Web scraping is not the only way to collect data from websites. Various other methods (e.g. LLMs) are available and each technique has trade-offs.
See the best web scraping techniques, the benefits and limitations of each method and practical tips on choosing the right approach for your data collection project:
Generative AI and Large Language Models (LLMs)
Here’s how generative AI models work alongside traditional data scraping techniques:
1. LLMs to code scrapers
In 2024, the adoption of Generative AI and Large Language Models (LLMs), like GPT-4, grew substantially, marking a new era in data scraping. Tools like ChatGPT can now guide users in writing code to extract data from target websites in any programming language. They can generate web scraping code snippets tailored to the user’s preferred language and library. For example, you can use prompts to retrieve product description data from a specific Amazon product page.

2. LLMs for parsing web data
- Sample HTML code can input to LLMs. Then, LLMs can identify specific sections (e.g. prices, product descriptions) from that data.
3. Web scraper agents
The scraping operation doesn’t need to be a single-step solution. AI agents can run multi-step processes and make decisions. For example, tools like LangChain combine web scraping with LLMs, enabling users to ask for extraction of specific information, like all product reviews mentioning “durability” on an e-commerce page.
Sponsored
Oxylabs provides OxyCopilot, an AI-powered custom parser builder that lets users extract specific, relevant data (such as product name, price, etc.) by directing the API through prompts. For instance, we used it to retrieve only four specific fields from a given URL.
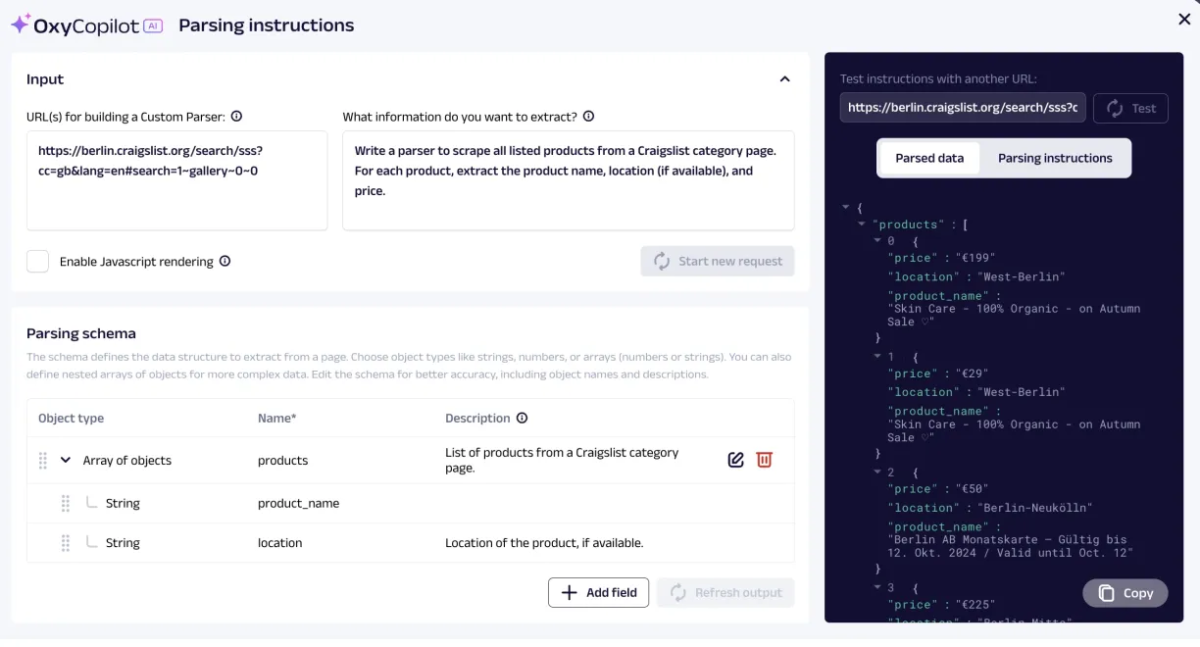
Automated web scraping techniques
Automated web scraping techniques involve utilizing a web scraping software to collect web data from online sources automatically. They are more efficient and scalable for large-scale web scraping tasks.
4. Web Scraping APIs
Web scraper APIs collect data automatically from online sources. Creating custom, in-house web scrapers allows users to tailor the crawler to their unique data collection requirements. However, developing an in-house web scraping tool demands technical skills and resources, as well as time and ongoing maintenance.
The table below presents the top web scraping service providers. For an in-depth comparison, read our research on this subject.
| Vendors | Pricing/mo | Trial | PAYG | Solution Type |
|---|---|---|---|---|
| Bright Data | $500 | 7 days | ✅ | API |
| Smartproxy | $29 | 3K free requests | ❌ | API |
| Oxylabs | $49 | 7 days | ❌ | API |
| Nimble | $150 | 7 days | ❌ | API |
| NetNut | Custom offer | 7 days | ❌ | API |
| Apify | $49 | $5 free credit | ✅ | No-code & API |
| SOAX | $59 | 7 days | ❌ | API |
| Zyte | $100 | $5 free for a month | ❌ | API |
| Diffbot | $299 | 14 days | ❌ | API |
| Octoparse | $89 | 14 days | ❌ | No-code |
| Nanonets | $499 | N/A | ✅ | OCR API |
In-house web scraper:
Pros:
- Customization: Can be customized to meet specific scraping needs and business requirements.
- Control: Provides full control over the data pipeline process.
- Cost-saving: can be more cost-effective in the long run than using a pre-built scraping bot.
Cons:
- Technical expertise: Familiarity with web scraping libraries such as Beautiful Soup, Scrapy, or Selenium.
- Maintenance: Require development and maintenance effort.
Outsourced web scraper:
Pros:
- Technical expertise: Do not require technical knowledge.
- Time savings: These tools are maintained by a third-party provider.
- Reduced risk: Some web scrapers offer unblocking technologies to bypass anti-scraping techniques such as CAPTCHAs.
Cons:
- Cost: It may be more expensive to outsource the development of web scraping infrastructure.
Building custom web scrapers
5.Web Scraping Libraries
Web scraping libraries are software packages that provide pre-built functions and tools for web scraping tasks. These libraries simplify the process of navigating web pages, parsing HTML data, and locating elements to extract. Here are some examples of popular web scraping libraries:
- Beautiful Soup: Specifically designed for parsing and extracting web data from HTML and XML sites. You can use Beautiful Soup to collect data from static websites that do not require JavaScript to load.
- Scrapy: Provides a framework for building web scrapers and crawlers. It is a good choice for complex web scraping tasks that require logging in or dealing with cookies.
- Puppeteer: It is a JavaScript Web Scraping Libraries. You can use Puppeteer to scrape dynamic web pages.
- Cheerio: Cheerio is well-suited for scraping static web pages due to its inability to execute JavaScript.
- Selenium: It automates web interactions and collects data from dynamic sites. Selenium is a good choice for scraping websites that require user interaction, such as clicking buttons, filling out forms, and scrolling the page.
6. Headless Browsers
Headless browsers such as PhantomJS, Puppeteer, or Selenium enable users to collect web data in a headless mode, meaning that it runs without a graphical user interface.
Headless browsers can be a powerful tool for scraping dynamic and interactive websites that employ client-side or server-side scripting. Web crawlers can access and extract data that may not be visible in the HTML code using headless browsers.
It interacts with dynamic page elements like buttons and drop-down menus. The following are the general steps for collecting data with a headless browser:
- Set up a headless browser: Choose the appropriate headless browser for your web scraping project and set it up on your server. Each headless browser requires different setup steps, depending on the website being scraped or the programming language being used.Note that you must choose a headless browser that supports JavaScript and other client-side scripting languages to scrape a dynamic web page.
- Install the necessary libraries: Install a programming language like Python or JavaScript to parse and extract the desired data.
- Maintain web scraping tools: Dynamic websites can change frequently. Changes to the HTML code or JavaScript can break a web scraping script. Therefore, you must regularly monitor the performance of the web scraping process to keep up with changes to the website’s structure.
Techniques for parsing web pages
7. Optical Character Recognition (OCR)
Optical Character Recognition (OCR) is a technology that allows users to extract text data from images (screen scraping) or scanned documents on web pages.
OCR software reads text elements in non-text formats, such as PDFs or images. It captures web data elements from sites using a screenshot or another method to extract the desired data from the recognized text. However, there are some limitations you must be aware of when extracting data using OCR.
- It may have difficulty recognizing small or unusual fonts.
- The accuracy of OCR relies on the input image quality. For instance, poor image quality, such as blur, can make it challenging or impossible for OCR software to recognize text accurately.
- It may struggle to recognize text data in columns, tables, or other complex layouts.
8. HTML Parsing
HTML parsing is another technique used to extract data from HTML code automatically. Here are some steps to collect web data through HTML parsing:
- Inspecting the HTML code of the target page: Involves using a browser’s developer tools to view the HTML code of the web page you intend to scrape. This enables users to understand the structure of the HTML code and locate the specific elements they want to extract, such as text, images, or links.
- Choosing a parser: There are several factors to consider when selecting a parser, such as the programming language being used and the complexity of the website’s HTML structure. The parser you choose must be compatible with the programming language you use for web scraping. Here is a list of some popular parsers for different programming languages:
- Beautiful Soup and lxml for Python
- Jsoup for Java
- HtmlAgilityPack for C#
- Parsing HTML: Process of reading and interpreting the HTML code of the target web page to extract specific data elements.
- Extracting data: Collect the specific data elements using the parser.
9. DOM Parsing
DOM parsing allows you to parse HTML or XML documents into their corresponding Document Object Model (DOM) representation. DOM Parser is part of the W3C standard that provides methods to navigate the DOM tree and extract desired information from it, such as text or attributes.
Manual web scraping techniques
Manual web scraping may be justifiable for small-scale or one-time web scraping projects where automated scraping techniques are not practical. However, manual scraping techniques are time-consuming and error-prone, so it is important to use them only when it is necessary for data collection projects.
10. Manual Navigation
It is the process of manually navigating through a website and collecting web data along the way. If the desired data is dispersed across multiple pages or is not easily accessible through automated scraping techniques, manual navigation may be preferable.
- Screen Capturing: It is the process of taking screenshots of data on the target website and manually entering the captured data into a document such as a spreadsheet.
- Data Entry: This involves manually entering data from the target website into a file
Hybrid web scraping techniques
Hybrid web scraping combines automated and manual web scraping techniques to collect data from web sources. This approach is practical when automated web scraping techniques cannot extract the required data completely.
Assume you extracted data using an automated web scraping technique like an API call. When reviewing your scraped data, you discovered missing or incorrect information. In this case, you can use manual web scraping to fill in the missing or inaccurate data elements. Using hybrid web scraping techniques can help verify the accuracy and completeness of the scraped data.


Comments
Your email address will not be published. All fields are required.