Craigslist is one of the popular global advertising platforms, functioning in more than 70 countries and receiving over 50 billion monthly page views.1 Businesses scrape Craigslist for a variety of reasons, including market research, job recruitment, real estate analysis, and generating leads.
This article explains how to extract data from Craigslist, as well as the top scrapers for Craigslist scraping and their pricing structures.
However, it is crucial to note that the scraped data from Craigslist may violate their Terms of Service (ToS). For your scraping projects, you are advised to get legal advice to ensure compliance with all relevant regulations.
Quick summary of the best Craigslist scrapers
| Vendors | Pricing/mo | Free trial | Pay-as-you-go |
|---|---|---|---|
| Bright Data | $500 | 7-day | ✅ |
| Smartproxy | $29 | 3K free requests | ❌ |
| Oxylabs | $49 | 7-day | ❌ |
| Nimble | $150 | 7-day | ❌ |
| Octoparse | $89 | 14-day | ❌ |
| Zyte | $100 | $5 free for a month | ❌ |
How to scrape data from Craigslist
You can extract data from Craigslist using a Python web scraping library or a no-code scraper that requires no programming. For example, Beautiful Soup is a popular Python module for web scraping.
- Identify the specific Craigslist page and open developer tools to inspect the element. Right-click on the specific element you intend to inspect. The specific element associated with the selection will be highlighted in the source code.
- Identify unique identifiers such as “id” or “class” that distinguish the element you want to scrape.
- Install necessary library -> pip install requests beautifulsoup4
- Build the scraper
- Craigslist displays listings across multiple pages. To scrape data from multiple pages, you need to loop through several pages to scrape data. Most no-code scraping tools automatically handle pagination to simplify the data scraping process.
- Once you have scraped all the needed data, you will need to store the scraped data in a CSV or other preferred format.
Best practices for Craigslist web scraping
Scraping Craigslist poses several challenges, such as legal issues, technical scraping challenges, and maintenance challenges.
- Always check robots.txt: Check the target website’s robots.txt file before conducting any scraping activities. The robots.txt file is a standard used by websites to inform web crawlers which parts of the site can be accessed.
- Review Craigslist terms of use: Many websites outline their data collection policy in their Terms of Service. Websites can also specify other conditions in their Terms of Service (ToS), such as anti-bot measures, including IP bans, rate limits, or CAPTCHAs.
- Rotate user-agents and IPs: Using the same IP address can heighten the chances of being identified and blocked by the target website. Rotating IP addresses and user-agents is a technique used in data scraping to bypass rate limits and prevent IP bans. For instance, Scrapy has built-in capabilities for user-agent rotation. There are many proxy service providers that offer proxies with automated IP rotation. You can rotate your IP addresses after each connection request or after a set period.
- Avoid overwhelming servers: Sending too many requests in a short period of time can overload the server and result in IP bans. It is important to implement rate limiting and randomize the time between your requests to mimic human-like behavior.
Is scraping Craigslist legal?
Scraping Craigslist can raise legal and ethical issues. There are several considerations regarding the legality of Craigslist scraping, including copyright laws, privacy concerns, or commercial users. The legality of scraping data can vary from one jurisdiction to another. It is important to consult with legal counsel before conducting any scraping activity.
Top 5 Craigslist scrapers
Craigslist scraper (also known as Craigslist data extractor) enables individuals and organizations to access Craigslist and scrape public data from Craigslist without the need for coding.
1. Bright Data
Bright Data Craigslist scraper allows you to scrape Craigslist data from listing pages, including community, services, for sale, and real estate data.
Features:
- Offers unblocking and proxy infrastructure to extract data from the Craigslist website while avoiding CAPTCHAs and IP blocks.
- Allows users to identify issues in a past crawl and monitor the scraping process through built-in debug tools.
- Offers auto-scaling infrastructure capability to ensure the web scraper can handle varying loads without intervention.
- Auto-retry mechanism enables users to automatically retry the request after a suitable interval.
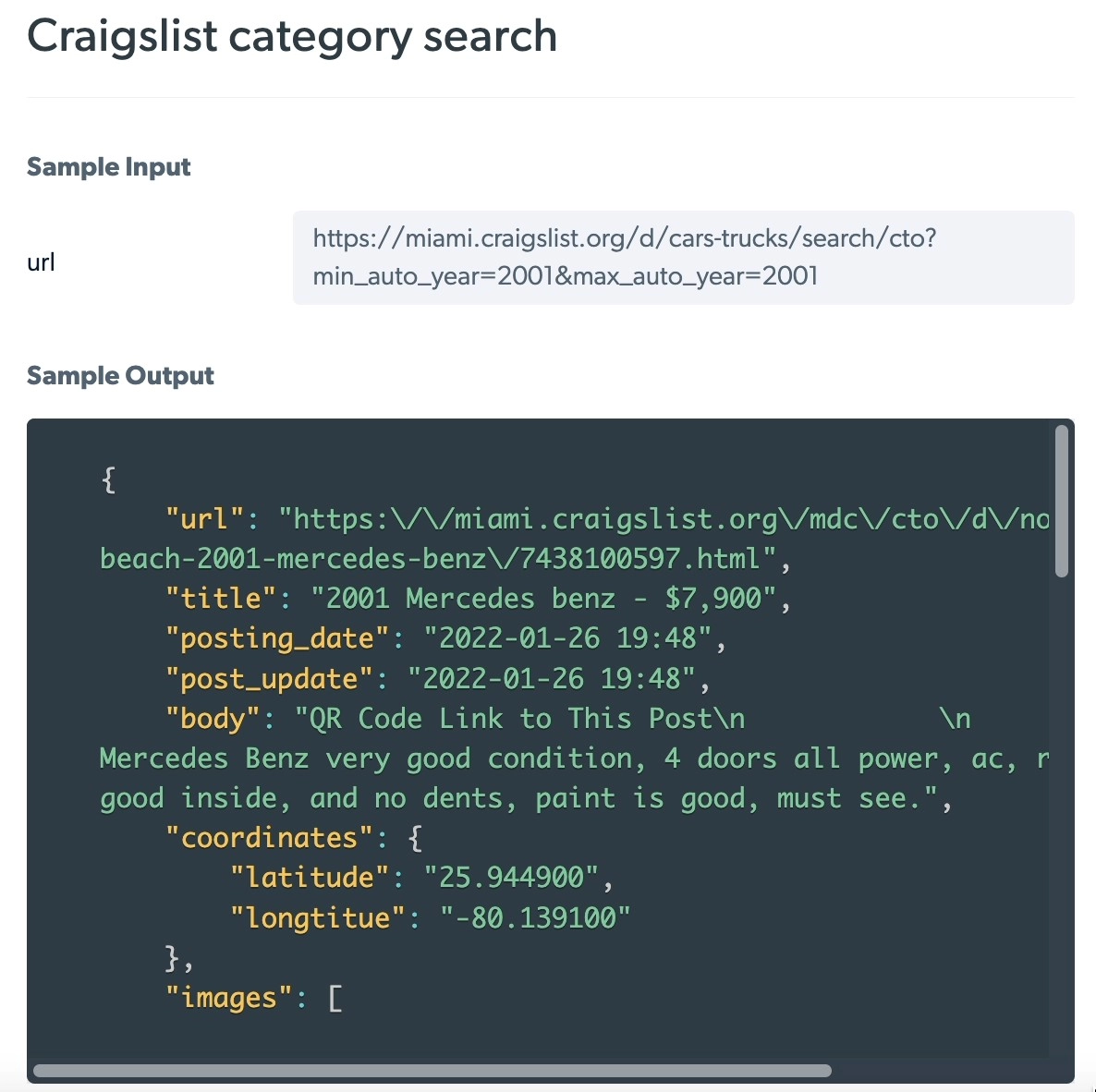
Figure 1: Output example of scraped data from Craigslist using Bright Data’s Web Scraper IDE
Pricing:
- $500/monthly
- 7-day free trial
- Pay as you go option is available
2. Smartproxy
Smartproxy web scraper API collects data from any website, including JavaScript, AJAX, or other dynamic websites. They provide a free Chrome extension suitable for the basic, manual scraping projects.

Features:
- You can preview data during the data extraction process.
- Allows you to rename column names in your scraped dataset during data collection setup.
- Delivers the extracted data in JSON or CSV file.
Pricing:
- $50/month
- Free trial with 3k requests
3. Oxylabs
Oxylabs Web Scraper API helps users collect data from static and dynamic web pages, meaning it can handle JavaScript-heavy websites.

Features:
- Offers Oxycopilot, a custom parser builder, enables you to extract only the data relevant to you (e.g., product name, price, etc.) by guiding the API with a prompt. Below is an example where we selected only four fields from a specific URL.
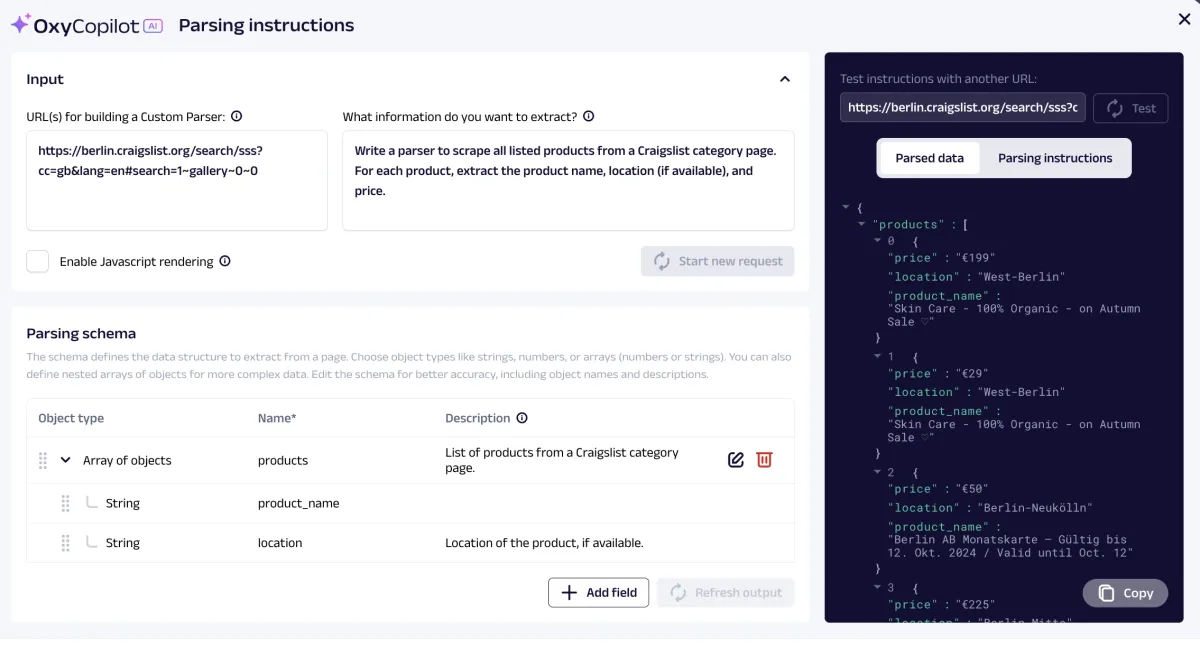
- Handles failed scraping requests with auto-retry mechanism. It enables the scraper to continue the scraping process without manual intervention.
- Provides built-in proxies that users can leverage during the data collection process.
Pricing:
- $49/monthly
- 7-day free trial
4. Nimble
Nimble provides an eCommerce scraping API equipped with integrated residential proxies and an Unblocker Proxy solution. With built-in residential proxies, users can target on specific states, cities, and individual stores using zip code localization. The scraped data is then directly delivered to your S3/GCS buckets.

Features:
- Allows users to handle a significant number of URLs in a single request
- All requests made through Nimble’s eCommerce API are directed through proxy network.
- Executes various actions on a webpage during data collection process, such as clicking, typing, and scrolling.
Pricing:
- $150/mo
- 7-day free trial
5. Octoparse
Octoparse offers UI-based data harvesting solutions for data collection projects, including Craigslist scraping. It allows users to collect data from any dynamic websites including AJAX, and JAVA.
Features:
- Automatically handle anti-bot measures like CAPTCHAs.
- Offers auto-detect capability to handle pagination.
- Allows users to create their own web scrapers without the need for coding.
Pricing:
- $89/monthly
- Offers free plan with limited features
- 14-day free trial
6. Zyte
Zyte API is a web scraping tool that enables browser automation and large-scale data retrieval from websites. You’re only billed for successful responses from the Zyte API.

Features:
- Overcomes web scraping challenges such as IP bans and rate limits with automatic proxy rotation and retries capabilities. Automatically detects when an IP address is blocked and rotates the IP, and tries once more.
- Captures screenshots of the web page.
- Offers a built-in scriptable browser, allowing users to control browser sessions to interact with and scrape data from web pages.
Pricing:
- $100/monthly
- $5 free for a month
Further reading
- How to Scrape Amazon Product Data & Reviews
- Web Scraping Tools: Data-driven Benchmarking
- Top 7 Amazon Scrapers to Gather Data From Amazon
Check out our data-driven list of e-commerce scrapers for help choosing the right tool, and get in touch with us:
External sources
External Links
- 1. Top Craigslist Statistics for 2023 That You Should Check Out. FirstSiteGuide


Comments
Your email address will not be published. All fields are required.