7 Chatbot Training Data Preparation Best Practices in 2024


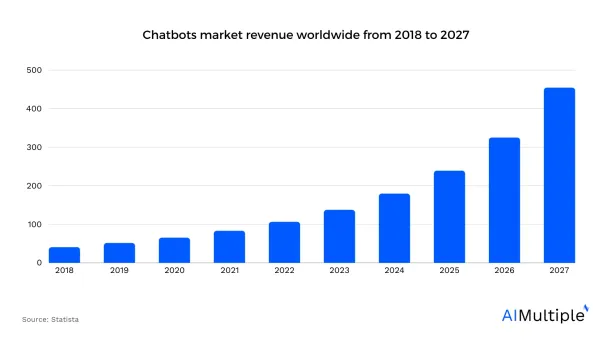
Chatbots leverage natural language processing (NLP) to create and understand human-like conversations. Chatbots and conversational AI have revolutionized the way businesses interact with customers, allowing them to offer a faster, more efficient, and more personalized customer experience. As more companies adopt chatbots, the technology’s global market grows (see Figure 1).
However, developing chatbots requires large volumes of training data, for which companies have to either rely on data collection services or prepare their own datasets.
In this article, we’ll provide 7 best practices for preparing a robust dataset to train and improve an AI-powered chatbot to help businesses successfully leverage the technology.
If you are not interested in collecting your own data, here is a list of datasets for training conversational AI.
Table 1. Datasets for training conversational AI
| Domain / Source of Dataset | Dataset Name | Description | Free / Paid |
|---|---|---|---|
| Custom human-generated datasets | Clickworker | Freshly collected/generated data via a 4.5+ million crowd | Paid |
| Custom human-generated datasets | Appen | Freshly collected/generated data via a 1+ million crowd | Paid |
| Custom human-generated datasets | Amazon Mechanical Turk | Freshly collected/generated data via a 0.5+ million crowd | Paid |
| Custom human-generated datasets | Telus International | Freshly collected/generated data via a 1+ million crowd | Paid |
| Cornell University | Cornell Movie-Dialogs Corpus | Open-source. 220,000+ conversations from movies | Free |
| McGill University & MILA | The Ubuntu Dialogue Corpus | Open-source. Around 1 million multi-turn dialogues | Free |
| OpenSubtitles organization | OpenSubtitles | Over 200,000 subtitles | Free |
| Google’s BigQuery platform | Reddit Comment Dataset | Comments from the Reddit | Free |
| Microsoft | Microsoft Bot Framework’s Persona-based Conversations Dataset | Persona-based Conversations | Free |
| Natural Language Processing (NLP) | Amazon reviews dataset | Dataset includes product reviews and Meta Data | Free |
| Natural Language Processing (NLP) | The Big Bad NLP Database (BBNLPDB) | Over 300 datasets for NLP models | Free |
| Natural Language Processing (NLP) | Wikipedia Links data | Cross-document coreference dataset labeled via links to Wikipedia | Free |
| Others | GitHub | A comprehensive list of datasets | Free & Paid |
Notes
- If we missed any datasets, the last row of the table has a comprehensive list of free and paid datasets.
- This list is made from data gathered from the websites of the datasets.
- The quantities mentioned in the description column might change with time.
Figure 1. The global chatbot market projections for 20271
1. Determine the chatbot’s target purpose & capabilities
To prepare an accurate dataset, you need to know the chatbot’s:
- Purpose: This helps in collecting relevant data and creating the conversation flow, and collecting task-oriented dialog data. For instance, a chatbot that manages customers of a restaurant might tackle conversations related to:
- Taking orders
- Making reservations
- Providing the menu
- Offering recommendations
- Taking complaints, etc.
- Medium: For example, If you need a voice bot, you need completely different training data compared to the training data for a text-based bot.
- Languages: For example, multilingual data may need to be incorporated into the dataset.
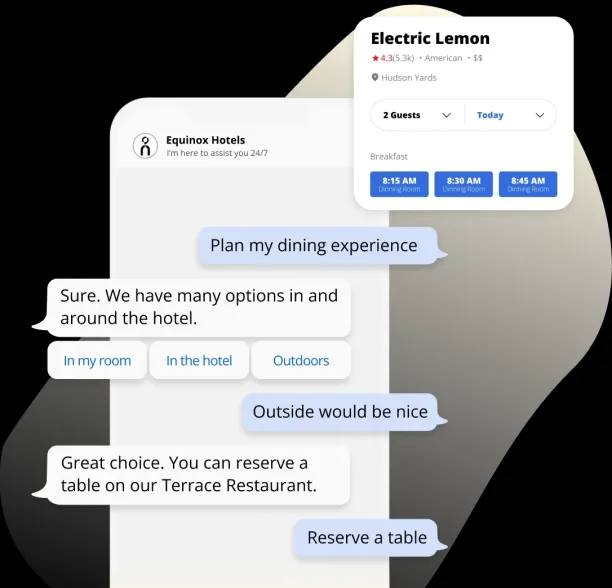
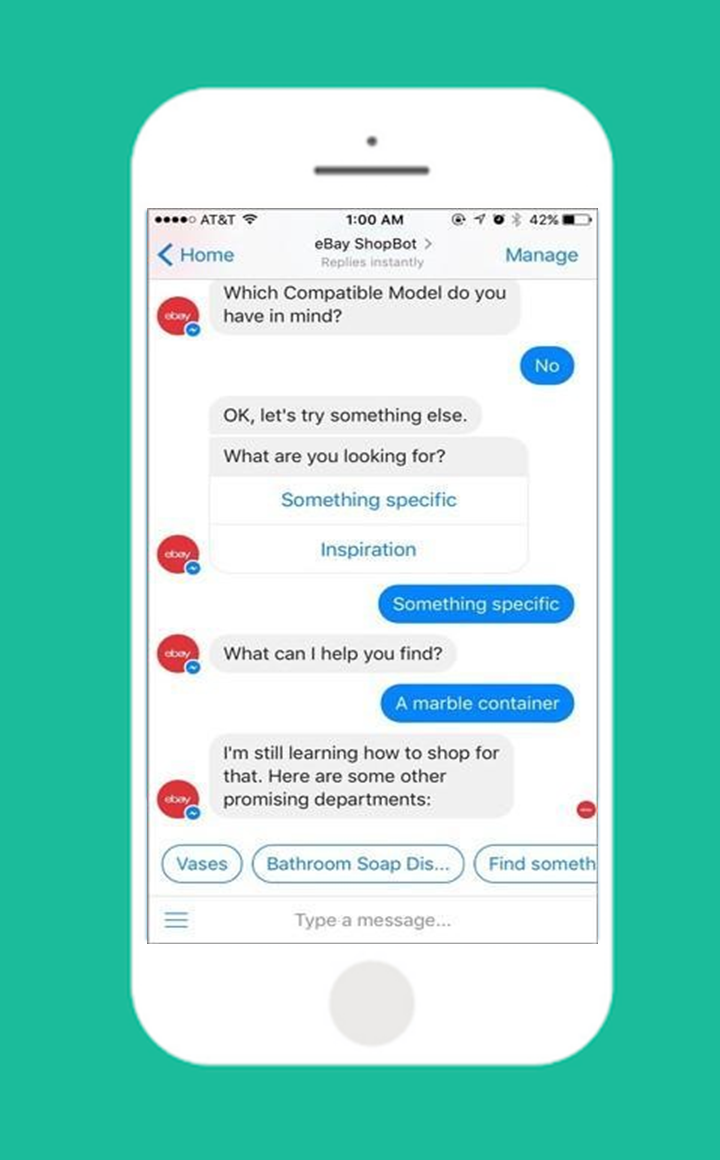
Here is an example conversation of a restaurant chatbot and what type of questions it must tackle (See figure below):2
2. Collect relevant data
The next step is to collect data relevant to the domain the chatbot will operate in. Since chabots are machine learning based systems, data collection is one of the most important steps in preparing the dataset because that is where the data comes from. Chatbot training requires a combination of primary and secondary data, including
- Different variations of questions
- Question answer datasets from multiple domains
- Dialogue datasets
- Customer support data
- Written conversations and conversation logs
- Transcripts of previous customer interactions
- Emails in different formats
- Social media messages
- Feedback forms
- multilingual chatbot training datasets
- Wikipedia articles
It is also important to consider the method of data collection since it can impact the quality of the dataset. Every method differs in quality, cost, and flexibility, so you need to align these factors with your project requirements. You can:
- Opt for private or in-house data collection if you can spare the budget and time and require a high level of data privacy. For instance, a patient management chatbot might work with sensitive data and, therefore, would be better suited to in-house collection of patient support datasets.
- If the chatbot requires a large amount of multilingual data, then crowdsourcing can be a suitable option. This is mainly because it offers quick access to a large pool of talent and is relatively cheaper than in-house data collection.
- You can avoid using pre-packaged or open-source datasets if quality and customization are important to your chatbot.
Check out this article to learn more about different data collection methods.
2.1. Partner with a data crowdsourcing service
If you do not wish to use ready-made datasets and do not want to go through the hassle of preparing your own dataset, you can also work with a crowdsourcing service. Working with a data crowdsourcing platform or service offers a streamlined approach to gathering diverse datasets for training conversational AI models. These platforms harness the power of a large number of contributors, often from varied linguistic, cultural, and geographical backgrounds. This diversity enriches the dataset with a wide range of linguistic styles, dialects, and idiomatic expressions, making the AI more versatile and adaptable to different users and scenarios.
Moreover, crowdsourcing can rapidly scale the data collection process, allowing for the accumulation of large volumes of data in a relatively short period. This accelerated gathering of data is crucial for the iterative development and refinement of AI models, ensuring they are trained on up-to-date and representative language samples. As a result, conversational AI becomes more robust, accurate, and capable of understanding and responding to a broader spectrum of human interactions.
3. Categorize the data
After gathering the data, it needs to be categorized based on topics and intents. This can either be done manually or with the help of natural language processing (NLP) tools. Data categorization helps structure the data so that it can be used to train the chatbot to recognize specific topics and intents. For example, a travel agency could categorize the data into topics like hotels, flights, car rentals, etc.
You can consider the following 5 steps while categorizing your data:
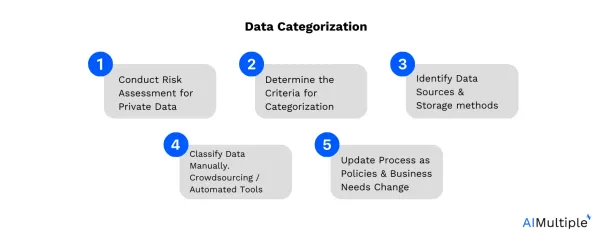
Check out this article to learn more about data categorization.
While categorizing the data, to further improve the quality of the data, you can also preprocess it with the following 5 steps:
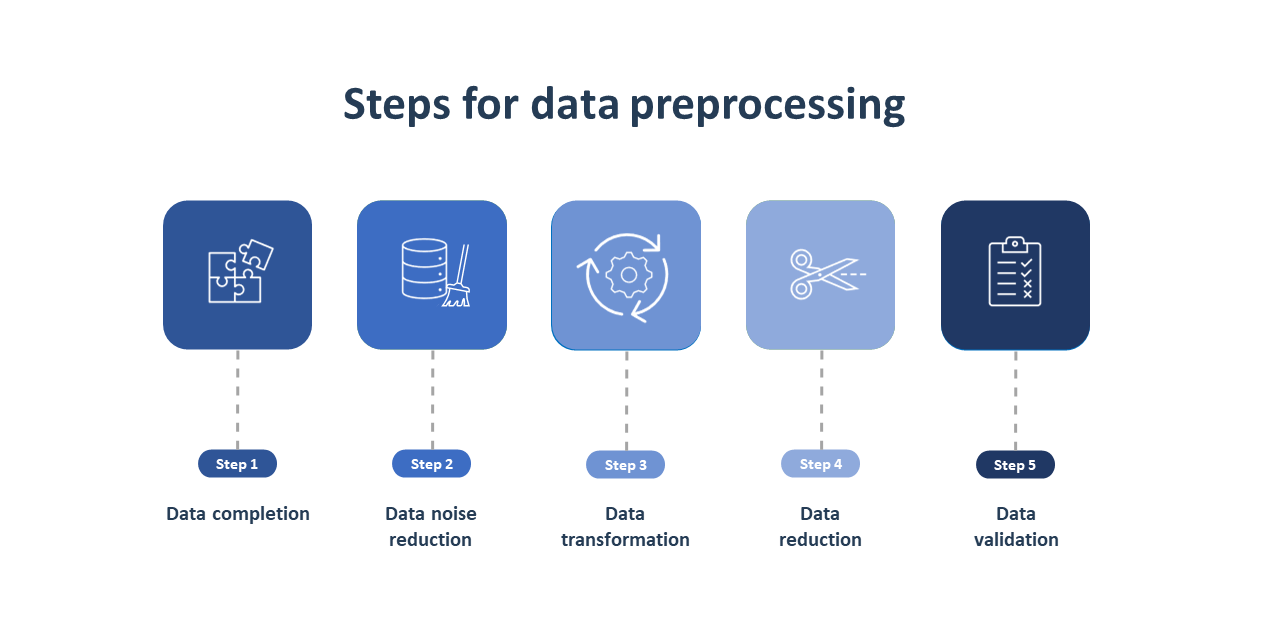
Click here to learn more about data preprocessing.
4. Annotate the data
After categorization, the next important step is data annotation or labeling. Labels help conversational AI models such as chatbots and virtual assistants in identifying the intent and meaning of the customer’s message. This can be done manually or by using automated data labeling tools. In both cases, human annotators need to be hired to ensure a human-in-the-loop approach. For example, a bank could label data into intents like account balance, transaction history, credit card statements, etc.
Some examples of intent labels in banking:

You can also check our data-driven list of data labeling/classification/tagging services to find the option that best suits your project needs.
5. Balance the data
To make sure that the chatbot is not biased toward specific topics or intents, the dataset should be balanced and comprehensive. The data should be representative of all the topics the chatbot will be required to cover and should enable the chatbot to respond to the maximum number of user requests.
For example, consider a chatbot working for an e-commerce business. If it is not trained to provide the measurements of a certain product, the customer would want to switch to a live agent or would leave altogether.
6. Update the dataset regularly
Like any other AI-powered technology, the performance of chatbots also degrades over time. The chatbots that are present in the current market can handle much more complex conversations as compared to the ones available 5 years ago.
Chatbot training is an ongoing process. Therefore, the existing chatbot training dataset should continuously be updated with new data to improve the chatbot’s performance as its performance level starts to fall. The improved data can include new customer interactions, feedback, and changes in the business’s offerings.
For example, customers now want their chatbot to be more human-like and have a character. This will require fresh data with more variations of responses. Also, sometimes some terminologies become obsolete over time or become offensive. In that case, the chatbot should be trained with new data to learn those trends.Check out this article to learn more about how to improve AI/ML models.
7. Test the dataset
Before using the dataset for chatbot training, it’s important to test it to check the accuracy of the responses. This can be done by using a small subset of the whole dataset to train the chatbot and testing its performance on an unseen set of data. This will help in identifying any gaps or shortcomings in the dataset, which will ultimately result in a better-performing chatbot.
Click here if you wish to learn more about how to test an AI model.
Transparency statement
AIMultiple serves numerous emerging tech companies, including the ones linked in this article.
Further reading
- Chatbot Pricing – Complete Guide
- Chatbot vs Intelligent Virtual Assistant: Use cases Comparison
- Audio Data Collection for AI: Challenges & Best Practices
- Data Labeling For Natural Language Processing (NLP)
If you need help finding a vendor or have any questions, feel free to contact us:
External resources
- 1. Chatbot market revenue worldwide. Statista. Accessed: 22/December/2023.
- 2. Restaurant chatbot screenshot. Haptik. Accessed: 25/December/2023.

Next to Read
Data Interoperability & Machine Learning in 2024 & Beyond
Top 16 Retail Workload Automation Benefits in 2024
Top 3 Hive Alternatives & Their Evaluations in 2024
Related research


Comments
Your email address will not be published. All fields are required.