Large vision models (LVMs) can automate and improve visual tasks such as defect detection, medical diagnosis, and environmental monitoring.
- For multimodal models (image and text), see GPT-4o (Vision), Midjourney, and CLIP.
- For video generation and comprehension models, see Sora and Flamingo.
- For image-based applications, see LandingLens, Stable Diffusion, and Vision Transformer (ViT).
Before comparing the top 8 large vision models, it’s important to note that in specialized tasks like object detection, LVMs still lag behind domain-specific models. While GPT-4o (Vision) supports object detection, it is not yet optimized like YOLOv8n or DETR.
We benchmarked GPT-4o (Vision) against YOLOv8n and DETR—two models designed specifically for object detection.
Object detection benchmark: GPT-4o (Vision), YOLOv8n, DETR
mAP@0.5: Mean Average Precision at an Intersection over Union (IoU) threshold of 0.5, measuring the accuracy of object detection by balancing true positives and false positives.
Latency (ms): The average processing time per image, measured in milliseconds, indicates the speed of the model.
Benchmark Results
We observed that GPT-4o’s object detection performance remains quite limited compared to specialized models explicitly designed for this task, such as YOLOv8n and DETR.
In our results, DETR achieved a mAP@0.5 of 0.55, YOLOv8n scored 0.20, while GPT-4o only reached 0.02. These findings suggest that GPT-4o is not yet a practical alternative for object detection tasks.
When looking at latency, YOLOv8n showed the quickest processing time at 365 ms, DETR was slower at 3145 ms, and GPT-4o lagged behind with 5150 ms. YOLOv8n offers higher speed but lower accuracy, whereas DETR provides better accuracy at the cost of slower processing.
We ensured a fair comparison by evaluating all models on the same 800×800 input image size. While parameter counts and FLOPS were clearly available for DETR and YOLOv8n, this information was not accessible for GPT-4o, which limits a precise assessment of its computational requirements.
DETR, with 41.52 million parameters and 59.56 GFLOPS, is significantly more computationally intensive than YOLOv8n, which operates with only 3.15 million parameters and 6.83 GFLOPS. This highlights YOLOv8n’s efficiency for real-time applications, whereas DETR may offer higher accuracy at the cost of speed and resource demands. The absence of GPT-4o’s architectural details makes it difficult to analyze its efficiency in a comparable manner.
You can see our benchmark methodology from here.
Comparing top 8 large vision models
| Model | Developer | Release Year | Main Use Case |
|---|---|---|---|
| GPT-4o (Vision) | OpenAI | 2024 | Image-text understanding |
| Sora | OpenAI | 2024 | Text-to-video generation |
| LandingLens | Landing AI | 2023 | Industrial visual inspection |
| Stable Diffusion | Stability AI | 2022 | Image generation |
| Midjourney | Midjourney | 2022 | Creative image generation for art and design |
| Flamingo | DeepMind | 2022 | Few-shot visual learning |
| CLIP | OpenAI | 2021 | Image-text understanding |
| Vision Transformer (ViT) | 2020 | Image classification |
Note: The models are sorted by release date (from newest to oldest).
Technical differences
| Model | Primary Modality | Model Type | Training Data | Training Objective | Fine-tuning Support |
|---|---|---|---|---|---|
| GPT-4o (Vision) | Multimodal (Text-Image) | Transformer-based Multimodal LLM | Web text & licensed data | Autoregressive | Limited |
| Sora | Multimodal (Text-Image-Video) | Diffusion Model (speculated) | Large-scale video dataset | Video Generation | Yes |
| LandingLens | Image | AI Vision Platform | Custom user datasets | Supervised Learning | Yes |
| Stable Diffusion | Image | Diffusion Model | LAION-5B dataset* | Denoising Diffusion | Yes |
| Midjourney | Multimodal (Text-Image) | Proprietary (likely Diffusion-based) | User-provided image prompts | Image Generation | Yes |
| Flamingo | Multimodal (Text-Image-Video) | Transformer | Web text & image data | Few-shot Learning | Yes |
| CLIP | Multimodal (Text-Image) | Contrastive Learning | Image-text pairs | Contrastive Learning | Yes |
| Vision Transformer (ViT) | Image | Transformer | Labeled image datasets | Image Classification | Yes |
*The LAION-5B dataset is a large-scale, open-source dataset of 5 billion image-text pairs. It was created by the LAION (Large-scale AI Open Network) project and is designed to train AI models, especially for tasks like image-text matching and multimodal understanding.
Performance
| Model | Zero-shot/Few-shot Learning | Multimodal Support |
|---|---|---|
| GPT-4o (Vision) | ✅ | ✅ |
| Sora | ✅ | ✅ |
| LandingLens | ❌ | ❌ |
| Stable Diffusion | ✅ | ✅ |
| Midjourney | ✅ | ✅ |
| Flamingo | ✅ | ✅ |
| CLIP | ✅ | ✅ |
| Vision Transformer (ViT) | ✅ | ❌ |
Deployment
| Model | Open-source vs. Proprietary | Hardware Requirements | Edge Deployment |
|---|---|---|---|
| GPT-4o (Vision) | Proprietary | High (TPUs/GPUs) | ❌ |
| Sora | Proprietary | High (TPUs/GPUs) | ❌ |
| LandingLens | Proprietary | Moderate | ✅ |
| Stable Diffusion | Open-source | High (GPUs needed) | Yes (with optimizations) |
| Midjourney | Proprietary | High (TPUs/GPUs) | ❌ |
| Flamingo | Proprietary | High (TPUs/GPUs) | ❌ |
| CLIP | Open-source | Moderate | Limited |
| Vision Transformer (ViT) | Open-source | Varies (GPUs recommended) | ✅ |
Detailed evaluation of large vision models
OpenAI GPT-4o (Vision)
GPT-4o (Vision) is a multimodal extension of OpenAI’s GPT-4, designed to process and generate responses based on both text and image inputs.
This capability allows GPT-4o to interpret visual content alongside textual information, enabling a range of applications that require understanding and analyzing images.
Image interpretation: GPT-4o can analyze and describe the content of images, including identifying objects, interpreting scenes, and extracting textual information from visuals. This makes it useful for tasks like image captioning and content summarization.
Visual data analysis: The model can interpret charts, graphs, and diagrams, providing insights and explanations based on visual data. This feature is beneficial for data analysis and education applications.
Multimodal content understanding: GPT-4o can provide more comprehensive responses by combining text and image inputs. It can also enhance applications in social media analysis and content moderation. For example, it can assess sentiment or detect misinformation in posts that include both text and images.
Despite its advanced capabilities, GPT-4o can sometimes produce inaccurate or unreliable outputs. It can misinterpret visual elements, overlook details, or generate incorrect information, which may require human verification for critical tasks.
The model may also reflect biases present in its training data, leading to skewed interpretations or reinforcing stereotypes. This is a concern in sensitive applications where impartiality is crucial, including demographic inference or content moderation.
OpenAI Sora
Sora is a text-to-video model created by OpenAI. It generates short video clips from user prompts and can also extend existing videos. Its underlying technology is an adaptation of the DALL-E 3 model.
Sora works as a diffusion transformer, a denoising latent diffusion model that utilizes a Transformer. Videos are initially generated in a latent space by denoising 3D “patches” and then converted into standard space using a video decompressor.
Re-captioning is applied to enhance the training process, where a video-to-text model creates detailed captions for the videos.
With the latest developments, users can now generate videos with a resolution of up to 1080p, a maximum duration of 20 seconds, and widescreen, vertical, or square aspect ratios. They can also incorporate their assets to extend, remix, and blend existing content or create new videos from text prompts.
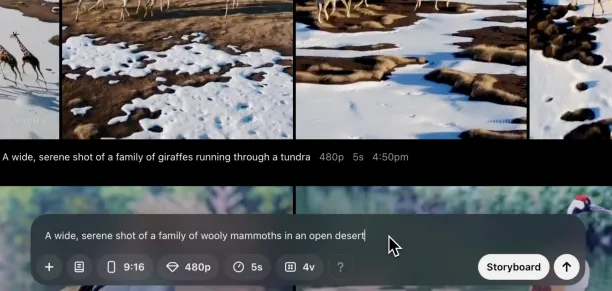
Figure 1: Sora’s video generation example using the prompt: “A wide, serene shot of a family of woolly mammoths in an open desert”.1
Landing AI LandingLens
LandingLens helps simplify developing and deploying computer vision models. It caters to various industries without requiring deep AI or complex programming expertise.
The platform standardizes deep learning solutions, which can reduce development time and easily scale projects globally. Without impacting production speed, users can build their own deep learning models and optimize inspection accuracy.
It offers a step-by-step user interface that simplifies the development process.
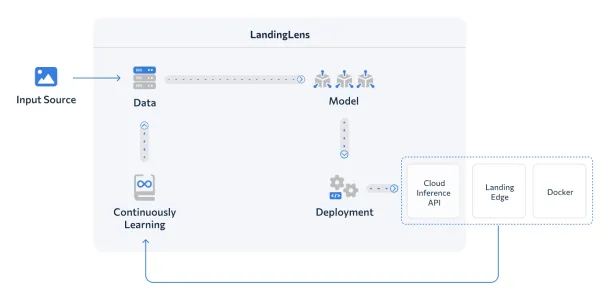
Figure 2: The diagram illustrates the LandingLens AI workflow, where input images are processed into data, used to train models, deployed via cloud, edge, or Docker, and continuously improved through feedback.2
Stable Diffusion
Stable Diffusion is a deep learning model designed to create high-quality images from textual descriptions:
- Stable Diffusion is based on the diffusion technique. The process begins by adding random noise to an image, and the model then learns to reconstruct the original by reversing this noise.
- This process enables the model to generate entirely new images while refining the noisy input over multiple steps until a clear and coherent image emerges.
Stable Diffusion utilizes a latent diffusion model to improve efficiency. Instead of working directly with high-resolution images, it first compresses them into a lower-dimensional latent space using a variational autoencoder (VAE).
This approach significantly reduces computational demands, making running on consumer hardware with GPUs feasible.
Applications:
In addition to generating images from text, Stable Diffusion can be used for various creative tasks, such as:
- Inpainting: Restoring or filling in missing parts of an image.
- Outpainting: Expanding the edges of an image to add more content.
- Image-to-Image Translation: Converting an existing image into a different style or modifying its appearance based on text input.
Midjourney
Midjourney is an art generator that converts text descriptions into high-quality images.
Developed by the independent research lab Midjourney, Inc., it was launched in July 2022 and has since become a popular tool among artists, designers, and creatives looking to bring their ideas to life.
- Text-to-Image Generation: Users can generate corresponding images using descriptive prompts, which enables a broad spectrum of creative possibilities.
- Style Customization: The platform allows users to fine-tune and modify artistic styles to ensure flexibility in creative expression.
- High-Resolution Outputs: Midjourney can create images with resolutions of up to 1,792 x 1,024 pixels.
- Object Recognition: This feature enables users to identify and extract objects from images to make precise edits and modifications easier.
- Outpainting: Midjourney allows users to extend images beyond their original boundaries by enhancing scene expansion and context creation.
- Discord Integration: Midjourney operates mainly through a Discord bot. This allows users to generate images by submitting prompts in designated channels.
- Web Interface: Introduced in August 2024, the web platform integrates tools such as image editing, panning, zooming, region variation, and inpainting into one interface.
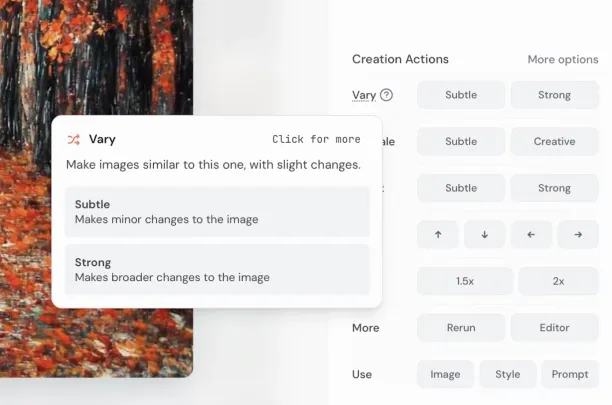
Figure 3: Midjourney’s image editing feature.3
DeepMind Flamingo
DeepMind’s Flamingo is a vision-language model designed to understand and reason about images and videos using minimal training examples (few-shot learning). Here are some of the key features:
- Multimodal Few-Shot Learning: Flamingo can perform new tasks efficiently with just a few examples, unlike traditional AI models that require extensive labeled datasets.
- Perceiver Resampler Mechanism: Flamingo uses a “Perceiver Resampler” to process visual inputs efficiently. It compresses image and video data into a format that can be integrated into a large pre-trained language model.
- Vision-Language Alignment with Gated Cross-Attention Layers: Special Gated Cross-Attention layers help Flamingo align and integrate visual data with textual reasoning. This application can be important for understanding image-based conversations.
Flamingo utilizes frame-wise processing by breaking down videos into key frames and extracting information to analyze visual elements efficiently.
Its context-aware responses help generate captions, descriptions, and answers based on the progression of events within a video to ensure a coherent understanding of the content.
Additionally, Flamingo exhibits temporal reasoning to comprehend sequences, cause-effect relationships, and complex interactions over time. This makes it highly effective for video analysis and multimodal reasoning tasks.
OpenAI’s CLIP (Contrastive Language–Image Pretraining)
CLIP is a neural network trained on a variety of images and text captions.
This model can perform various vision tasks, including zero-shot classification, by understanding images in the context of natural language.
CLIP is trained on 400 million (image, text) pairs to effectively bridge the gap between computer vision tasks and natural language processing. This helps CLIP make caption predictions or image summaries without being explicitly trained for these specific tasks.

Figure 4: Image identification by CLIP from various datasets.4
Google’s Vision Transformer (ViT)
Vision Transformer applies the transformer architecture originally used in natural language processing to image recognition tasks.
It processes images similar to how transformers process sequences of words, and it has shown effectiveness in learning relevant features from image data for classification and analysis tasks.
In Vision Transformer, images are treated as a sequence of patches. Each patch is flattened into a single vector, similar to how word embeddings are used in transformers for text.
This approach allows ViT to learn images’ structure and independently predict class labels.
What is a large vision model (LVM)?
Large vision models (LVMs) are designed to process, analyze, and interpret visual data, such as images or videos. They are characterized by their extensive number of parameters, often in the millions or billions. This enables them to learn intricate patterns, features, and relationships in visual content.
Like large language models (LLMs) for text, LVMs are trained on vast datasets, which equips them with object recognition, image generation, scene understanding, and multimodal reasoning (integrating visual and textual information) capabilities.
These models can support applications in areas such as autonomous driving, medical imaging, content creation, and augmented reality.
Structure and design
Large vision models are built using advanced neural network architectures. Originally, Convolutional Neural Networks (CNNs) were predominant in image processing due to their ability to efficiently handle pixel data and detect hierarchical patterns.
Recently, transformer models, which were initially designed for natural language processing, have also been adapted for many different vision tasks, offering improved performance in some scenarios.
Training
Training large vision models involves feeding them visual data, such as internet images or videos, along with relevant labels or annotations in the novel sequential modeling approach. Trainers label image libraries to feed the models.
For example, in image classification tasks, each image is labeled with the class it belongs to. The model learns by adjusting its parameters to minimize the difference between its predictions and the actual labels.
This process requires significant computational power and a large, diverse dataset to ensure the model can generalize well to new and unseen data.
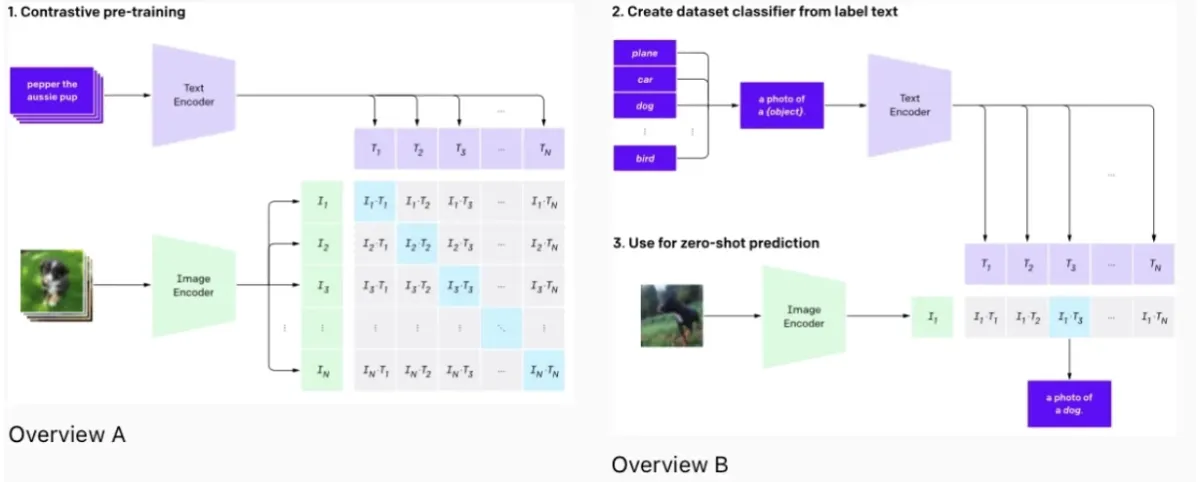
Figure 3: Large vision models training diagram on OpenAI.5
Check out image data collection services to learn more about training data for image classification.
Key features of large vision models
Model Type refers to a vision model’s architecture and design principles. It defines how the model processes and interprets visual data, whether it integrates multiple modalities (e.g., text and images), and what underlying mechanisms (e.g., transformers, contrastive learning, diffusion) it employs to extract meaningful representations:
- Transformer-based Multimodal LLM: A model architecture that combines transformers with multimodal capabilities. It enables the process of understanding both visual and textual inputs simultaneously. It is trained using large-scale datasets to perform complex reasoning across multiple data types.
- Contrastive Learning: A technique used in training models to differentiate between similar and dissimilar data points. This process involves maximizing the similarity of related inputs while minimizing the similarity of unrelated ones. This is often used in self-supervised learning to improve feature representation.
- AI Vision Platform: This system provides infrastructure, tools, and pre-trained models for various computer vision tasks, such as image recognition, object detection, and segmentation. It typically includes model training, deployment, and inference capabilities.
- Transformer: A deep learning architecture that utilizes self-attention mechanisms to process input data. It allows models to capture long-range dependencies, making it effective for natural language and vision-related tasks.
- Diffusion Model: A generative model that gradually removes noise from an initial noisy input and refines it step by step to produce a clear and structured output. It is commonly used for image generation and enhancement.
Training objective: The goal or optimization function that guides how a model learns from data. It determines how the model adjusts its internal parameters during training to improve performance on specific tasks. These are predicting the next data point (autoregressive), distinguishing similar/dissimilar inputs (contrastive learning), or classifying images into categories:
- Autoregressive: A training approach where a model predicts the next data point in a sequence based on previously observed inputs. This is often used in language modeling and generative vision models.
- Contrastive Learning: A self-supervised learning objective where the model learns by distinguishing between similar and dissimilar data pairs. It helps improve the ability to capture meaningful representations without explicit labels.
- Supervised Learning: A learning paradigm where the model is trained using labeled data, meaning each input is associated with a corresponding correct output. This approach is widely used in tasks such as classification and segmentation.
- Image Classification: A specific training objective where a model learns to categorize images into predefined classes based on visual features. The training process involves optimizing a loss function to maximize classification accuracy.
- Denoising Diffusion: A generative learning approach where a model is trained to recover clean images from noisy inputs. This process involves reversing a progressive noise addition process to improve image reconstruction and generation.
Fine-tuning Support: The ability of a model to be adapted to specific tasks by training on smaller, domain-specific datasets while retaining knowledge from its pre-training phase.
Fine-tuning helps improve performance on specialized applications.
Zero-shot/Few-shot Learning: The capability of a model to perform tasks with little to no task-specific training data.
Zero-shot learning allows inference on unseen categories, while few-shot learning enables adaptation with minimal labeled examples.
Multimodal Support: The ability of a model to process and integrate information from multiple modalities (e.g., text, images, audio).
Open-source vs. Proprietary: Open-source models have publicly available code and weights, allowing modification and deployment by the community,
Proprietary models are owned and controlled by private entities, can limit access and customization.
Edge Deployment: The ability of a model to run on edge devices (e.g., mobile phones, IoT devices) rather than relying on cloud-based servers.
Edge deployment helps reduce latency, enhances privacy, and enables real-time processing in resource-constrained environments.
What are the use cases of large vision models?
Healthcare and medical imaging
- Disease diagnosis: Detecting diseases from medical imagery such as X-rays, MRIs, or CT scans to identify tumors, fractures, or abnormalities.
- Pathology: Analyzing tissue samples in pathology for signs of cancer.
- Ophthalmology: Diagnosing diseases from retinal images.
Autonomous vehicles and robotics
- Navigation and obstacle detection: Helping autonomous vehicles and drones to navigate and avoid obstacles by interpreting real-time visual data.
- Robotics in manufacturing: Helping robots in sorting, assembling, and quality inspection tasks.
Security and surveillance
- Activity monitoring: Analyzing video feeds to detect unusual or suspicious behavior.
- Facial recognition: Used in security systems for identity verification and tracking. For example, Amazon Rekognition is a cloud-based service offered by Amazon Web Services (AWS) that provides image and video analysis features such as face detection and recognition, object and scene identification, and text extraction. It can analyze emotions, age ranges, and activities, which would be useful for personalization and security.
See below video to see Amazon Rekognition in action.6
Retail and eCommerce
- Visual search: Allowing customers to search for products using images instead of text.
- Inventory management: Automating monitoring and managing inventory through visual recognition.
Agriculture
- Crop monitoring and analysis: Monitoring crop health and growth using drone or satellite imagery.
- Pest detection: Identifying pests and diseases affecting crops.
Environmental monitoring
- Wildlife tracking: Identifying and tracking wildlife to support conservation efforts.
- Land use and land cover analysis: Monitoring changes in land use and vegetation cover over time.
Content creation and entertainment
- Film and video editing: Automating video editing and post-production processes.
- Game development: Enhancing realistic environment and character creation.
- Photo and video enhancement: Improving the quality of images and videos.
- Content moderation: Automatically detecting and flagging inappropriate or harmful visual content.
What are the challenges of large vision models?
Computational resources
Training and deploying these models require significant computational power and memory, which can make them resource-intensive.
Data requirements
They need vast and diverse datasets for training. Collecting, labeling, and processing such large datasets can be challenging and expensive. However, crowdsource companies can help handle this.
Bias and fairness
Models can inherit biases present in their training data, leading to unfair or unethical outcomes, particularly in sensitive applications like facial recognition.
Interpretability and explainability
Understanding how these models make decisions can be difficult, which concerns applications where transparency is critical. Check out explainable AI to learn how this process works and how it serves AI ethics.
Generalization
While they perform well on data similar to their training set, they may struggle with completely new or different data types.
Privacy concerns
Using large visual models, especially in surveillance and facial recognition, raises significant privacy concerns.
Regulatory and ethical challenges
Ensuring that these models comply with legal and ethical standards is increasingly important, particularly as they become more integrated into society.
Object detection benchmark methodology
In this benchmark, the performances of the object detection models YOLOv8n, DETR (DEtection TRansformer), and GPT-4o Vision were compared on the COCO 2017 validation dataset. 1000 images per model were used for the comparison. All images were resized to 800×800 pixels to ensure consistent input dimensions across models.
The YOLOv8n model was loaded with pretrained weights (yolov8n.pt) from the Ultralytics repository and inference was performed using the predict() method via the Ultralytics YOLO API. The DETR model was loaded with the detr_resnet50 architecture from the Facebook Research library, and its outputs—originally normalized in [center_x, center_y, width, height] format—were rescaled and converted to the [x1, y1, x2, y2] coordinate format. A confidence threshold of 0.5 was applied to the results of both models.
The GPT-4o Vision model was evaluated using OpenAI’s API for object detection capabilities. For this model, images from the COCO validation dataset were downloaded, annotations were loaded, and each image was converted to the appropriate format (resized to 800×800 pixels) before being sent to the API. Only detections belonging to COCO classes were requested in JSON format, and predictions returned by the API were evaluated using the same confidence threshold (0.5) and coordinate format.
In the evaluation, the models’ predicted bounding boxes were compared with ground truth boxes by calculating the Intersection over Union (IoU), with IoU ≥ 0.5 considered a true positive match. Average Precision (AP) was calculated for each class, and the mean of all classes was reported as the mAP@0.5 metric. Besides accuracy, inference times were measured and compared. Additionally, model complexity was analyzed based on FLOPs and total parameter counts.
To ensure a fair comparison, all model inferences were performed on the same hardware (identical GPU/CPU). The same preprocessing steps—resizing all images to 800×800 pixels and applying necessary normalization—were applied across all models. For post-processing, predictions were converted to the same coordinate format, a 0.5 confidence threshold was consistently applied, and uniform IoU calculation criteria were adopted during evaluation.
Within this framework, YOLOv8n, DETR, and GPT-4o Vision model were compared in terms of object detection performance and speed; additional adjustments and methods were employed to benchmark GPT-4o Vision’s capabilities against current object detection models.
Conclusion
Large vision models (LVMs) are changing how machines interpret and act upon visual data across various domains, including healthcare, autonomous systems, security, and the creative industries.
By leveraging advanced architectures, such as transformers and diffusion models, LVMs support a wide range of complex tasks—from medical imaging and real-time object detection to text-to-image and video generation.
Their ability to learn from vast, multimodal datasets enables flexible deployment scenarios, ranging from cloud-based inference to edge computing, allowing for tailored applications that span from industrial inspection to personalized content creation.
However, these capabilities come with significant challenges. The computational cost of training and deploying LVMs remains high, often requiring powerful hardware and specialized infrastructure.
Issues such as data bias, limited interpretability, and ethical concerns surrounding surveillance and privacy underscore the need for careful model governance. As LVMs continue to evolve, striking a balance between innovation and responsibility will be crucial to ensure they are utilized effectively and equitably across various sectors.
External Links
- 1. Sora is here | OpenAI.
- 2. LandingLens: Deep-Learning Computer Vision Software Platform. Landing AI
- 3. How to use Midjourney | Zapier. Zapier
- 4. CLIP: Connecting text and images | OpenAI.
- 5. CLIP: Connecting text and images | OpenAI.
- 6. Image recognition software, ML image analysis, and video analysis – Amazon Rekognition – AWS.



Comments
Your email address will not be published. All fields are required.