Large Language Model Evaluation in 2024: 5 Methods
Large Language Models (LLMs) have recently grown rapidly and they have the potential to lead the AI transformation. It is critical to evaluate LLMs accurately because:
- Enterprises need to choose generative AI models to adopt. There are numerous base LLMs and there are many other variations of these models.
- Once the models are chosen, they will be fine-tuned. Unless model performance is accurately measured, users can not be sure about what their efforts achieved.
Therefore, we need to identify
- Best ways to evaluate models
- Right type of data to use for model training and assessment
Because LLM evaluation is multi-dimensional, it’s important to have a comprehensive performance evaluation framework for them. This article will explore the common challenges with current evaluation methods, and propose solutions for mitigating them.
What are applications of LLM performance evaluation?
1. Performance assessment
Consider an enterprise that needs to choose between multiple models for its base enterprise generative model. These LLMs need to be evaluated to assess how well they generate text and respond to input. Performance can include metrics such as accuracy, fluency, coherence, and subject relevance.
2. Model comparison
For example, an enterprise may have fine-tuned a model for higher performance in the tasks specific to their industry. An evaluation framework helps researchers and practitioners compare LLMs and measure progress. This helps in the selection of the most appropriate model for a given application.
3. Bias detection and mitigation
LLMs have AI biases present in their training data. A comprehensive evaluation framework helps identify and measure biases in LLM outputs, allowing researchers to develop strategies for bias detection and mitigation. Understand other risks of Generative AI.
4. User satisfaction and trust:
Evaluation of user satisfaction and trust is crucial to test generative language models. Relevance, coherence, and diversity are evaluated to ensure that models match user expectations and inspire trust. This assessment framework aids in understanding the level of user satisfaction and trust in the responses generated by the models.
5 benchmarking steps for a better evaluation of LLM performance
Here is an overview of the LLM comparison and benchmarking process:
Benchmark selection:
To achieve a comprehensive evaluation of a language model’s performance, it is often necessary to employ a combination of benchmarks. A set of benchmark tasks is selected to cover a wide range of language-related challenges. These tasks may include language modeling, text completion, sentiment analysis, question answering, summarization, machine translation, and more. The benchmarks should be representative of real-world scenarios and cover diverse domains and linguistic complexities.
Explore large language model examples before benchmarking.
Dataset preparation:
Curated datasets are prepared for each benchmark task, including training, validation, and test sets. These datasets should be large enough to capture the variations in language use, domain-specific nuances, and potential biases. Careful data curation is essential to ensure high-quality and unbiased evaluation.
Model training and fine-tuning:
Models trained as Large Language Models (LLMs) undergo fine-tuning processes using suitable methodologies on benchmark datasets. A typical approach involves pre-training on extensive text corpora, like the Common Crawl or Wikipedia, followed by fine-tuning on task-specific benchmark datasets. These models can encompass various variations, including transformer-based architectures, different sizes, or alternative training strategies.
Learn about Large Language Model Training and Generative AI Coding.
Model evaluation:
The trained or fine-tuned LLM models are evaluated on the benchmark tasks using the predefined evaluation metrics. The models’ performance is measured based on their ability to generate accurate, coherent, and contextually appropriate responses for each task. The evaluation results provide insights into the strengths, weaknesses, and relative performance of the LLM models.
Comparative analysis:
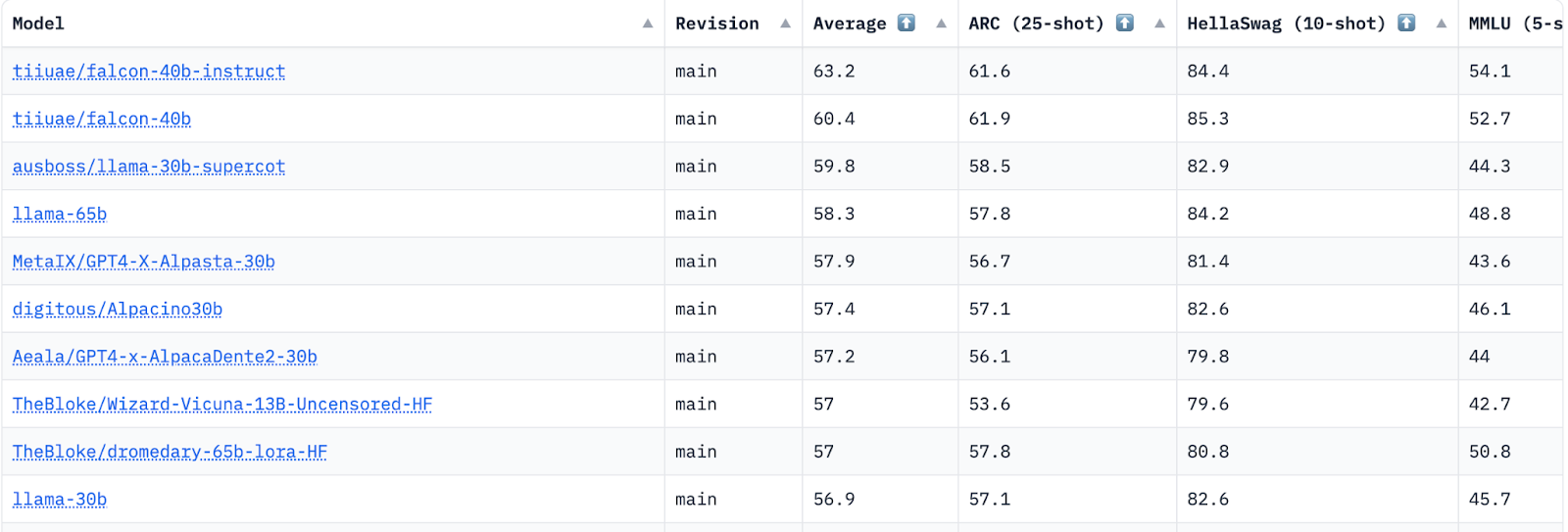
The evaluation results are analyzed to compare the performance of different LLM models on each benchmark task. Models are ranked1 based on their overall performance (Figure 1) or task-specific metrics. Comparative analysis allows researchers and practitioners to identify the state-of-the-art models, track progress over time, and understand the relative strengths of different models for specific tasks.
5 commonly used performance evaluation methods
Models can be benchmarked across many different dimensions. Commonly used evaluation dimensions for LLMs are:
- Perplexity
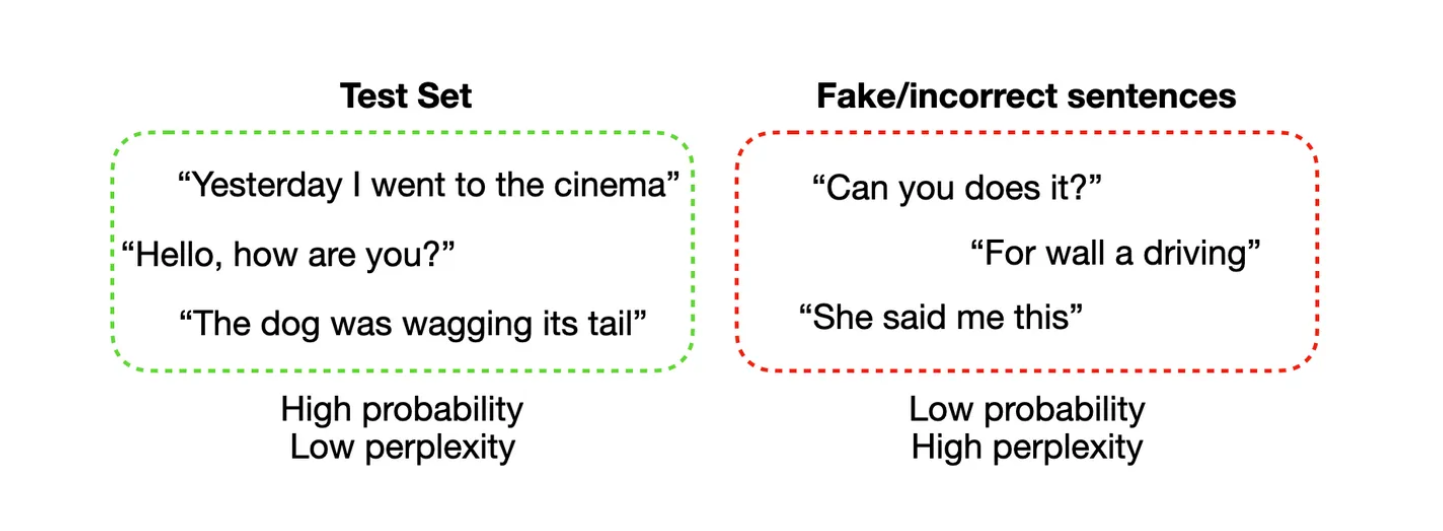
Perplexity is a commonly used measure to evaluate the performance of language models. It quantifies how well the model predicts a sample of text. Lower perplexity 2 values indicate better performance (Figure 2).
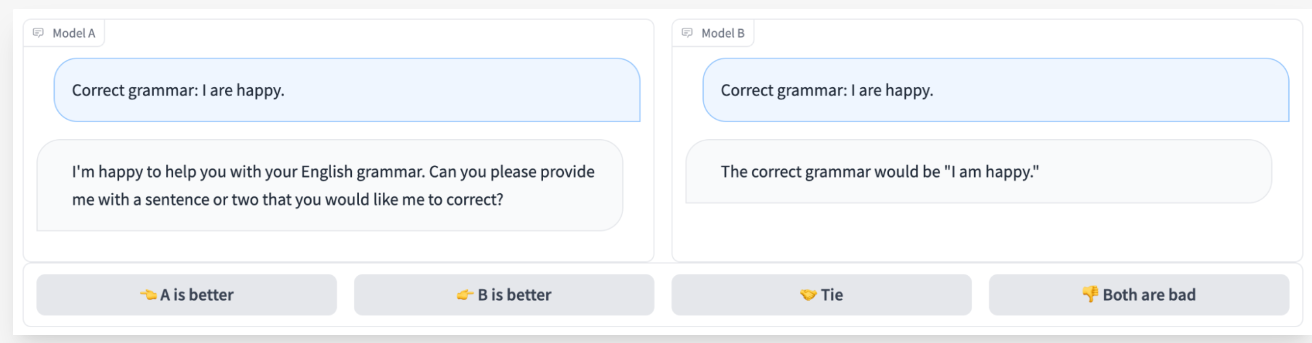
- Human evaluation:
The evaluation process includes enlisting human evaluators who assess the quality of the language model’s output. These evaluators rate 3 the generated responses based on different criteria, including:
- Relevance
- Fluency
- Coherence
- Overall quality.
This approach offers subjective feedback on the model’s performance (Figure 3).
- BLEU (Bilingual Evaluation Understudy)
BLEU is a metric commonly used in machine translation tasks. It compares the generated output with one or more reference translations and measures the similarity between them.
BLEU scores range from 0 to 1, with higher scores indicating better performance.
- ROUGE (Recall-Oriented Understudy for Gissing Evaluation)
ROUGE is a set of metrics used for evaluating the quality of summaries. It compares the generated summary with one or more reference summaries and calculates precision, recall, and F1-score (Figure 4). ROUGE scores provide insights into the summary generation capabilities of the language model.

- Diversity
Diversity measures assess the variety and uniqueness of the generated responses. It involves analyzing metrics such as n-gram diversity or measuring the semantic similarity between generated responses. Higher diversity scores indicate more diverse and unique outputs.
What are common challenges with existing LLM evaluation methods?
While existing evaluation methods for Large Language Models (LLMs) provide valuable insights, they are not perfect. The common issues associated with them are:
Data contamination
Foundation models are built using various data sources which may not be fully shared by the organization that built the LLM. Therefore, it is hard to be sure that the training data does not include instances of test data. Data contamination reduces the reliability of most LLM benchmarking exercises.
Over-reliance on perplexity
Perplexity measures how well a model predicts a given text but does not capture aspects such as coherence, relevance, or context understanding. Therefore, relying solely on perplexity may not provide a comprehensive assessment of an LLM’s quality.
Subjectivity & high cost of human evaluations
Human evaluation is a valuable method for assessing LLM outputs, but it can be subjective, prone to bias and significantly more expensive than automated evaluations. Different human evaluators may have varying opinions, and the evaluation criteria may lack consistency. Additionally, human evaluation can be time-consuming and expensive, especially for large-scale evaluations.
Biases in automated evaluations
Evaluations by LLMs suffer from predictable biases.5 We provided one example for each bias but the opposite cases are also possible (e.g. last items can be favored by some models).
- Order bias: First items favored.
- Compassion fade: Names are favored vs. anonymized code words
- Ego bias: Similar responses are favored
- Salience bias: Longer responses are preferred
- Bandwagon effect: Majority belief is preferred
- Attention bias: Sharing more irrelevant information is preferred
Limited reference data
Some evaluation methods, such as BLEU or ROUGE, require reference data for comparison.
However, obtaining high-quality reference data can be challenging, especially in scenarios where multiple acceptable responses exist or in open-ended tasks. Limited or biased reference data may not capture the full range of acceptable model outputs.
Lack of diversity metrics
Existing evaluation methods often don’t capture the diversity and creativity of LLM outputs. That is because metrics that only focus on accuracy and relevance overlook the importance of generating diverse and novel responses. Evaluating diversity in LLM outputs remains an ongoing research challenge.
Generalization to real-world scenarios
Evaluation methods typically focus on specific benchmark datasets or tasks, which don’t fully reflect the challenges of real-world applications. The evaluation on controlled datasets may not generalize well to diverse and dynamic contexts where LLMs are deployed.
Adversarial attacks
LLMs can be susceptible to adversarial attacks such as manipulation of model predictions and data poisoning, where carefully crafted input can mislead or deceive the model. Existing evaluation methods often do not account for such attacks, and robustness evaluation remains an active area of research.
In addition to these issues, enterprise generative AI models may struggle with legal and ethical issues, which may affect LLMs in your business.
Best practices to overcome problems of large language models evaluation methods
To address the existing problems of Large Language Models performance evaluation methods, researchers and practitioners are exploring various approaches and strategies. It may be prohibitively expensive to leverage all of these approaches in every project but awareness of these best practices can improve LLM project success.
Known training data
Leverage foundation models that share their training data to prevent contamination.
Multiple evaluation metrics:
Instead of relying solely on perplexity, incorporate multiple evaluation metrics for a more comprehensive assessment of LLM performance. Metrics like these can better capture the different aspects of model quality:
- Fluency
- Coherence
- Relevance
- Diversity
- Context understanding
Enhanced human evaluation
Improve the consistency and objectivity of human evaluation through clear guidelines and standardized criteria. Using multiple human judges and conducting inter-rater reliability checks can help reduce subjectivity. Additionally, crowd-sourcing evaluation can provide diverse perspectives and larger-scale assessments.
Diverse reference data
Create diverse and representative reference data to better evaluate LLM outputs. Curating datasets that cover a wide range of acceptable responses, encouraging contributions from diverse sources, and considering various contexts can enhance the quality and coverage of reference data.
Incorporating diversity metrics
Encourage the generation of diverse responses and evaluate the uniqueness of generated text through methods such as n-gram diversity or semantic similarity measurements.
Real-world evaluation
Augmenting evaluation methods with real-world scenarios and tasks can improve the generalization of LLM performance. Employing domain-specific or industry-specific evaluation datasets can provide a more realistic assessment of model capabilities.
Robustness evaluation
Evaluating LLMs for robustness against adversarial attacks is an ongoing research area. Developing evaluation methods that test the model’s resilience to various adversarial inputs and scenarios can enhance the security and reliability of LLMs.
Leverage LLMOps
LLMOps, a specialized branch of MLOps, is dedicated to the development and enhancement of LLMs. Employing LLMOps tools for testing and customizing LLMs in your business not only saves time but also minimizes errors.
Further reading
Learn more on ChatGPT to understand LLMs better by reading:
- ChatGPT Education Use Cases, Benefits & Challenges
- How to Use ChatGPT for Business: Top 40 Applications
- GPT-4: In-depth Guide
If you have further questions regarding the topic, reach out to us:
External links:
- 1. “Open LLM Leaderboard” Hugging Face. May 30, 2023.
- 2. “Perplexity in Language Models” Towards Data Science. Retrieved on May 30, 2023.
- 3. “Chatbot Arena: Benchmarking LLMs in the Wild with Elo Ratings” May 30, 2023.
- 4. “Introduction to Text Summarization with ROUGE Scores ” Towards Data Science May 30, 2023.
- 5. Koo R.; et al. (2023). Benchmarking Cognitive Biases in Large Language Models as Evaluators. Retrieved January 1, 2024

Next to Read
In-Depth Guide to Cloud Large Language Models (LLMs) in 2024
What is LLMOps, Why It Matters & 7 Best Practices in 2024
Large Language Model Training in 2024
Related research
Guide to RLHF LLMs in 2024: Benefits & Top Vendors

Comments
Your email address will not be published. All fields are required.