In-Depth Guide to Data Versioning: Benefits & Formats in 2024


Companies rely on AI/ML models to make business decisions. Effective AI/ML models require high-quality data to make accurate predictions about future conditions. That’s why data is called the new oil for which successful companies need their own refinery.
However, obtaining high-quality data is not a simple matter. As the figure below shows, it involves many important steps, one of which is versioning the data.

What is data versioning?
Data versioning is the storage of different versions of data that were created or changed at specific points in times.
There are many different reasons for making changes to the data. Data scientists might test the ML models to increase efficiency and therefore make certain changes to the dataset. Datasets can also change over time due to the flow of information. Thus, storing older versions of data can help organizations replicate the previous environment.
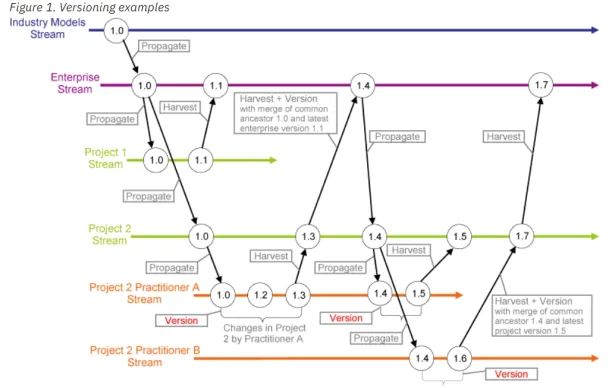
3 Benefits of data versioning
Thanks to data versioning, the old versions of data is saved and kept at the company’s disposal. This process can provide the following benefits:
1. Preserving the working version while testing
AI/ML models work with the goal of maximizing business efficiency. It is normal for development teams to test new ways to increase efficiency. Introducing a new dataset into systems could be one of those exercises. However, in search of the uncertain better, no one wants to risk the previous working version. Not surprisingly, most of the engineers’ attempts end up as inefficient trials. Therefore, engineers save the previous dataset. If an attempt fails, they simply reload the old working data set into the pipeline, preventing potential loss of business.
2. Measuring the business performance
Without the intervention of engineers, datasets can change over time. Sales data, for example, is changed by each transaction. Storing sales data from different years over a period of time can be insightful for businesses to understand consumer preferences. Consequently, versioning data can lead to a more profitable business.
Consider a food company that supplies both plant-based and animal-based foods. By versioning sales data, this company can see the consumer trend from animal to plant-based foods over time. Therefore, the firm can allocate its investment projects, marketing expenditures, and product catalog according to this information.
3. Compliance and auditing benefits
Data versioning can help with both internal and external audits and compliance processes by ensuring data is stored from specific times. Also, some data protection regulations, such as the GDPR, force companies to store certain data sources. Data versioning can save companies’ time in meeting such requirements. It can also be easier for companies to detect fraud if they have versioned their data.
What are the main formats for data versioning?
There is no standard model for data versioning, but there are some common formats that are widely used:
- The three-part semantic version number convention is the most common format for indicating different versions. For example, 3.2.4 indicates a specific data version. The left-hand side number (3) indicates a significant change between data versions. The middle number (2) indicates new features in a compatible manner, and the right-hand side number (4) indicates minor bug fixes compared to older versions.
- Naming data versions depending on their status is also possible. For example, a dataset could be incomplete-complete, filtered-unfiltered, cleaned-uncleaned, etc. Specifying this information could be helpful for practitioners, especially when they work together on a dataset via a cloud system.
- Data version can be named subject to the latest process it is exposed to. For instance, normalized or adjusted according to something etc.
What are the options for versioning the data?
There are two main options for data versioning. You can either use file versioning or outsource/build a software system that meets your company’s data engineering needs.
File versioning
Manually saving versions to your computer is one of the options for data versioning. File versioning is appropriate for:
- Small firms: Small firms with only a few data engineers or scientists working in the same location.
- Protecting sensitive information: If data contains particularly sensitive information, it should be viewed and interpreted only by a few executives and data engineers.
- Individual work: If the task is not suitable for teamwork, where different people cannot work together to achieve a final goal.
Using a data versioning tool
Specialized tools offer an alternative to file versioning. You can either develop your own software or outsource it. There are a number of providers offering such services, such as DVC, Delta Lake, and Pachyderm.
Data versioning tools are more suitable for companies that need:
- Real-time editing: If more than one person is working on a dataset, using a specialized tool is more efficient. This is because file versioning does not allow real-time editing with a group of people.
- Collaboration from different locations: When people need to collaborate in different locations, using a software is more efficient than file versioning.
- Accountability: Data versioning software makes it possible to determine in which steps errors occur and who makes the error. Consequently, the accountability of the team is enhanced.
What are the challenges to data versioning?
Versioning data consumes storage space, leads to some data security issues, and, since the use of cloud software systems is widespread, brings with it the difficulty of choosing the right provider.
Limited storage space
Each versioning of data means that more storage space is required. For companies that produce or use large amounts of data, it would therefore be costly to version the data too often. It is important for companies to find an optimal balance between the benefits of versioning and the costs incurred by storage.
Security issues
Ensuring data security is essential for businesses to protect their reputation. However, as more and more versions of data are stored, the risk of data loss or leakage increases. For cloud users, in particular, this risk is even greater as they simply outsource their IT functions, giving them less control over their data. It is important for organizations to assess and understand this risk in order to determine an optimal data versioning strategy.
To enhance your corporate cybersecurity posture you can read our Top 8 Cybersecurity Best Practices for Corporations article.
Choosing the right provider
If you decide to use a data versioning tool, you want to choose the most suitable option that meets your business requirements.
Different cloud providers offer different features and charge different prices. Therefore, it is advisable to evaluate the different options you have in order to ensure cloud cost optimization. You should compare the tools according to the following criteria:
- Open source or not
- Storage capacity
- Has a user friendly interface or not
- Support of most common clouds (like AWS) and storage types or not
- Cost
For more on data:
- Modernize Your Way of Data Management to be Competitive
- Data anonymization: Overview, Pros, Cons & Techniques
Also, read our articles on data quality assurance and training data platforms to learn more about maintaining data quality. If you need help finding a vendor to help you with data-related challenges, we can guide you.
This article was drafted by former AIMultiple industry analyst Görkem Gençer.

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
The Ultimate Guide to ETL Pipeline in 2024
Audio Annotation in 2024: What is it & why is it important?
Related research

Comments
Your email address will not be published. All fields are required.