

Computer vision (CV) technology is advancing rapidly in various industries. As demand for computer vision systems rises, so does the need for well-trained models. These models require large, high-quality, accurately labeled datasets, which can be costly and time-consuming to collect.
See the seven essential steps for collecting and building training datasets for computer vision models, aiding developers and business leaders in training and implementing robust models in their businesses.
1. Understanding your data requirements
The type of computer vision model you’re developing
The type of computer vision model can vary from project to project. You can choose from the following:
- Image segmentation: This type of system involves breaking down an image into its main components, such as shapes and objects. Image segmentation systems are useful for tasks such as classifying different objects in an image or finding features within the image.
- Image classification: Image classification is designed to take an image or set of images and classify them into a predetermined set of categories.
- Object detection: This computer vision system is designed to detect objects in an image. It can be used to identify faces, cars, or other items of interest.
- Facial recognition: A facial recognition system is developed to recognize and identify faces from images. It is commonly used in security systems, as it can be used to detect intruders or unauthorized individuals accessing a facility.
- Edge detection: Edge detection computer vision systems are used to identify the boundaries of objects in an image. This type of system is useful for tasks such as identifying roads, sidewalks, or other features in an image.
- Pattern detection: These systems are designed to identify patterns or specific features in an image. They are commonly used for tasks such as recognizing text in an image or detecting a specific color.
The kind of training images or videos you’ll use
This involves the type of visual data that will be used. For instance, a quality inspection system for car parts can not be trained with image datasets of food. Data types can be:
- Images of faces for a facial recognition system
- Images of roads/streets for a self-driving system
- Videos of people walking on a street for a surveillance system, etc.
The kind of object (or objects) you’re aiming for your model to detect
You need to consider what kind of objects your computer vision system needs to detect. If it needs to detect pedestrians, it will require image or video datasets of people walking on sidewalks or while crossing the road.
The environment in which your model operates
This is taken into account to ensure that the system will work well in real-world circumstances. This is due to the fact that environmental factors like lighting, background clutter, and object occlusion can significantly affect how well a computer vision system performs.
The system can be trained to recognize objects and features under comparable circumstances and more effectively deal with difficulties like changes in lighting and background clutter. This is done by collecting training data that properly simulates the environment in which the system will be used.
2. Selecting the right data collection method
For a computer vision system, the method used to collect the data is crucial because it has a direct impact on the quantity, quality, and variability of the whole dataset. Making sure that the computer vision system can learn from a variety of representative data is essential for producing accurate predictions and results. You can choose from the following methods:
- Crowdsourcing: Crowdsourcing is an effective method for collecting large and diverse image or video datasets in a limited period of time.
- In-house / Private collection: In-house data collection, which is relatively expensive but offers highly personalized datasets.
- Off-the-shelf datasets: Readily available datasets that are much cheaper than other methods but offer a limited level of quality.
- Automated data collection: Data collection automation is the quickest method of collecting large-scale secondary online images and videos to create training datasets.
- Generative AI: Generative AI tools create different types of content, such as text, images, and audio. For machine learning models, these tools can produce new data or augment existing data to enhance performance.
- RLHF: Reinforcement Learning from Human Feedback (RLHF) trains machine learning models using human feedback instead of traditional reward signals from an environment.
3. Preparing high-quality data
One of the most important steps in building training data for computer vision models is collecting high-quality data. This includes ensuring that the images and videos you collect are:
Diversity
To increase the robustness of the model to variations in the real-world environment, make sure the data collection contains a diverse range of objects, positions, lighting settings, and backgrounds.
Annotation quality
To clearly and precisely recognize the location and class of objects in the photos or videos, the data should be annotated with accurate labels, bounding boxes, or masks.
Comprehensive
The data gathered should accurately represent the environment in which the system will function, with a focus on the specific objects and features that are relevant to the project.
Balanced
Make sure that the dataset is balanced, with a similar number of images or videos for each class of object, to avoid biases in the model towards certain classes.
Quality of images/videos
The images and videos should have good resolution and be free from distortions such as blur, noise, and compression that could negatively impact the model’s performance. You also need to make sure that the images are authentic and not altered through digital software such as Photoshop.
4. Labeling your data

Data annotation or labeling provides the computer vision system with labeled and readable examples to learn from, allowing it to predict new, unseen data accurately. You can consider the following factors:
Annotation guidelines
Create precise and concise annotation guidelines that outline the data to be labeled, how to label it, and examples to aid annotators in understanding the optimal results. Additionally, ensure the object classes and attributes that need to be annotated are clearly defined, and all annotators are on the same page.
Annotator quality
Choose annotators with experience in the relevant fields/domains, and keep an eye on performance. For instance, not anyone can perform medical image annotation, they require a specific level of experience.
Annotation tools
Select tools that are compatible with the desired annotation format and facilitate efficient annotation. Leverage automated data labeling if necessary.
Quality control
Implement routine quality checks to monitor annotator performance, ensure consistent annotations of each data point, and spot and correct errors.
Leverage the human-in-the-loop approach: Use a combination of human annotators and automated tools to get the best results.
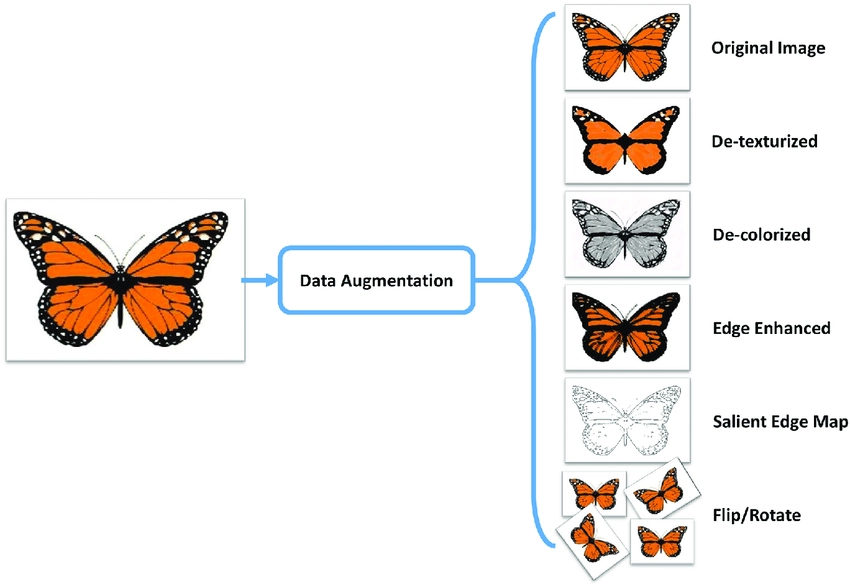
5. Augmenting your data
Data augmentation is the process of creating new training data by manipulating existing image data. This can include techniques such as:
- Rotating, flipping, and cropping images
- Adding noise or blur to images
- Using color or brightness adjustments
The goal is to artificially increase the size of the training dataset and reduce overfitting, which occurs when a model is too closely fit to the training data, leading to poor generalization to new data.
Here is an example:
6. Validating and testing
To make sure your data will be useful for training your computer vision model, validate and test it after you’ve collected and labeled it. This can be done through techniques such as:
- Split your data into training and validation sets.
- Use cross-validation to ensure your data is representative.
- Test your computer vision model on real-world data to ensure it generalizes well.
This is done to ensure the model is correctly learning and to avoid AI overfitting. During training, the model’s performance is measured on a different, unknown dataset. Validation and testing both contribute to ensuring the model’s quality and its capacity to generalize to new data.
7. Continuous training & maintenance
Over time, the data will change, which can lead to model drift. To ensure high model performance, model accuracy needs to be monitored. The model needs to be either:
- Retrained when its performance degrades
- Continuously trained thanks to human in the loop.
FAQs
-
What is a computer vision tool?
A computer vision tool is software used to process, analyze, and interpret visual data, aiding in tasks like image recognition, object detection, and data annotation.
-
Why does a CV need data?
At the core of computer vision projects are computer vision models, which are trained on large datasets of image data or video data. These models rely heavily on high-quality training data for computer vision, where labeled data—such as images annotated with bounding boxes for object detection or class labels for image classification—is used. The process of data labeling, or image annotation, is crucial for creating a quality dataset, as it allows the computer vision algorithm to learn and recognize images accurately. Public datasets and popular image databases often serve as valuable data sources, though internal resources and data collection efforts are also critical. Data annotation tools aid in this task, ensuring that the raw data is properly prepared and annotated to meet the needs of the specific model architecture being trained.
In a computer vision project, the model training phase involves using this labeled data to teach the machine learning models to identify and analyze the target objects within the image datasets. Techniques such as supervised learning and active learning help improve model performance by refining the model’s ability to accurately reflect real-world data and desired objects. Sometimes, creating synthetic data or using a diverse set of real images can augment training datasets, addressing the challenge of acquiring sufficient high-quality data points. As the models trained on these datasets are fine-tuned, anomaly detection, image segmentation, and facial recognition become possible. However, achieving a quality dataset is time-consuming and often requires balancing labeled and unlabeled data to train AI models effectively. Ultimately, the success of a computer vision model depends on the quality of the data preparation, the size of the dataset, and the particular model’s ability to perform with the data it has been given. -
How much data does computer vision use?
As a general rule of thumb in computer vision, having 1000 images per class is typically sufficient. This requirement can be considerably reduced if pre-trained models are utilized.1
Further reading
If you need help finding a vendor or have any questions, feel free to contact us:



Comments
Your email address will not be published. All fields are required.