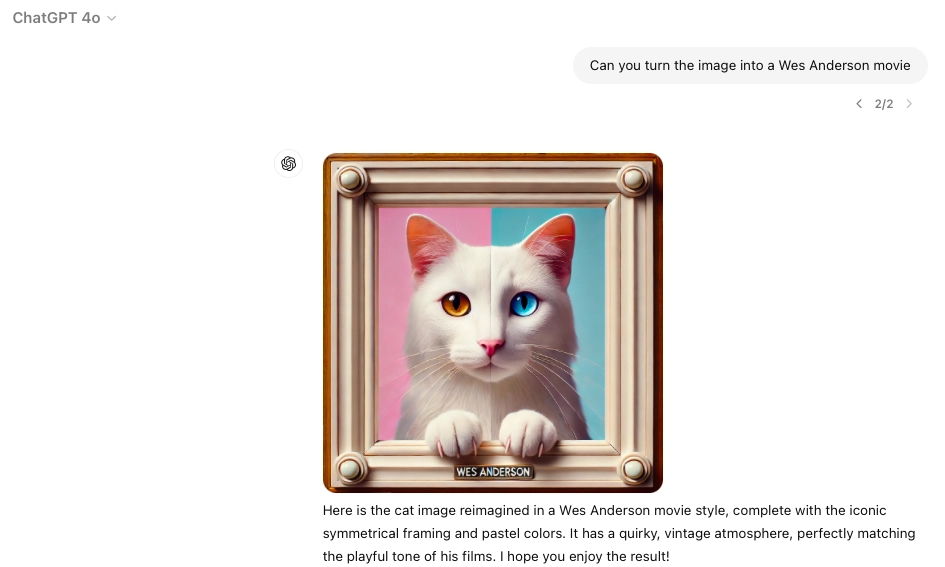
After the training process, models might incorporate unhealthy stereotypes and toxic ideas. To refine them, techniques like:
- Reinforcement learning with human feedback (RLHF)
- Supervisory AI models
- Red teaming (testing the model’s robustness) can be used.
Also, AI governance tools and responsible AI tools functioning as AI compliance solutions can also enable AI inventory optimization, helping prevent AI bias and other ethical dilemmas. Here is an example of how these tools address gen AI copyright concerns:
The goal is to develop a functional multimodal system capable of handling:
- Text to image synthesis
- Image captioning
- Text-based image retrieval
- Visual question answering.
In this way, multimodal AI can integrate various modalities, providing advanced capabilities for tasks that involve both language and vision.
What are the limitations of large language models?
- Data requirements and bias: These models require massive, diverse datasets for training. However, the availability and quality of such datasets can be a challenge. Moreover, if the training data contains biases, the model is likely to inherit and possibly amplify these biases, leading to unfair or unethical outcomes.
- Computational resources: Training and running large multimodal models require significant computational resources, making them expensive and less accessible for smaller organizations or independent researchers.
- Interpretability and explainability: As with a complex AI model, understanding how these models make decisions can be difficult. This lack of transparency can be a critical issue, especially in sensitive applications like healthcare or law enforcement.
- Integration of modalities: Effectively integrating different types of data (like text, images, and audio) in a way that truly understands the nuances of each modality is extremely challenging. The model might not always accurately grasp the context or the subtleties of human communication that comes from combining these modalities.
- Generalization and overfitting: While these models are trained on vast datasets, they might struggle with generalizing to new, unseen data or scenarios that significantly differ from their training data. Conversely, they might overfit the training data, capturing noise and anomalies as patterns.
For more content on the challenges and risks of generative and language models, check our article.
If you have questions or need help in finding vendors, reach out:
External Links
- 1. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation.
- 2. Introducing 4o Image Generation | OpenAI.
- 3. Gemma 3: Google’s new open model based on Gemini 2.0. Google
- 4. GitHub - deepseek-ai/Janus: Janus-Series: Unified Multimodal Understanding and Generation Models.
- 5. GitHub - QwenLM/Qwen2.5-VL: Qwen2.5-VL is the multimodal large language model series developed by Qwen team, Alibaba Cloud..
- 6. Qwen2.5-VL-32B: Smarter and Lighter | Qwen.
- 7. CLIP: Connecting text and images | OpenAI.
- 8. [2204.14198] Flamingo: a Visual Language Model for Few-Shot Learning.
- 9. Multimodality and Large Multimodal Models (LMMs).
- 10. Magma: A Foundation Model for Multimodal AI Agents.


Comments
Your email address will not be published. All fields are required.