Differential Privacy: How It Works, Benefits & Use Cases in 2024
Violating data privacy is costly for organizations due to factors such as diminished reputation or regulatory fines. IBM’s 2022 Cost of a Data Breach report states that the average total cost of a data breach is nearly $4.5 million. However, access to private information is required in building solutions to many important business problems.
Differential privacy provides a mathematically quantifiable way to balance data privacy and data utility. It can allow organizations to analyze and share their private data
- without revealing anyone’s sensitive information
- while complying with data privacy regulations such as GDPR or CCPA
What is differential privacy?
Differential privacy is a mathematical technique of adding a controlled amount of randomness to a dataset to prevent anyone from obtaining information about individuals in the dataset. The added randomness is controlled. Therefore, the resulting dataset is still accurate enough to generate aggregate insights through data analysis while maintaining the privacy of individual participants.
How does it work?
- Differential privacy introduces a privacy loss or privacy budget parameter, often denoted as epsilon (ε), to the dataset. ε controls how much noise or randomness is added to the raw dataset.
- For simplicity, suppose you have a column in your dataset with “Yes”/”No” answers from individuals. For every individual, you flip a coin, if it is
- heads, you leave the answer as is
- tails, you flip a coin a second time and record the answer as “Yes” if heads and “No” if tails, regardless of the real answer.
- This process adds randomness to data. For large enough data and with the information on the noise-adding mechanism, the dataset is still accurate in terms of aggregate measurements. At the same time, every single individual in the dataset can plausibly deny their real answer given the randomization.
- In real-world applications, noise-adding algorithms are a bit more complex than flipping a coin. These algorithms are based on the parameter ε, which controls the trade-off between privacy and data utility: a high value of ε means more accurate but less private data.
- Differential privacy can be implemented locally or globally. In local differential privacy, noise is added to individual data before it is centralized in a database. In global differential privacy, noise is added to raw data after it is collected from many individuals.
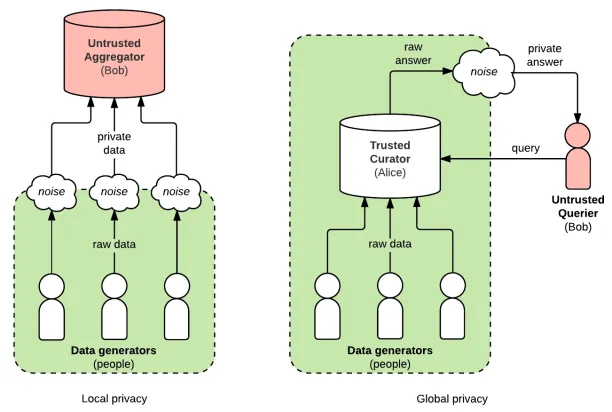
Source: Access Now
Why is it important now?
Differential privacy is important for businesses because:
- It can help businesses comply with data privacy regulations such as GDPR and CCPA without undermining their ability to analyze their customer behavior. Failure to comply with these regulations can result in serious fines. According to a 2021 report by international law firm DLA Piper, €273 million of fines have been imposed under GDPR since May 2018. These fees are a drop in the bucket if we consider the level of GDPR compliance and the size of the European economy. They are expected to increase as countries check for GDPR compliance with more comprehensive, automated approaches.
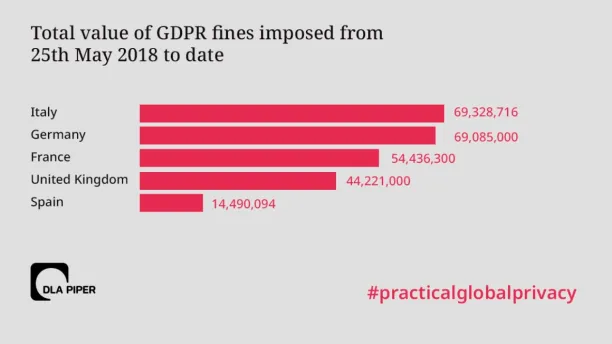
Source: DLA Piper
- Data privacy violations such as breaches also damage the reputation of businesses. The 2020 Cost of a Data Breach Report by IBM states that lost business due to factors such as diminished reputation was the largest cost factor of a data breach with a yearly average of $1.52 million. The report also states that customers’ personally identifiable information was the costliest data type to be compromised in the data breach they studied.
- Differential privacy enables businesses to share their data with other organizations to collaborate with them without risking their customers’ privacy.
What are its applications?
- U.S. Census Bureau started to use differential privacy with the 2020 Census data. The dataset contains detailed demographic information about U.S. citizens. Without a privacy measure, this information can be traced back to individuals. The Bureau states that traditional anonymization techniques became obsolete. This is because of re-identification methods that make it possible to reveal information about a specific individual from an anonymized dataset.
- In 2014, Google introduced a differential privacy tool called Randomized Aggregatable Privacy-Preserving Ordinal Response (RAPPOR) to Chrome browsers. It helps Google to analyze and draw insights from browser usage while preventing sensitive information from being traced. Google also made its differential privacy libraries open source in 2019.
- Apple uses differential privacy in iOS and macOS devices for personal data such as emojis, search queries and health information.
- Microsoft uses differential privacy for collecting telemetry data from Windows devices.
- Differential privacy is also used in applications of other privacy-preserving methods in artificial intelligence such as federated learning or synthetic data generation.
What is its advantage over other privacy measures?
Differential privacy enables organizations to customize the privacy level and leads attackers to access data that is only partially correct.
Preventing attackers from access to perfect data
Applying differentially private computation for each query separately would lead to different answers for the same query by different researchers. These different approximate answers are still meaningful for aggregate statistics and it ensures that a querier cannot reveal information specific to individual participants.
Added random noise ensures that any individual in the dataset can plausibly deny their specific information or even participation in the dataset.
This deniability aspect of differential privacy is important in cases like linkage attacks where attackers leverage multiple sources to identify the personal information of a target.
Protection from linkage attacks
A famous linkage attack is Latanya Sweeney‘s case. In 1997, when she was a graduate student at MIT, she was able to reveal Massachusetts Governor William Weld’s medical records by combining:
- an anonymized public data from an insurance agency for state employees
- voter registration records that were publicly available for a small fee
The medical record data from the insurance company was properly anonymized. However, there was only one record in the dataset that matched Weld’s gender, ZIP code, and date of birth, which were obtained from voter registration records.
This is an example of a linkage attack: re-identifying an individual from an anonymized dataset by combining it with auxiliary information from other datasets. Traditional anonymization techniques such as removing columns containing personally identifiable information or data masking can be susceptible to re-identification.
Customized privacy levels
Differential privacy provides a quantifiable measure of privacy guarantees through the parameter ε. By adjusting the value of ε, data aggregators can control the level of privacy according to the sensitivity of the dataset.
In data masking and anonymization, similar customizations are possible (e.g. by masking additional fields), however, they are not as easy to adjust as differential privacy parameter ε.
How to implement differential privacy in Python?
- Diffprivlib is a general-purpose, open-source differential privacy library by IBM.
- TensorFlow Privacy is a Python library by Google with TensorFlow optimizers for training machine learning models with differential privacy.
- PyDP is a Python wrapper for Google’s C++ Differential Privacy Library. The library provides a set of ε-differentially private algorithms to be used in producing aggregate statistics over numeric data sets. It is developed by the open-source community OpenMined.
- Opacus is a library by Facebook to train PyTorch models with differential privacy.
What are the challenges and limitations of differential privacy?
- It is not applicable to every problem:
- Individual level analysis: Such analysis is not possible with differential privacy applied data. It prevents an analyst from learning information particular to specific individuals. For example, differential privacy is not suitable for a bank that wants to determine instances of fraudulent activity.
- Small data: Similar to sampling errors, the inaccuracy introduced by differential privacy can be ignored for large datasets but it is not the case for small ones. For a small dataset, the noise added by differential privacy can seriously impact any analysis based on it.
- Correct level of ε is not clear: There is no consensus over the optimal value of ε, i.e. the level of distortion for the data to be both private and useful. ε = 0 is the perfect privacy case but it completely changes the original data and makes it useless. However, if the applications of differential privacy become prevalent, guidelines to reach this optimality for various cases may be established in the future.
Is sharing personal data with differential privacy without consent GDPR or CCPA compliant?
There is no simple answer. It depends on the dataset, applied differentially private algorithm, and the parameter ε. To be on the safe side, companies can list all processors of differential privacy applied data as data processors if data processing involves using personal data.
Differential privacy provides a way to manage the level of privacy vs utility. However, as discussed above, there is no agreement on the optimal level for this tradeoff yet. A white paper by Simons Institute at the University of California, Berkeley states that differential privacy offers a powerful alternative to overcome the limitations of traditional anonymization approaches and policymakers should work closely with researchers to formulate recommendations for it.
If you want to read more about data privacy, check our article on privacy-enhancing technologies (PETs).
If you are interested in the mathematical definition of differential privacy and its technical details, you can check Cynthia Dwork and Aaron Roth’s open-source textbook The Algorithmic Foundations of Differential Privacy. If you have other questions about differential privacy or other privacy protection methods, we can help:

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
Differential Privacy for Secure Machine Learning in 2024

“There are a few cases of scooter sailing in the map which attracted our attention”
The Hazy article explains that synthetic coordinates in the ocean are caused by differential privacy noise.
Comments
Your email address will not be published. All fields are required.