How to Scrape Amazon Product Data & Reviews in 2024
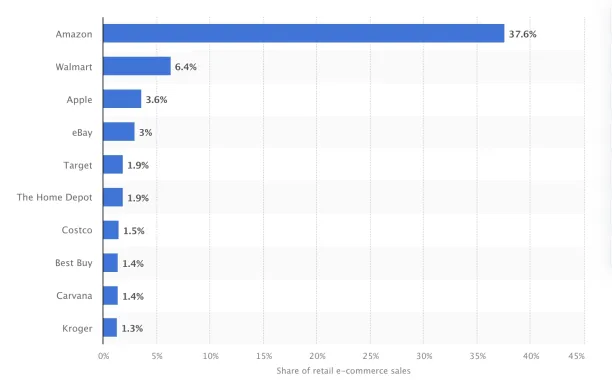
Amazon is the largest e-commerce company in the US, accounting for 41% of e-commerce retail sales (see Figure 1). 1 This makes it as a rich data source for retailers, marketers, and businesses. This data can be used for price monitoring, inventory management, and product trend analysis.
Web scraping services enable users to automatically collect publicly available data from e-commerce websites. However, scraping large and well-protected websites like Amazon can raise legal and ethical considerations. This article explores methods for scraping product and review data from Amazon in a legal and ethical way.
We’ve selected data collection services that are specifically intended to meet the requirements of Amazon data extraction. Check out to see which Amazon scraper is the best fit for your specific requirements.
This article is intended for informational purposes and should not be taken as legal advice. For any data scraping projects, we recommend seeking legal advice.
Figure 1: Market share of leading retail e-commerce companies in the US as of 2021
Scraping Amazon Product Data: A Step-By-Step Guide
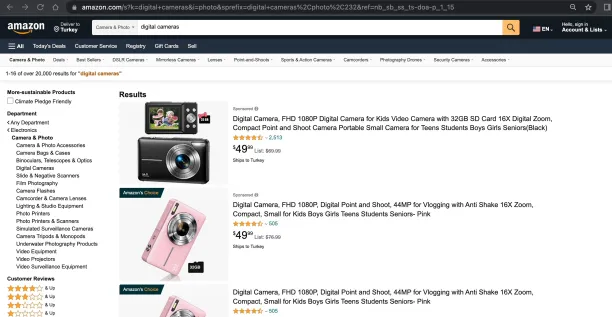
You can extract product data from Amazon’s product search pages or directly from the individual product pages. Amazon search result pages contain product information such as product rating, pricing, and image URL. If you intend to scrape basic product data, it’s more efficient to scrape it from product search pages rather than from each individual product page. This approach will reduce the number of request you need to send to Amazon.
1.Identify the data you want to extract: To understand how Amazon URLs are structured, you can conduct a keyword search on Amazon. When you search for a product on Amazon, the Amazon product URL has the following structure:
“https://www.amazon.com/s?k=[keywords]&page=[page_number]”
- [keywords] stands for the search term you used.
- [page_number] is the number of page you are on.
Another way to identify product URLs for your scraper to extract product data is to crawl Amazon for ASIN (Amazon Standard Identification Number). ASIN is a unique identifier of 10-character alphanumeric for a product. It is mostly located in the product details page on Amazon.
However, the systematic collection of ASINs without explicit permission can violate Amazon’s terms of service. You can use Amazon Product Advertising API to access product details like URLs legally.
2.Set up a Python web scraping environment: You will need to install Python if you haven’t already. Then, install the required library for Amazon web scraping. For instance, Beautiful Soup, Selenium and Requests are commonly used Python scraping libraries.
Amazon uses a combination of HTML and JavaScript for its content. You would likely need a scraping library that handles both static and dynamic content like Selenium. Product recommendations, and user reviews are example of dynamic content that are often handled by JavaScript. Product image, title, and price are examples of static information.
3. Inspect the web page: Right-click on the part of the target web page, then click on “Inspect” to open the developer tools. You can identify the HTML tags that contain the data you need. You can only see HTML elements and its attributes in the developer tools. However, if the data you want to extract is loaded with JavaScript, you will need to look at the Network tab of the developer tools. It includes all the requests your browser made to load the web page, including JavaScript files and AJAX requests.
4. Write script: You will need to request the product page using either the product URL or its ASIN code. Here is an example of Amazon product ASIN code: https://www.amazon.com/dp/ASIN_CODE
Once you have the HTML code of the target product page, you need to parse the HTML using BeautifulSoup. It enables users to find the data they want in the parsed HTML content.
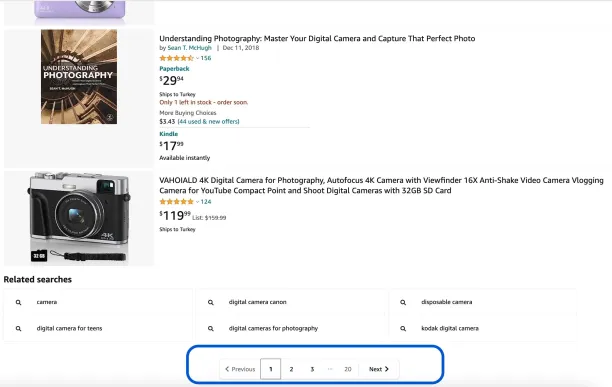
5. Handle pagination: Amazon product and review pages usually contain a link to go the next page. Pagination present challenges for web scraping tools, as it requires interaction with the page. Most no-code web scrapers handle pagination automatically. If you build your Amazon scraper using web scraping libraries, you should identify the next page link and request it to repeat the data extraction process.
Use a web scraper bot to crawl data instead of a RPA bot
There are several ways to scrape a website. A web scraper or an RPA bot is one of the methods to scrape publicly available e-commerce data. How can RPA be used to automate web scraping?
- Identify the target URLs they want to scrape,
- Scroll through multiple pages and find relevant data,
- Write code (e.g. python) or use an extension to extract specific data such as texts, images, and videos,
- Transform it into the required format.
However, it is not the best option for scrolling and scraping product web pages because of the load more button. Some e-commerce websites load product data in parts and allow users to explore more products by clicking the load more button. Instead of investigating further products, the bot stops extracting data at the end of the page.
Top Amazon scraping tools
To compare vendors in detail, check out the Top 7 Amazon Scrapers for Collecting Data from Amazon.
| Vendors | Pricing | Free trial |
|---|---|---|
| Bright Data | $500 | 7-day |
| Smartproxy | $50 | 3k requests for free |
| Oxylabs | $49 | 7-day |
Nimble | $600 | 7-day |
| Apify | $40 | 14-day |
| Infatica | $27 | 3-day |
| WebScrapingAPI | $44 | Free plan |
| DataOx | Customized prices | N/A |
Which Amazon data can you scrape?
- Monitoring competitors’ products: Amazon offers the largest range of products among online resources. Competitors’ product lists can be extracted and monitored on a regular basis with a web scraping bot. Stock availability, vendors, and ratings are some examples of product data that can be collected from Amazon.
- Products’ review: Extracting your product reviews from Amazon product web pages and analyzing them helps you better understand the pain points of your customers and their purchase behavior. You can also scroll and collect reviews of your competitors’ products. It will allow you to estimate the success or failure of launching a new product or improving an existing one.
Read more about review scraping: The Ultimate Guide to Review Scraping
Sponsored:
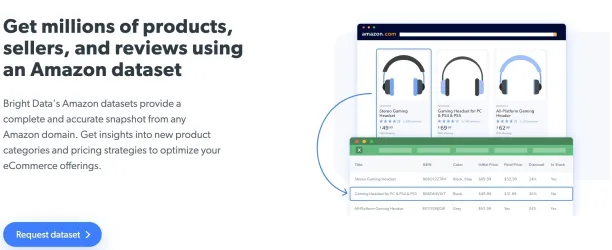
Bright Data’s Data Collector scrapes Amazon product data and reviews automatically. It collects and parses all real-time product and category data such as product description, ASIN, seller name, price, features, ratings, and reviews.
- Prices: Knowing competitors’ pricing is a necessity for companies to set optimal prices and increase their revenues. Dynamic pricing is used by retailers, especially e-commerce companies such as Amazon and eBay. Pricing for products and services is dynamically adjusted in response to market conditions such as supply and demand, competitive pricing, and so on. A web scraping bot extracts real-time public data from eCommerce platforms and delivers it in a structured, ready-to-analyze format.
For example, Amazon Personalize enables customers to develop digital personalized stores that include personalized product recommendations, customized direct marketing, and personalized product re-ranking. Companies can make personalized product suggestions to their customers and offer personalized prices based on their purchase habits. This creates a dynamic pricing environment for suppliers on Amazon.
The best approach for gathering data depends on your specific requirements. However, if you’re looking for a time and cost efficiency way to obtain data, ready-use datasets provides immediate availability and reduces data preparation time. Bright Data offers ready-use Amazon datasets including various data points such as reviews, prices, products, and sellers.
Use Cases of Amazon Data
1. Price comparison
Web scraping allows companies, particularly those in the e-commerce industry, to extract relevant data from Amazon pages on a weekly or monthly basis. Companies can set their prices to stay competitive by tracking competitors’ product prices online. Not tracking pricing changes in the market, especially during peak seasons, can result in the loss of large volumes of online sales and a competitive disadvantage.
For suppliers, however, collecting competitors’ price information from hundreds of Amazon product web pages is difficult. Companies must consider the dynamic website structure of Amazon when scraping product information. For example, dynamic websites often require input from the user to load the specified information. In this case, you must provide all the required input on the website. Here are the main steps of scraping price information from a targeted website:
- First, a scraper bot needs access to the target website at certain times.
- After gaining access, it tracks website activity to monitor price changes.
- The bot scrolls and extracts relevant pricing data from the website and then converts it into spreadsheets or databases.
Sponsored
Oxylabs provides an Amazon scraper API for scraping and parsing different Amazon page types, such as listing, product, and category pages. You can extract realtime product data, Amazon search results, and public pricing data.

2. Demand forecasting
Companies can use a web scraper bot to harvest real-time and historical data to track interest in a product on Amazon and analyze it to estimate demand.
Demand forecasting helps companies to improve their supply chain with real-time demand analysis. It allows companies to make their products available on Amazon’s product pages at any time. It assists them in properly managing their stock.
Cash-in-stock is a potential problem for online sales. Products can sometimes go unsold for longer than expected, resulting in increased inventory costs. In this case, companies set their products’ prices lower than the market competition. Such circumstances can be avoided with precise demand forecasting.
3. Improving product profile
Businesses can extract various product details from Amazon product web pages such as price, descriptions, ratings, ranks, and reviews. Extracting and monitoring product reviews enables companies to identify their weaknesses and strengths. It is also a useful approach to performing competitive analysis. Businesses can gain a better knowledge of their product positioning and market trends by tracking competitor product reviews. Here is an outline of the steps for an efficient competitor analysis:
- Make a list of your competitors in your market.
- Collect relevant and useful information on competitors, such as the size of their company, their locations, their unique selling point (USP), and so on.
- Determine how the target customers are different or similar to yours.
- Gather information about their product by asking the following questions:
- What are they selling?
- What pricing strategy do they employ?
- What methods do they use to promote their products?
How to Bypass Amazon’s Anti-Bot Protection
Web scraping Amazon can pose multiple challenges for web scrapers:
- Bulk scraping: When you intend to scrape large amounts of data, you need to send a separate request for each page. However, sending large numbers of connection requests in a short time can overload the servers and slow down the website for other visitors. It is crucial to follow legal guidelines, and keep the concurrent connections at a reasonable numbers.
- Rate limiting: Amazon has rate limits that restrict the number of requests you may make with the same IP address in a certain time period. Adding a delay between your requests or using a rotating proxy service can help you to avoid hitting the rate limit.There are many proxy types that are designed for data collection purposes.
- Anti-bot measures: Amazon uses CAPTCHAs and other anti-scraping measures to prevent automated activities, including web harvesting. Your web scraper may need to incorporate techniques to emulate human behavior. To avoid detection, you could wait a random time between you request and rotate between different different User-Agent strings.
- JavaScript rendered content: Most e-Commerce websites, such as Amazon, rely on JavaScript rendering since some of the site’s content is dynamically loaded. Some web scraping services handle JavaScript rendering using headless browsers.
- IP blockers: To prevent being blacklisted, instead of using a static IP address, you can use a dynamic IP address. Another option for scraping websites with ease is to use proxies. Most websites set a limit to minimize scraping practices. It is called a crawl rate, its main purpose is to prevent too many requests coming from a single IP address. For each access request to a scraping website, a proxy server assigns a different IP address. Businesses can integrate a proxy server with their web scraper bots to tackle this problem.
To learn about other types of the proxy server and their benefits, read our guide to proxy server types.
- Complex website structure: Web scraper bots are designed to crawl a website based on its JavaScript and HTML elements. However, when the content of the websites is changed or new features are added, these changes also cause structural changes. Scraping the new website design may be too complex.
For more on web scraping
- Web Scraping in e-Commerce: Use Cases & Challenges
- A Comprehensive Guide to Social Media Scraping
- 5 Common Web Scraping Applications in the Travel Industry
For guidance to choose the right tool, check out data-driven list of web scrapers, and reach out to us:
External Links
- 1. Chevalier, S. (Jul 10, 2023). “Market share of leading retail e-commerce companies in the United States“. Statista. Retrieved July 15, 2023

Next to Read
Top 7 eCommerce Scraping Tools of 2024: Features and Prices
Top 7 Amazon Scrapers to Gather Data From Amazon in 2024
7 Web Scraping Best Practices You Must Be Aware of in '24
Related research
Make Better Investments Than Competitors With Alternative Data
Comments
Your email address will not be published. All fields are required.