Have you ever wondered how search engines such as Google and Bing collect all the data they present in their search results? It is because search engines index all the pages in their archives so that they can return the most relevant results based on queries. Web crawlers enable search engines to handle this process.
This article highlights important aspects of what a web crawler is, why web crawling is important, how it works, applications & examples.
The best web crawlers of 2025
| Vendors | Pricing/mo | Free trial | PAYG plan | Type |
|---|---|---|---|---|
| Bright Data | $500 | 7-day | ✅ | No-code |
| Oxylabs | $49 | 7-day | ❌ | API |
| Smartproxy | $29 | 3K free requests | ❌ | No-code |
| Nimble | $150 | 7-day | ❌ | API |
| Apify | $49 | $5 free usage | ✅ | API |
| SOAX | $59 | 7-day | ❌ | API |
| Zyte | $100 | $5 free | ❌ | API |
| Diffbot | $299 | 14-day | ❌ | API |
| Octoparse | $89 | 14-day | ❌ | No-code |
| Scraper API | $149 | 7-day | ❌ | API |
What is a web crawler?
A web crawler, also known as a web spider, robot, crawling agent or web scraper, is a program that can serve two functions:
- Systematically browsing the web to index content for search engines. Web crawlers copy pages for processing by a search engine, which indexes the downloaded pages for easier retrieval so that users can get search results faster. This was the original meaning of web crawler.
- Automatically retrieving content from any web page. This is more commonly called web scraping. This meaning of web crawler came about as companies other than search engines started using web scrapers to retrieve web information. For example, e-commerce companies rely on their competitors’ prices for dynamic pricing.
What is web crawling?
Web crawling is the process of indexing data on web pages by using a program or automated script. These automated scripts or programs are known by multiple names, including web crawler, spider, spider bot, and often shortened to crawler.
How does a web crawler work?
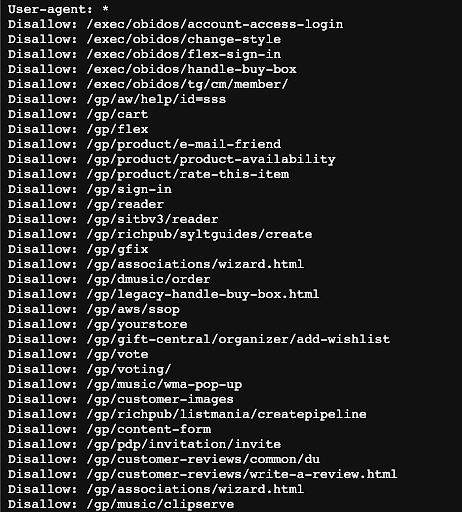
- Web crawlers start their crawling process by downloading the website’s robot.txt file (see Figure 2). The file includes sitemaps that list the URLs that the search engine can crawl.
- Once web crawlers start crawling a page, they discover new pages via hyperlinks.
- Crawlers add newly discovered URLs to the crawl queue so that they can be crawled later if they are interesting to be crawled for the crawler’s developer.
Thanks to this flow, web crawlers can index every single page that is connected to others.
Figure 2: An example of a robot.txt file
How often should you crawl web pages?
Since web pages change regularly, it is also important to identify how frequently scrapers should crawl web pages.
There is no rule regarding the frequency of website crawling. It depends on the frequency with which a website updates its content and its links. If you utilize a pay-as-you-go bot service, revisiting and crawling web pages daily may be costly and consume your crawl budget quickly.
For example, search engine crawlers use several algorithms to decide factors such as how often an existing page should be re-crawled and how many pages on a site should be indexed.
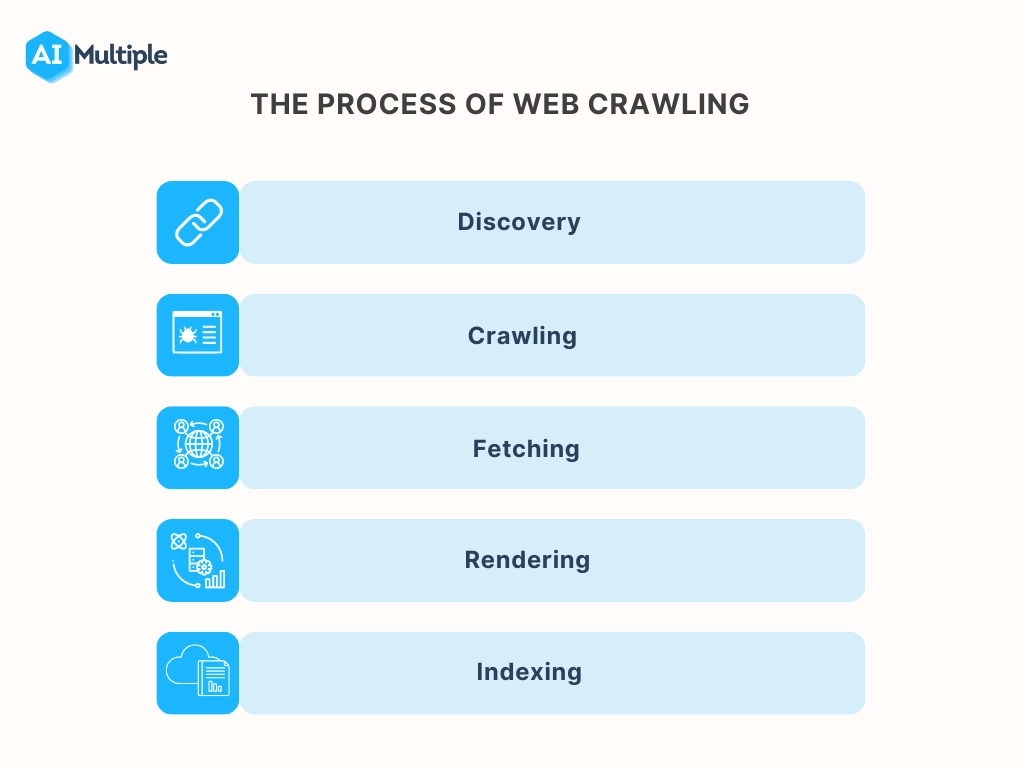
Figure 3: The image shows a basic steps involved in the web crawling process.
What are web crawling applications?
Web crawling is commonly used to index pages for search engines. This enables search engines to provide relevant results for queries. Web crawling is also used to describe web scraping, pulling structured data from web pages, and web scraping has numerous applications. It also impacts a website’s SEO (search engine optimization) by providing input to search engines like Google whether your content has relevant information to the query or if it is a direct copy of another content online.
Sponsored
Bright Data’s Data Collector enables companies to set up and scale web crawling operations rapidly with a SaaS model.

Building a web crawler or using web crawling tools: which one to choose?
In-House web crawlers
To build your in-house web crawlers, you can use programming languages such as javascript, python, etc. For example, Googlebot is one of the most well-known examples of an in-house web crawler written in C++ and Python.
Depending on your web crawling requirements, you may also utilize open source web crawlers. Open source web crawlers enable users to customize the source code based on their specific purposes.
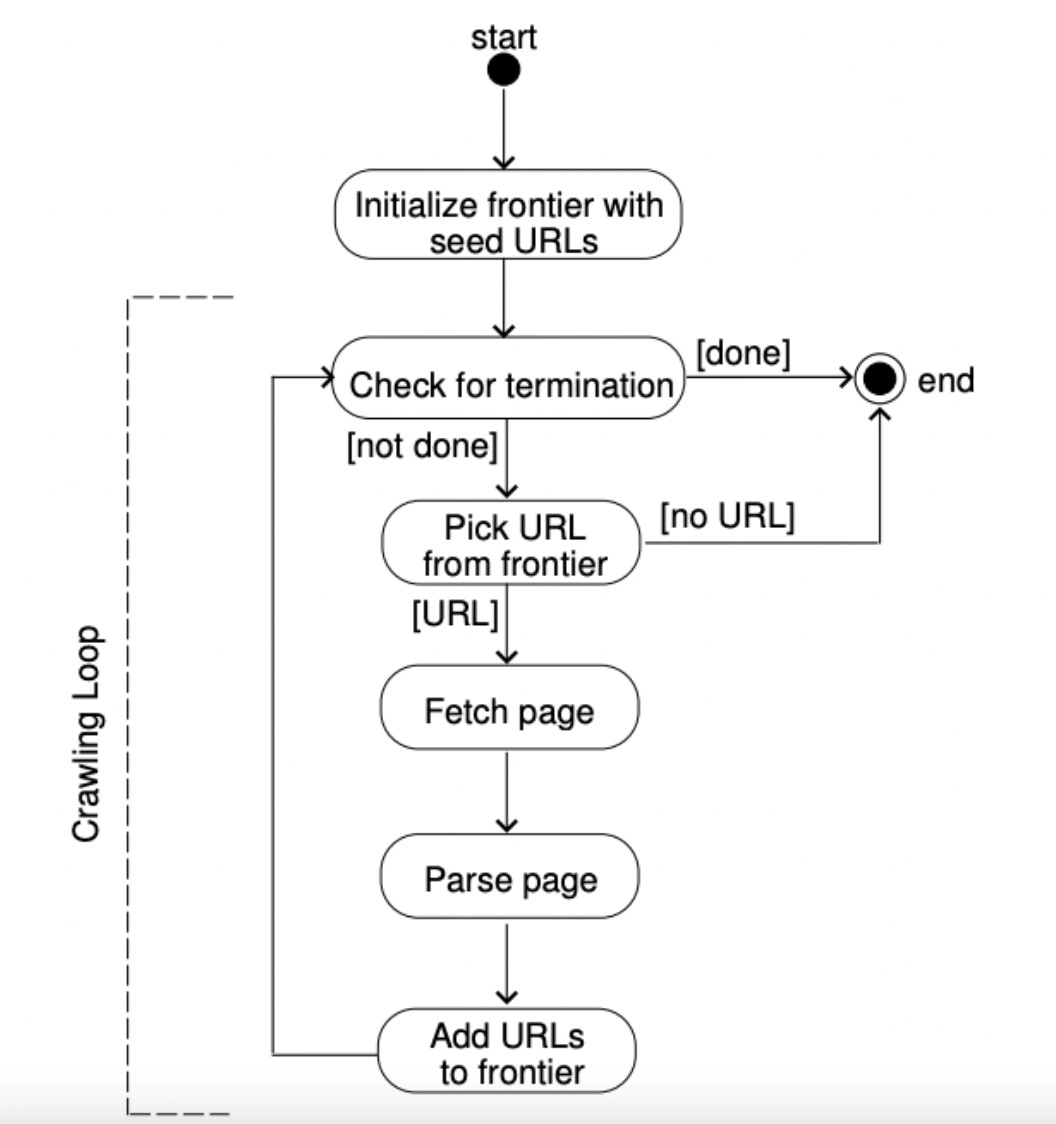
The architecture of a self-built crawler system comprises the following steps:
- Seed URL: The seed URL, also known as the initiator URL, is the input web crawlers use to initiate indexing and crawling processes.
- URL frontier: The crawl frontier consists of the policies and rules a web crawler must follow when visiting websites. The web crawler decides which pages to visit based on the frontier’s policies (see Figure 5). Crawl frontier assigns different priorities to each URL (e.g. high-priority and low-priority URLs) in order to inform the crawler about which pages to visit next and how frequently the page should be visited.
- Fetching & rendering URL(s): URL frontier informs the fetcher about which URL it should make a request to retrieve the required information from its source. The web crawler then renders the fetched URLs in order to display the web content on the client’s screen.
- Content processing: Once the content on the crawled web page is rendered, it is downloaded and saved in storage for further use. The downloaded content could contain duplicate pages, malware, etc.
- URL filtering: URL filtering is the process of removing or blocking certain URLs from loading on a user’s device for certain reasons. Once the URL filter checks all the URLs in the storage, it passes the allowed URLs to the URL downloader.
- URL loader: URL downloader determines whether a web crawler has crawled a URL. If the URL downloader encounters URLs that have not yet been crawled, it forwards them to the URL frontier to be crawled.
Advantage:
- You can customize self-built web crawlers based on your particular crawling needs.
Disadvantage:
- Self-built web crawlers require development and maintenance effort.
Figure 5: An explanation of how a URL frontier works.
Outsourced web crawlers
If you do not have the technical knowledge or a technical team to develop your in-house web crawler, you can use no-code web crawlers.
Advantage
- Pre-built web crawlers do not require technical knowledge.
Disadvantage
- Pre-built crawlers are less flexible than code-based crawlers.
Sponsored
Oxylabs Web Crawler API allows users to gather publicly available data from websites by handling complex scraping scenarios, including CAPTCHAs and navigating through AJAX-loaded content.

Why is web crawling important?
Thanks to the digital revolution, the total amount of data on the web has increased. Global data generation is anticipated to increase to more than 180 zettabytes over the following two years, up until 2025. According to IDC, 80% of worldwide data will be unstructured by 2025.
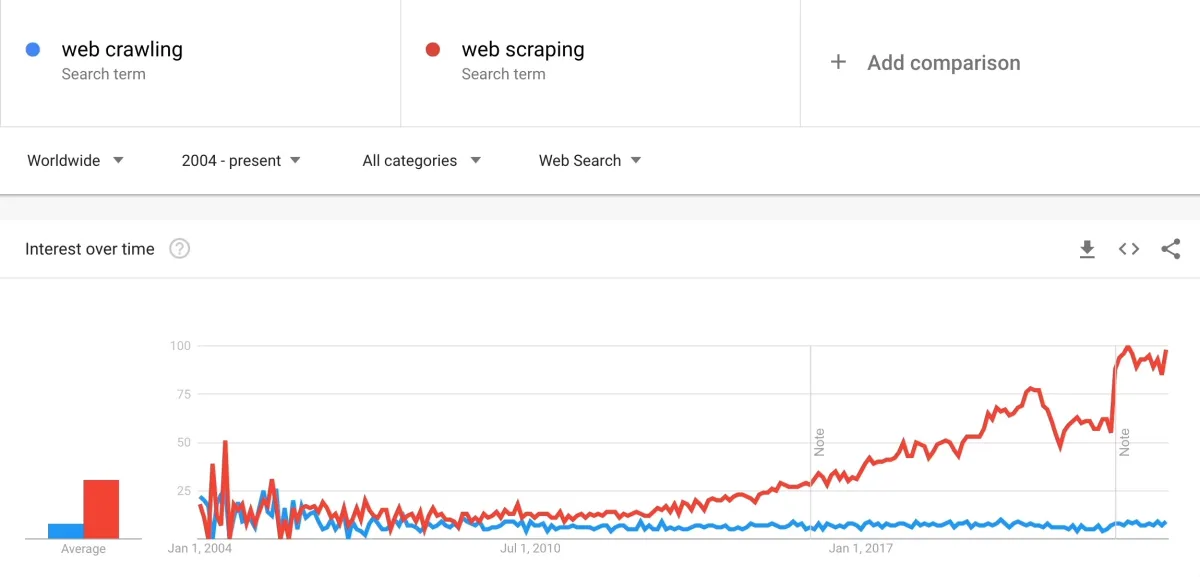
the same time period, interest in web scraping has outpaced the interest in web crawling. Possible reasons are:
- Increasing interest in analytics and data-driven decision making are the main drivers for companies to invest in scraping.
- Crawling done by search engines is no longer a topic of increasing interest since it is a mature topic where companies have been investing in since the late 1990s.
- Search engine industry is a mature industry dominated by a few players like Google, Baidu, Bing and Yandex so few companies need to build crawlers.
What is the difference between web crawling and web scraping?
Web scraping is using web crawlers to scan and store all the content from a targeted webpage. In other words, web scraping is a specific use case of web crawling to create a targeted dataset, such as pulling all the finance news for investment analysis and searching for specific company names.
Traditionally, once a web crawler has crawled and indexed all of the elements of the web page, a web scraper extracted data from the indexed web page. However, these days scraping and crawling terms are used interchangeably with the difference that crawler tends to refer more to search engine crawlers. As companies other than search engines started using web data, the term web scraper started taking over the term web crawler.
Check out our guide web crawling vs. web scraping to learn more about the differences between them.
What are the different types of web crawlers?
Web crawlers are classified into four categories based on how they operate.
- Focused web crawler: A focused crawler is a web crawler that searches, indexes and downloads only web content that is relevant to a specific topic to provide more localized web content. A standard web crawler follows each hyperlinks on a web page. Unlike standard web crawlers, focused web crawlers seek out and index the most relevant links while ignoring irrelevant ones (see Figure 4).
Figure 4: Illustration of the difference between a standard and focused web crawler
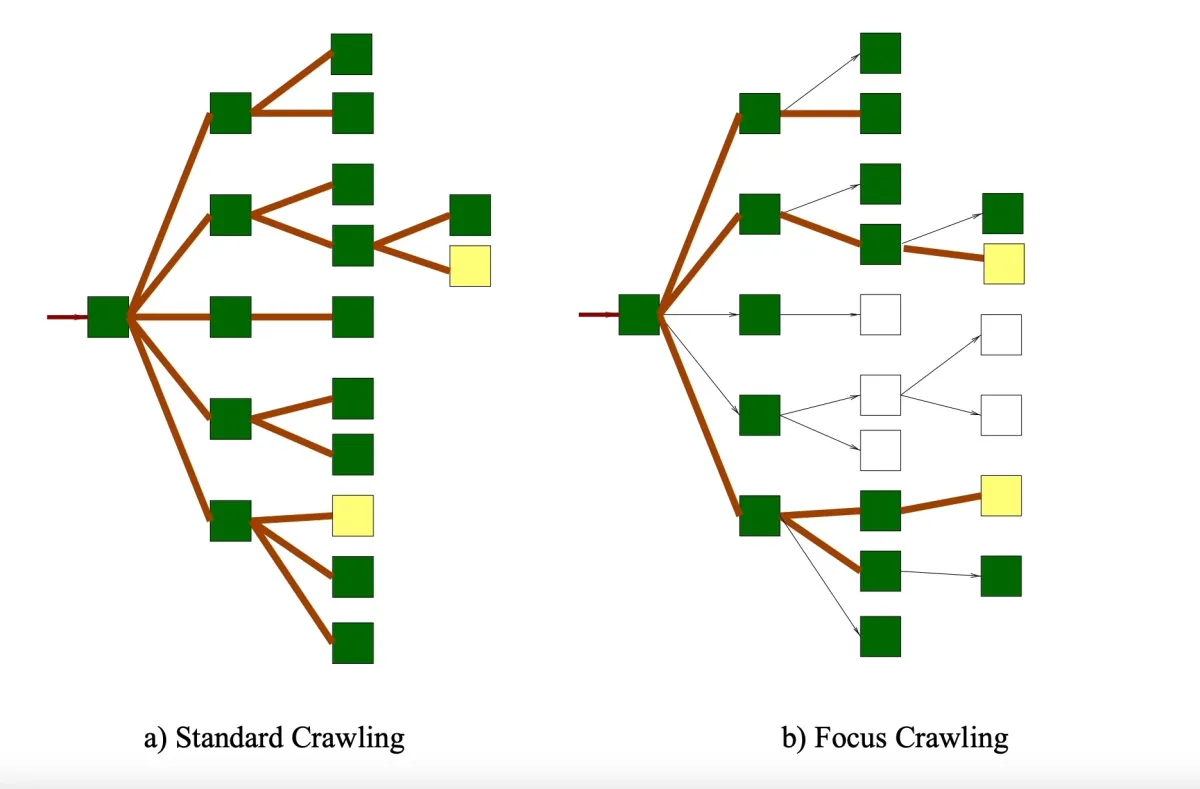
- Incremental crawler: Once a web page is indexed and crawled by a web crawler, the crawler revisits the URLs and refreshes its collection regularly to replace out-of-date links with new URLs. The process of revisiting URLs and recrawling old URLs is referred to as incremental crawling. Recrawling pages helps to reduce inconsistency in downloaded documents.
- Distributed crawler: Multiple crawlers are operating simultaneously on different websites to distribute web crawling processes.
- Parallel crawler: A parallel crawler is a crawler that runs multiple crawling processes in parallel to maximize the download rate.
What are the challenges of web crawling?
1. Database freshness
Websites’ content is updated regularly. Dynamic web pages, for example, change their content based on the activities and behaviors of visitors. This means that the website’s source code does not remain the same after you crawl the website. To provide the most up-to-date information to the user, the web crawler must re-crawl those web pages more frequently.
2. Crawler traps
Websites employ different techniques, such as crawler traps, to prevent web crawlers from accessing and crawling certain web pages. A crawler trap, or spider trap, causes a web crawler to make an infinite number of requests and become trapped in a vicious crawling circle. Websites may also unintentionally create crawler traps. In any case, when a crawler encounters a crawler trap, it enters something like an infinite loop that wastes the crawler’s resources.
3. Network Bandwidth
Downloading a large number of irrelevant web pages, utilizing a distributed web crawler, or recrawling many web pages all result in a high rate of network capacity consumption.
4. Duplicate pages
Web crawler bots mostly crawl all duplicate content on the web; however, only one version of a page is indexed. Duplicate content makes it difficult for search engine bots to determine which version of duplicate content to index and rank. When Googlebot discovers a group of identical web pages in search result, it indexes and selects only one of these pages to display in response to a user’s search query.
Top 3 web crawling best practices
1.Politeness/Crawl rate
Websites set a crawl rate to limit the number of requests made by web crawler bots. The crawl rate indicates how many requests a web crawler can make to your website in a given time interval (e.g., 100 requests per hour). It enables website owners to protect the bandwidth of their web servers and reduce server overload. A web crawler must adhere to the crawl limit of the target website.
2. Robots.txt compliance
A robots.txt file is a set of restrictions that informs web crawler bots of the accessible content on a website. Robots.txt instructs crawlers which pages on a website they may crawl and index to manage crawling traffic. You must check the website’s robots.txt file and follow the instructions contained within it.
3.IP rotation
Websites employ different anti-scraping techniques such as CAPTCHAs to manage crawler traffic and reduce web scraping activities. For instance, browser fingerprinting is a tracking technique used by websites to gather information about visitors, such as session duration or page views, etc. This method allows website owners to detect “non-human traffic” and block the bot’s IP address. To avoid detection, you can integrate rotating proxies, such as residential and backconnect proxies, into your web crawler.
See our guide top 7 web scraping best practices for more information on web scraping and crawling best practices.
What are examples of web crawling?
All search engines need to have crawlers, some examples are:
- Amazonbot is an Amazon web crawler for web content identification and backlink discovery.
- Baiduspider for Baidu
- Bingbot for Bing search engine by Microsoft
- DuckDuckBot for DuckDuckGo
- Exabot for French search engine Exalead
- Googlebot for Google
- Yahoo! Slurp for Yahoo
- Yandex Bot for Yandex
For more on web scraping
To explore web scraping use cases for different industries, its benefits and challenges read our articles:
- Web Scraping Tools: Data-driven Benchmarking
- 7 Web Scraping Best Practices You Must Be Aware of
- The Ultimate Guide to Efficient Large-Scale Web Scraping
- Top 5 Web Scraping Case Studies & Success Stories
For guidance to choose the right tool, check out data-driven list of web scrapers, and reach out to us:
External Links
- 1. Diligenti, M.; Coetzee, F.M.; Lawrence, S., Giles, C. L.; Gori, M. “Focused Crawling Using Context Graphs“. Retrieved January 9, 2023.


Comments
Your email address will not be published. All fields are required.