Differential Privacy for Secure Machine Learning in 2024
Training datasets of machine learning models frequently contain sensitive data from individuals. This raises concerns over data privacy because it is possible in some cases for attackers to obtain information about training data through model outcomes. For example, researchers managed to extract recognizable face images from training set with only API access to facial recognition system and person’s name. Here, recovered image is on the left and victim’s original image in the training set is on the right.

Differential privacy is a promising way to introduce privacy to machine learning models without decreasing the quality of training data or the models.
How can differential privacy help machine learning?
Differential privacy can prevent machine learning models from memorizing specific examples from the raw training data and provide protection from privacy attacks. It enhances privacy levels of traditional machine learning models and improves other privacy-preserving methods such as federated learning by:
- Input perturbation: Adding noise to the data itself. The noise can be added to individual data before collection (local differential privacy) or to the dataset after collection (global differential privacy).
- Output perturbation: Adding noise to the result of the machine learning model before model users and possible adversaries access to the output.
- Algorithm perturbation: Adding noise to the model parameters during computation.
What are the current privacy issues in machine learning?
Attackers can gain information about the training dataset which may include personal information. In most machine learning applications, we need the algorithm to learn general patterns from the training data rather than memorizing specific examples. This is important for generalization (i.e. we want to apply the learning algorithm to new datasets, not just the training data). However, when deep learning models are examined, it has been observed that they memorize (i.e. store) certain examples. This is hard to prevent since deep learning models tend to be black-box models.
If the training dataset contains sensitive information, memorization becomes a privacy concern. An attacker who has access to the results of the model, or the model itself, can get information about the training dataset with privacy attacks such as:
- Membership inference attack: Trying to determine whether an individual’s data was a part of the training dataset.
- Reconstruction attack: Trying to recreate an individual’s data in the training dataset.
- Property inference attack: Trying to extract information about the training dataset that was not explicitly encoded during the learning process.
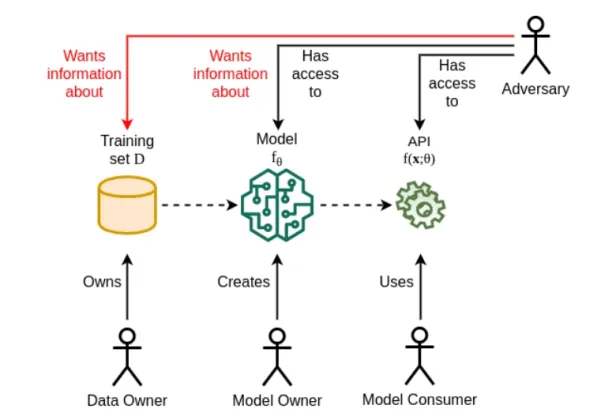
Differential privacy can protect sensitive information in the training dataset from such attacks by injecting noise through perturbation methods. Thus, memorization ceases to be a threat since memorized data points will be noisy under differential privacy.
Why is differential privacy more relevant in federated learning?
Federated learning is another privacy-preserving method in machine learning. Since federated learning is used to aggregate sensitive data from multiple sources, data privacy is especially important in federated learning applications. Differential privacy is used with federated learning to further improve data security.
With federated learning, a machine learning algorithm can learn from data that is distributed across multiple data providers. Individual data owners receive the algorithm, train it on their own data and send only the local training results. So their personal data never leaves where it originates.
Although federated learning is privacy-preserving by design, it is not immune to privacy attacks. For instance, a recent update to the central model may provide information about a data owner. This is especially a problem if the model memorizes a rare data point. Differential privacy can address this issue by adding noise to local training results before sending them to the central server.
Check our comprehensive guide for differential privacy to learn how it works and its applications.

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
Guide To Machine Learning Data Governance in 2024
4 Use Cases of Sentiment Analysis Machine Learning in 2024
Data Mining: What is it & Why do businesses need it in 2024?
Related research
Comments
Your email address will not be published. All fields are required.