5 Steps to OCR Training Data in 2024


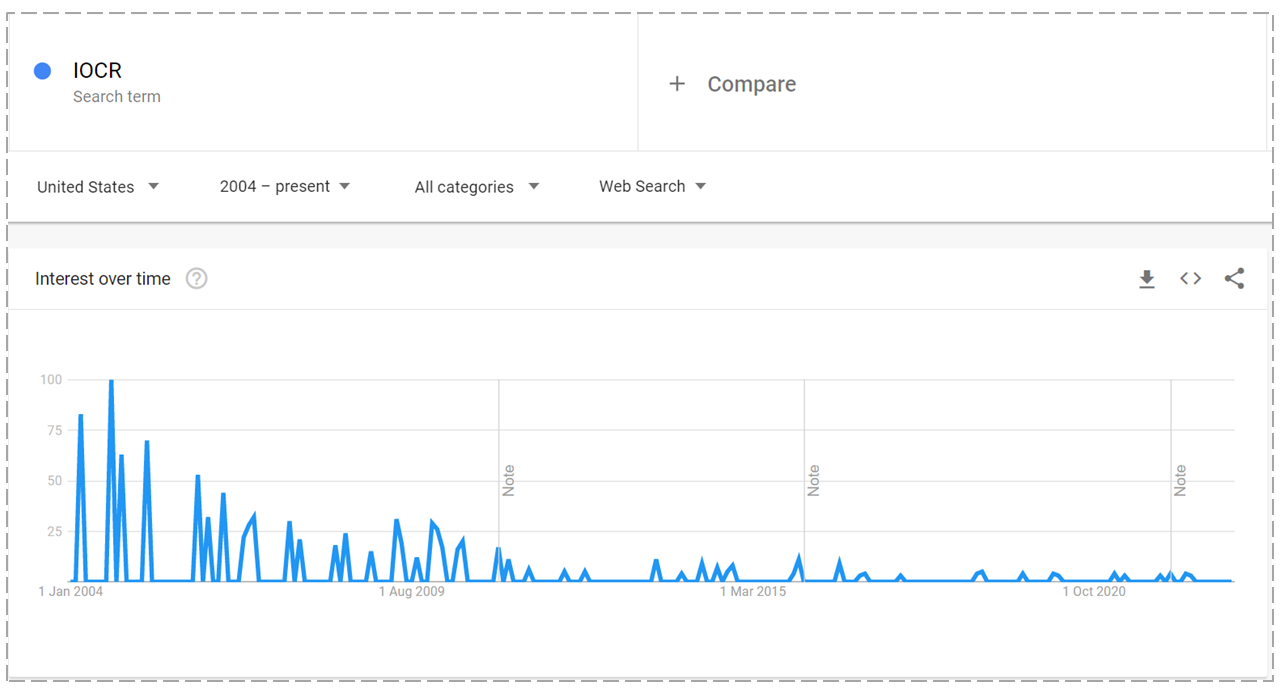
The interest in optical character recognition (OCR) and intelligent character recognition (ICR) technology is falling (see figure 1) as companies switch to more automated solutions, such as machine learning-enabled data extraction. However, due to its various benefits, many companies still use1 or plan to use tools powered by OCR technology in their paper-based operations.
Whether you use OCR/ICR or data extraction tools enabled with machine learning, you require training data to develop robust models for such solutions. Preparing datasets to train such models can be challenging.
Therefore, this article explains how developers and business leaders can prepare effective datasets to streamline the development and implementation process of their intelligent document processing (IDP) solutions.
Figure 1. Interest in OCR and ICR technology
1. Define the purpose of the dataset
First establish the dataset’s purpose. This will make it easier to decide what kind of data needs to be gathered and how it should be presented.
For instance, if the dataset’s goal is to train an OCR system to recognize text in scanned paper-based or digital documents, the information gathered should include scanned images of text in a range of font sizes, styles, and arrangements. On the other hand, if the system needs to scan documents like invoices or bills, then the dataset should include images of numerical values, calculations, formulas, etc. (see image below).
The following image shows an example of an OCR system identifying numerical values in an invoice through bounding box tags:

2. Collect relevant data
Once the purpose of the dataset is understood, the next step is to collect the relevant data. This can be done by using the following data collection methods:

To learn more about these data collection methods, check out this article.
It’s critical to gather data that is representative of the kinds of documents the system will be handling. For instance, for an AI-powered resume screening system, you need to gather data that contains images of different types of resumes, such as:
- Format (Chronological, functional, or combination)
- Academic or professional
- Field-specific resumes (For instance, a resume for a software developer will contain different terminologies as compared to a resume of a human resource candidate)
Similarly, images of handwritten text may be required for a system that will scan handwritten documents like letters or forms. The more diverse the dataset is in terms of variations in writing tools, content, writing styles, and other factors, the better the OCR system will function on new, unseen images.
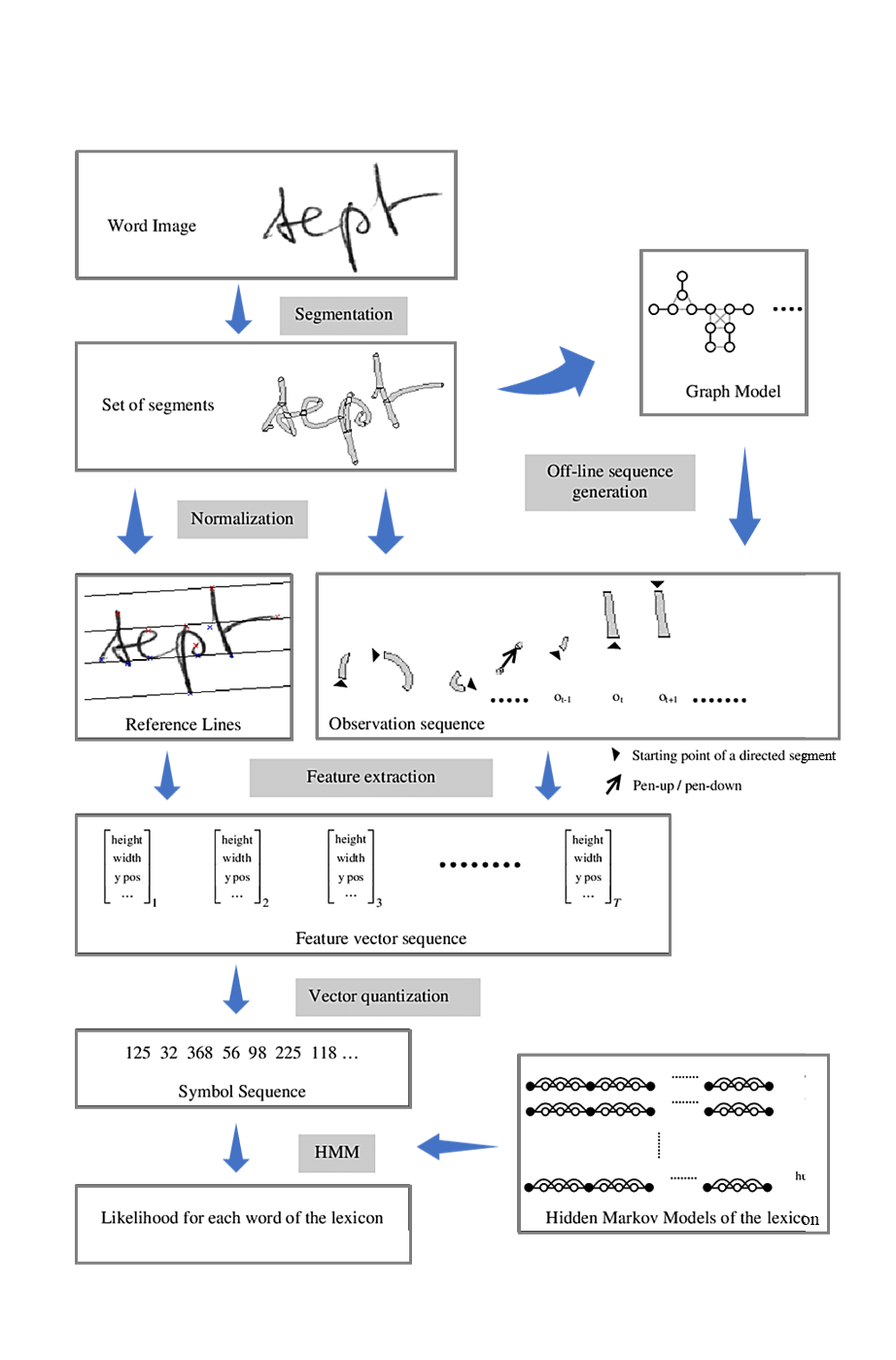
Figure 2. Shows the process happening under the hood
In another example, a license plate recognition system also uses OCR technology. The data that is required to train such systems is usually blurry images of different types of license plates in different angles and different lighting scenarios. This is mainly because the system usually needs to scan fast-moving vehicles.

Our recommendations
If preparing your own dataset through in-house data collection does not suit your project timeline or budget, you can consider outsourcing or crowdsourcing the data.
3. Annotate the data accurately
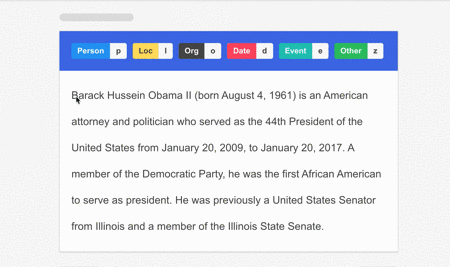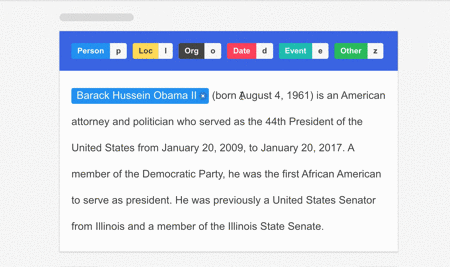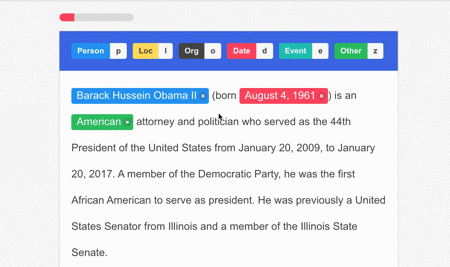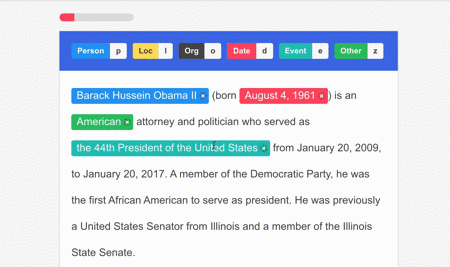
Data annotation is a crucial step in preparing training data for any machine learning model, and so is the case for OCR processing. This involves modifying the data through labels and tags to make it easier for the system to recognize the text and the data that needs to be extracted.
Things to consider while annotating OCR and ICR systems:
- In the case of an OCR system, the data should be labeled with the text that appears on the input image.
- On the other hand, for an ICR system, the data should be annotated with the information that is attached to each unit of text/numerical value (e.g., date, amount, etc.).
For higher quality annotation, you can rely on a validator for important annotation work that will double check the annotation work done by the first annotator.
Data annotation can be done manually by human annotators or by using semi-automated tools.
Manual annotation
In manual annotation, human annotators can label the images with the corresponding text using tools like a text editor, a graphical user interface, or specialized annotation software. This process can be time-consuming and may require multiple annotators for large-scale datasets.
Semi-automated annotation
Leveraging semi-automated tools can fasten the annotation process by providing assistance by using OCR for handwriting recognition algorithms. These tools can automatically create text transcriptions, which can then be reviewed and corrected by human annotators. This human-in-the-loop approach can significantly reduce the amount of time required for manual annotation while ensuring the quality of the data.
Our recommendations
Regardless of the method applied, it is important to make sure that the annotated data is accurate and consistent throughout the dataset. If in-house data labeling and automated tools do not suit your project requirements, then you can work with a data labeling partner.
If you are having trouble finding the right data labeling service, check our data-driven guide to selecting the right data labeling partner for your project.
4. Split the dataset into training, validation, & test sets
Once the annotation is done, the dataset can now be divided into training, validation, and test sets.
- The training set is used to train the model.
- The validation set is used to evaluate the performance of the model during training.
- The test set is used to evaluate the performance of the model after the training phase is complete (Metrics such as character error rate and word error rate are used with this subset of data to evaluate the output of the model).
It’s important to make sure that the 3 subsets accurately represent the data that the system will be processing. This can be done by randomly sampling the data to ensure that each set contains a similar distribution of data.
Check out this quick read to learn more about the AI training process.
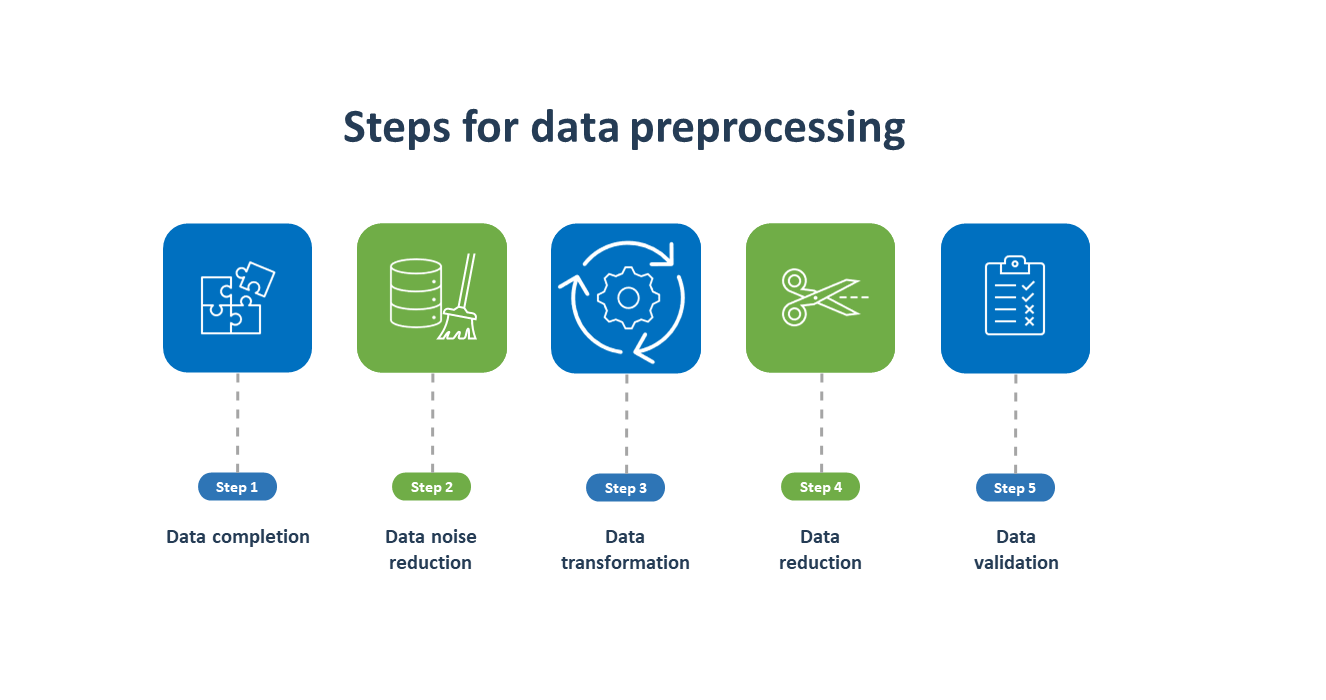
5. Preprocess the data
The data should be pre-processed to ensure that it is in the correct format and has the desired quality for training before being fed into an OCR or ICR system. Pre-processing can help to reduce or eliminate noise sources, enhance the quality of the data as a whole, and boost the system’s accuracy.
For instance, consider a scenario where the OCR system is trained to recognize handwritten text. If the input data is not pre-processed, it may contain a lot of noise, such as smudges, creases, and distortions. This noise can make the recognition process more challenging. On the other hand, if the input data has been processed to eliminate noise and improve the quality, the OCR system will be more likely to recognize the text accurately.
To learn more, check out our article on the 5 steps to data preprocessing
Conclusion
Preparing an effective dataset is crucial for training any intelligent document processing system fitted with OCR/ICR technology. By considering the best practices outlined in this article, you can ensure that the dataset covers all the features of the model and helps the system achieve the desired results.
To learn more about training data collection for AI/ML models, download our free whitepaper:
You can also check our data-driven list of data collection/harvesting services to find the best option for your project’s data needs.
Further reading
If you need help finding a vendor or have any questions, feel free to contact us:
References
- Slotta, D. (Jul 30, 2021) “Market share of optical character recognition among image recognition technology in China from 2014 to 2025” Statista. Accessed: Feb 02, 2023.

Next to Read
AI Data Collection in 2024: Guide, Challenges & Methods
Crowdsource Machine Learning: A Complete Guide in 2024
Human Generated Data Importance in 2024: Barriers & Methods
Related research

Telus International Review in 2024: Analysis & Top Alternatives

Comments
Your email address will not be published. All fields are required.