Inspired by DevOps practices, MLOps and DataOps have emerged as critical methodologies for ensuring seamless machine learning and database operations. While both share roots in automation and operational efficiency, the debate around MLOps vs DataOps highlights their distinct roles in IT workflows. Latest IT automation trends show that companies adopting:
- DataOps can boost feature volume by 50%, reduce time to market by 30%, enhance productivity by 10%, and cut IT costs by 10%
- MLOps can reduce downtime by 20%, leading to the expectation that 40% of IT teams will adopt MLOps and AIOps in their ML pipelines.
Explore MLOps vs DataOps in terms of their methods, similarities and differences to understand better:
| Aspect | MLOps | DataOps | Similarities |
|---|---|---|---|
| Objectives, expertise & tools | Focuses on ML model lifecycle management for better management and deployment, requiring ML expertise and MLOps tools | Focuses on data management cycles and data quality, requiring data management and orchestration tools | ❌ |
| Goal | Aims to deliver high quality ML models, ensuring reproducibility, scalability, and reliability in production | Aims to deliver high-quality data outputs and reduce time to market | ❌ |
| Scope | Applies to the machine learning lifecycle to manage and deploy ML models in production environments | Applies across the entire data management lifecycle from data preparation to reporting. | ❌ |
| Collaboration | Encourages collaboration across departments | Encourages collaboration across departments | ✅ |
| Automation | Automates processes from model creation to deployment and monitoring | Automates processes from data preparation to reporting | ✅ |
| Standardization | Standardizes ML workflows and creates a common language for stakeholders | Standardizes data pipelines for all stakeholders | ✅ |
| AI governance & compliance | Ensures model quality, privacy, and compliance with regulations | Ensures data quality, privacy, and compliance with regulations | ✅ |
| Key practices | Includes continuous integration and deployment (CI/CD) pipelines for models, model performance monitoring, model explainability and interpretability techniques. | Includes data profiling, cataloging, version control, and data governance practices. | ❌ |
| Dependency | MLOps often depends on DataOps for data extraction and transformation | DataOps can operate independently without MLOps | ❌ |
What is MLOps?
MLOps combines operations with machine learning. It automates and streamlines the entire ML lifecycle, from production to development, deployment to retraining, encompassing DevOps practices such as Continuous Integration (CI) and Continuous Deployment (CD) for efficient model management.
In addition to CI/CD, it adds the continuous training (CT) principle to enable systematic model monitoring and model retraining in cases of model drift.
What is DataOps?
DataOps, data operations, is a process-oriented methodology used by data teams to improve the quality of data, increase the efficiency of analytics, and reduce the time cycle of data analytics. DataOps takes DevOps practices and integrates them into the data management workflows.
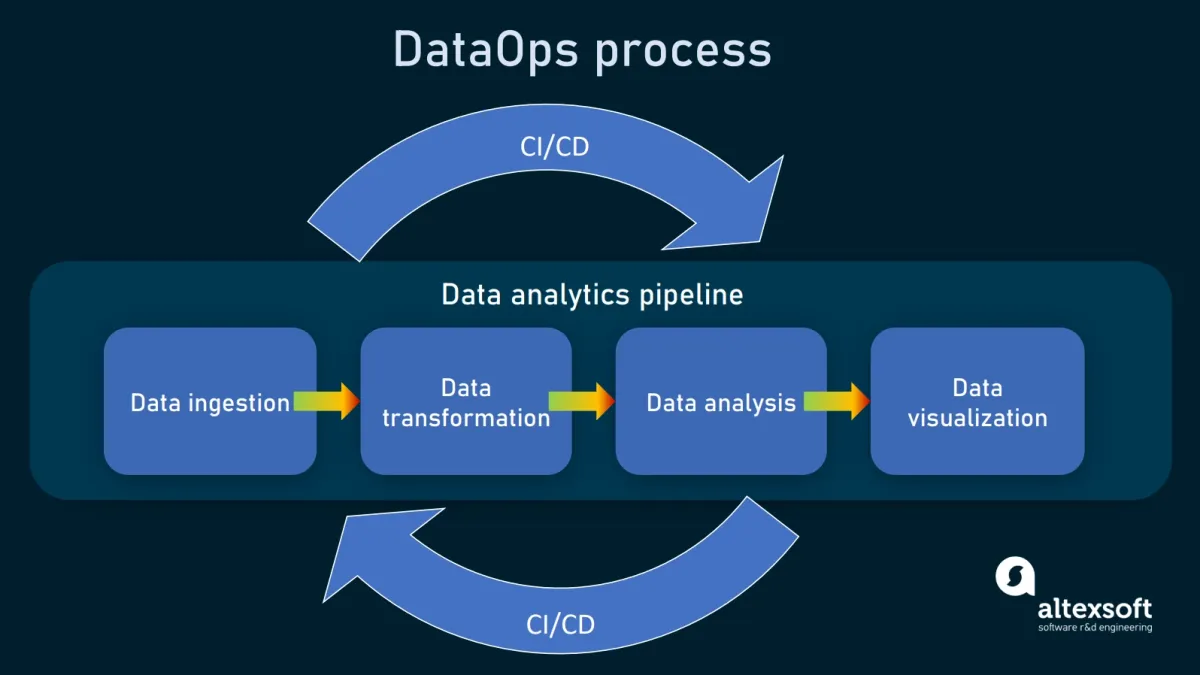
DataOps automates processes such as visualization and reporting by creating pipelines with data security, ensuring data quality, and data engineering stages. Thus, DataOps improves the availability, accessibility, and integration of data.
Who uses DataOps?
This methodology can empower processing data, helping help companies extract value from their data. DataOps is used by data architects, data engineers, data analysts, and data scientists for model training and software development efforts.
Figure 1: DataOps process
DataOps benefits for businesses
In short, DataOps helps businesses to:
- Create automated data pipelines
- Centralize data and break down data silos
- Democratize data by making it available to all stakeholders
Similarities: MLOps and DataOps
Figure 2: Relationship between DataOps, MLOps, and AIOps

Both MLOps and DataOps involve:
- Collaboration for workflow: The operating philosophy of DataOps and MLOps is to achieve harmony and speed by encouraging different departments to work together.
- Automation: Both of them work towards automating all processes in their pipelines. DataOps automates the entire process from data preparation to reporting, and MLOps automates the entire process from model creation to model deployment and monitoring.
- Standardization: While DataOps standardize the data pipelines for all stakeholders, MLOps standardize the ML workflows and create a common language for all stakeholders.
- AI governance and compliance: Both tools ensure data and model quality, privacy and regulatory compliance with existing rules and policies.
- Explore more on AI compliance solutions, AI governance tools and responsible AI tools practices.
Differences: MLOps vs. DataOps
The main differences between MLOps and DataOps are:
- Objectives, expertise & tools: They deal with a different set of questions and objectives in the machine learning lifecycle and require different types of expertise and tools.
- Dependency: You can have DataOps without MLOps because you can have data extraction and transformation without machine learning. The contrary is barely true.
- Scope: DataOps is applicable across the complete lifecycle of data applications. MLOps is primarily for simplification of management and deployment of machine learning models.
- Goal: The goal of DataOps is to streamline the data management cycles, achieve a faster time to market, and produce high-quality outputs. The aim of MLOps is to facilitate the deployment of ML models in production environments.
- Key practices: DataOps focuses on data profiling, cataloging, version control, and governance, while MLOps emphasizes CI/CD for models, model monitoring, and explainability.
DataOps vs. MLOps: Which One is Right for Your Project?
Deciding between MLOps and DataOps depends on what your project aims to achieve:
Choose MLOps if:
- Your main goal is to develop, deploy, and manage machine learning (ML) models. If you need to oversee the end-to-end lifecycle of ML models, including version control, continuous delivery, and model governance, MLOps is your best bet.
- You want to streamline the ML lifecycle by automating experiments, ensuring reproducibility, and efficiently scaling operations.
- You need to manage complex ML projects. As projects grow, they involve more data processes, models, and require advanced automation and monitoring. MLOps helps maintain scalability, reproducibility, and robustness for large-scale ML applications.
Choose DataOps if:
- Your focus is on managing data and delivering data within your organization. If you aim to ensure data quality, streamline processes, and optimise data delivery for tasks like business intelligence and analytics, DataOps is the way to go.
- You want to automate data pipelines and ensure consistent, high-quality data for downstream tasks.
- You are dealing with large volumes of data or scaling up your data processing. DataOps practices are designed to efficiently handle data ingestion, data transformation, and quality assurance, ensuring that your data processesremain reliable and scalable.
If you want to get started with MLOps in your business, you can check our data-driven list of MLOps platforms. If you have other questions, we can help:


Comments
Your email address will not be published. All fields are required.