We benchmarked the leading web scraper API services using 12,500 requests across various domains, including e-commerce platforms such as Amazon and Target, as well as search engines.
Each request was sent in real-time and synchronously. See the top web scraping APIs and follow the links to learn more from the vendors:
| Provider | Focus | |
|---|---|---|
1. | Market-leading range of web scraping APIs at cost-effective prices with detailed results | |
2. | Market-leading range of web scraping APIs in e-commerce | |
3. | Market-leading range of web scraping APIs in e-commerce & affordable entry prices | |
4. | All-in-one scraping API solution | |
5. | Market-leading range of web scraping APIs thanks to its community-driven approach | |
6. | Market-leading prices | |






These APIs are for public data. If you are instead looking for APIs that allow web users to collect their or their app users’ private data, you can see examples of web APIs.
The best web scraping APIs
| Vendors | Starting price (mo) | Pricing model | PAYG plan | Free trial |
|---|---|---|---|---|
| Bright Data | $499 | Subscription-based | $1.5 /1k results | 20 free API calls |
| Oxylabs | $49 | Subscription-based | ❌ | 5K free requests |
| Decodo | $29 | Subscription-based | ❌ | 3K free requests |
| Apify | $2 per 1,000 pages scraped | Pricing varies based on resource usage | ✅ | Monthly $5 credits |
| Zyte | $0.13 per 1,000 requests | Pricing depends on website tier and rendering | ✅ | $5 free credit for a month |
| NetNut | $99 | Subscription-based | ❌ | 7 days |
| Nimble | $150 | Subscription-based | $3/CPM | 7 days |
| SOAX | $90 | Pricing varies based on chosen API | ❌ | 7 days |
Web scraping API availability
E-commerce APIs
E-commerce APIs are offered by most providers:
| Page type | Bright Data | Oxylabs | Decodo | Zyte | Apify | NetNut |
|---|---|---|---|---|---|---|
| Amazon product | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Amazon search | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Target product | ✅ | ❌** | ❌** | ✅ | ❌* | ❌ |
| Walmart product | ✅ | ✅ | ✅ | ❌** | ❌** | ❌ |
| Walmart search | ❌** | ✅ | ✅ | ✅ | ❌** | ❌ |
* Though Apify offers scraping APIs for these page types via its community-maintained APIs, we were not able to access these Actors as part of the plan provided to us by Apify.
** These scrapers exist, but their success rate was below our threshold (>90%).
Ranking: Providers are sorted from left to right based on the number of APIs that they offer. If they offer the same number of APIs, they are listed in alphabetical order.
For more, see eCommerce-scraping APIs.
Social media APIs
While some providers offer many social media APIs, some don’t offer any:
| Page type | Bright Data | Apify | Decodo | NetNut | Oxylabs | Zyte |
|---|---|---|---|---|---|---|
| ✅ | ✅ | ❌ | ❌ | ❌ | ❌ | |
| ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | |
| ✅ | ❌*** | ❌ | ❌ | ❌ | ❌ | |
| TikTok | ✅ | ❌** | ❌ | ❌ | ❌ | ❌ |
| X.com | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |
A social network is included with a ✅ only if
- It has an API for all the page types in that social network in our benchmark set, and
- Its API has a>90% success rate
Learn more about social media scraping and detailed benchmark results.
Search engine APIs
Search engine APIs are offered by all providers:
| Page type | Apify | Bright Data | Smartproxy | Oxylabs | NetNut | Zyte |
|---|---|---|---|---|---|---|
| ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Bing | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
For more: SERP APIs.
Web scraping API Benchmark results
You can see the average number of fields returned by scrapers in 3 categories. The size of each data point represents the number of page types available for scraping for each provider. We also provided median response times. For definitions, see methodology.
How to interpret results?
In scraping, there is a tradeoff between the response time and the amount of data to be retrieved. Since scraping users require fresh data, these services collect data using proxies or unblockers after the client’s request. The more pages that need to be crawled, the longer it takes to return the data.
For example, scraping a search result page on Amazon can either return
- links to products uncovered by search
- Basic data about these products including their pricing.
- A comprehensive dataset about these products including their reviews etc. This will require crawling pages of all products featured in the search page.
The latter approach is what Bright Data’s Amazon Products – Discover by Search URL product follows. As a result, this product’s retrieval time can be significantly longer than that of other scraping APIs.
Features
Bright Data allows users to specify the data that they will retrieve and receive faster responses with its custom IDE scrapers.
Custom IDE scraper is a way to customize an off-the-shelf web scraping API. Bright Data’s custom IDE module reduced the response time to 3.5 seconds when we reduced the amount of data we requested.
Custom IDE module has ready-to-use templates for commonly used websites (e.g., Amazon, YouTube, Facebook) and also enables the user to modify the templates.
Providers

Bright Data
Best for enterprise-compliant & cost-effective APIs for large-scale use casesBright Data offers over 230 web scraper APIs, encompassing a diverse range of data sources, including social media, e-commerce, real estate, and travel. Additionally, it offers proxy-based APIs like Web Unlocker and SERP API.
Bright Data’s Web Scraper API offers two data collection options: the Scraper API, designed for technically proficient teams seeking complete control and automation, and the no-code scraper, ideal for users who prefer a simple, user-friendly interface.
These scraper APIs are equipped with a proxy pool that allows for targeting at both the country and city levels across any location.

Oxylabs
Oxylabs offers a general-purpose web scraping API that can be used for various domains. Oxylabs provides dedicated endpoints, also known as parametrized sources, for specific websites and platforms
Their web scraping APIs allow targeting at the country level in 195 locations, while the SERP Scraper API provides more precise targeting options, such as city and coordinate-level targeting. Their Web Scraper API supports a headless browser for rendering and extracting data from JavaScript-heavy websites.

Decodo
Best for flexible scraping API packages & affordable entry priceDecodo offers two primary Web Scraping API services, Core and Advanced, for different data extraction projects. Core plan is ideal for sers who need basic scraping capabilities without advanced features. Its geo-targeting is limited to 8 countries.
Advanced plan covers advanced features such as JavaScript rendering, structured data outputs (JSON/CSV), global geo-targeting
The scraping APIs from Smartproxy include essential features like proxy rotation, anti-detection methods, and JavaScript rendering.

Apify
Best for developer-focused web scraping with ready-made solutionsApify is a developer-focused web scraping platform that offers pre-made scrapers and automation tools called Actors. Actors are designed to automate actions or extract data from social media sites, e-commerce platforms, review sites, job portals, and other websites. Every Actor can be accessed via API using Python, JavaScript, or HTTP requests.
You can use Actors as they are, ask to modify them for your use case, or create your own. Developers can create and run Actors in various programming languages (such as JavaScript/TypeScript and Python) by using code templates, universal scrapers, or the open-source web scraping library, Crawlee.
Apify operates on a cloud-based infrastructure with built-in scraping features, including datacenter and residential proxies, automatic IP rotation, CAPTCHA solving, monitoring, scheduling, and integrations.
Zyte
Best for users looking for a all-in-one scraper API solutionZyte provides a general-purpose scraper API with proxy management features and browser automation capabilities. The scraper API allows for handling request headers, cookies, and toggling JavaScript.

Nimble
All-in-one API solution including unblocker, residential, and APINimble offers general-purpose, SERP, e-commerce, and maps APIs featuring integrated rotating residential proxies and unlocker proxy solutions. The Web API is capable of handling batch requests, allowing up to 1,000 URLs in each batch.

NetNut
NetNut provides SERP Scraper (Google) and LinkedIn API, offering customization options to modify requests based on various parameters such as geographic location, pagination, and localization preferences, including language and country settings.

SOAX
SOAX offers social media, SERP, and eCommerce APIs. The vendor provides built-in proxy management capabilities and handles pagination. Users can set a max page parameter for scraping multiple pages.
Web scraping APIs: Benchmark methodology
Test URLs
We used 3 URL groups in testing:
- 1,700 eCommerce URLs, as explained in the e-commerce scraper benchmark.
- 1,100 social media URLs as outlined in the social media scraper benchmark.
- 200 query result pages, as explained in the SERP API benchmark.
Speed & latency
- Proxies and web unblocker: Response time is measured.
- Scraping API: Response time is calculated as the difference between webhook callback time and request time.
All providers’ response times are calculated in the same set of pages where they all returned successful responses. It would not be fair to compare the response time of an unsuccessful response to a successful one, since an unsuccessful response can potentially be generated much faster.
For example, if four unblockers were run on 600 URLs and they all returned successful results for only 540 URLs, these 540 URLs form the basis of the response time calculation.
Success rates
Requirements for a successful request for a web scraper API:
- HTTP response code: 200
- A response longer than 500 characters
If a web scraper returns successful results more than 90% of the time for a specific type of page (e.g. Walmart search pages) and if the correctness of the results is validated by random sampling of 10 URLs, then we list that provider as a scraping API provider for that type of page.
Most scraper APIs had more than 90% success rates for their target pages. Therefore, rather than focusing on 1-2% differences between different APIs, we list all APIs that returned successful results more than 90% of the time.
Even though we used fresh URLs, a small percentage of URLs were discovered to return 404 during the test. They were excluded from the test.
Determining participants
- Web scraper APIs: Participants’ websites were scanned to identify relevant scrapers.
- Proxies: All providers except Zyte were included.
Average # of fields
- For each successful API result, we count the number fields returned in the JSON file. Each key is counted regardless of its value.
What is a web scraping API?
An API is a tool that facilitates communication between clients and web servers, allowing data exchange rather than data collection. If a website supports API functionality, it can be used to retrieve data. APIs fall into these categories:
- Scraping APIs: Hosted by web data infrastructure providers, they convert publicly available web pages into structured data.
- Other public APIs: Hosted by external providers like Facebook or Google, these APIs are available to developers and can be free or require registration.
- Internal APIs: Restricted to use within an organization, these private APIs enable secure internal communication and data transfers. Regardless of the type, APIs can pose security risks if not properly managed.
When to use a web search API instead of a web scraping API?
A web search API allows users to retrieve search engine results programmatically and is commonly used for SEO tracking and competitive research.
You can use web scraping APIs for scraping search queries, but not all web scraping APIs are suitable for SERP scraping. Web scraping APIs extract data directly from specific websites, whereas web search APIs return indexed data from search engines such as Google or Bing. You can prefer the web search APIs for analyzing search engine results
4 examples of web APIs
These are example public APIs that include web data:
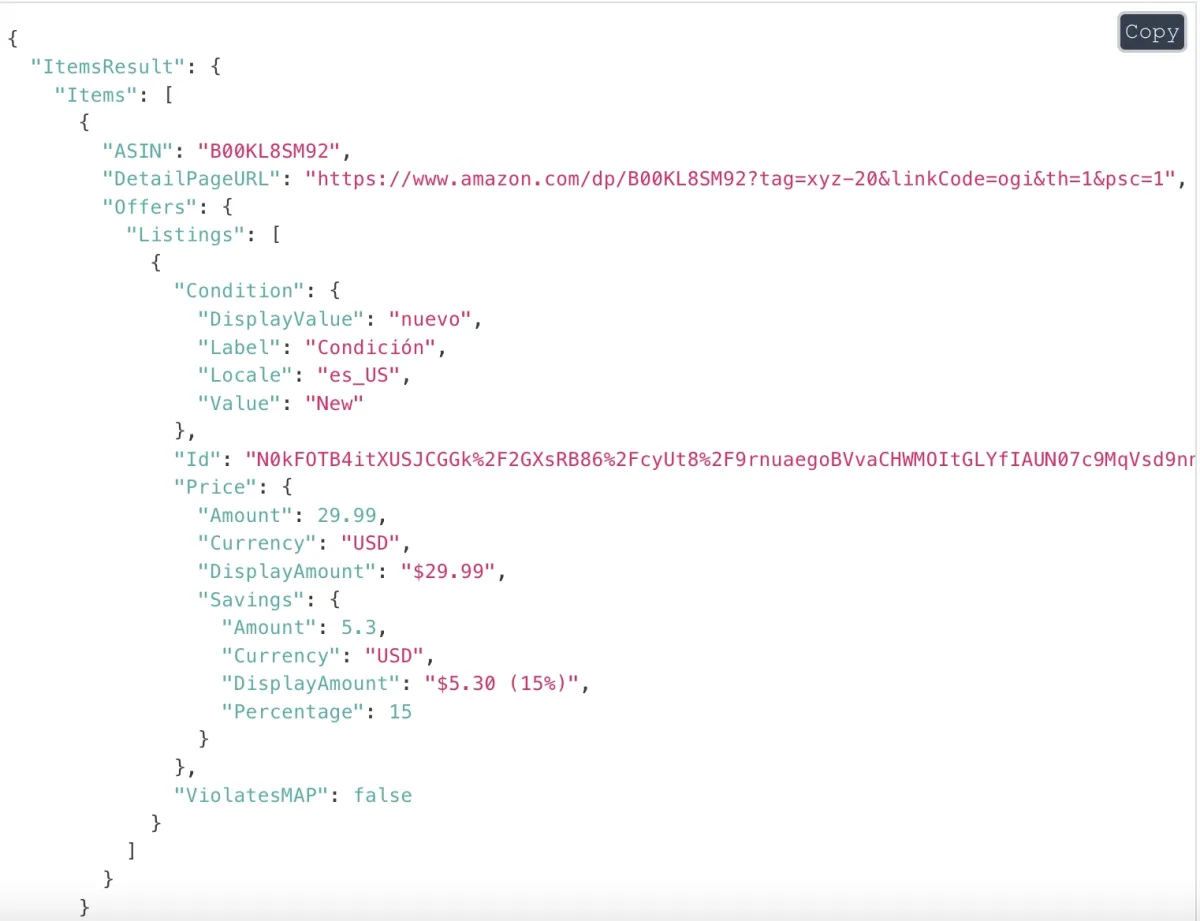
1. Amazon Product Advertising API
This API gives users access to Amazon’s product data, including customer reviews and product information. To use it, users must register for the Product Advertising API and have an Amazon Associates account. Through HTTP client requests with specified parameters like keywords or brands, users can retrieve details for up to 10 products per search.
Once you have registered the Product Advertising API, you can send requests to the API using an HTTP client. You can search for a specific item on Amazon by requesting parameters supported by the API, such as keywords, titles, and brands.
Figure 1: Product output obtained from the Amazon product page using an API request.
2. Google Analytics Data API
Google Analytics Data API v4 provides free access to GA4 data, allowing users to display and collect report data. The API supports generating reports like pivot tables, cohort analysis, and lifetime value reports, helping users analyze their website’s performance.
3. Twitter API
The Twitter API allows developers to extract Twitter data, subject to rate limits, after signing up for a developer account. Businesses can use the API to analyze historical and real-time data. For example, LikeFolio uses the API to analyze social data and predict shifts in consumer trends, as demonstrated by its use of Twitter data to inform investment strategies. 2
The chart below compares the stock price in gray to the disparity in consumer mentions of Roku goods and services in green.
Figure 2: The difference between the stock price and consumer demand for the company’s goods and services.
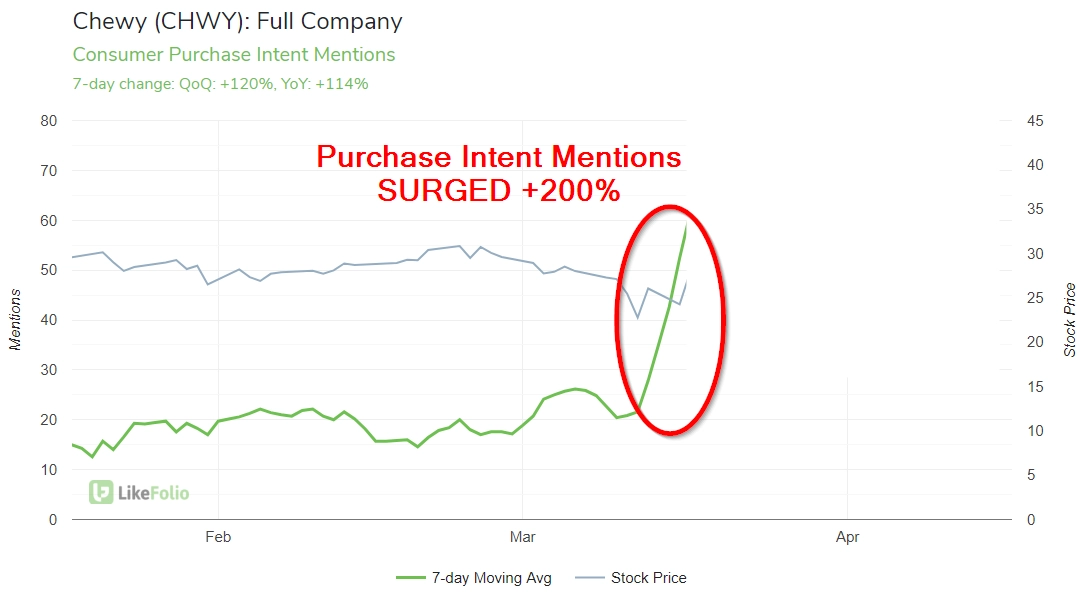
Source: Twitter Developer Platform
4. Instagram API
The Instagram Basic Display API enables businesses and creators to access publicly available Instagram data, such as profiles, images, and hashtags. However, the API imposes restrictions on data access, like limiting hashtag requests to 30 per week. Access requires a Facebook developer account and a registered website.
Figure 3: An example of obtaining image data from Instagram using API
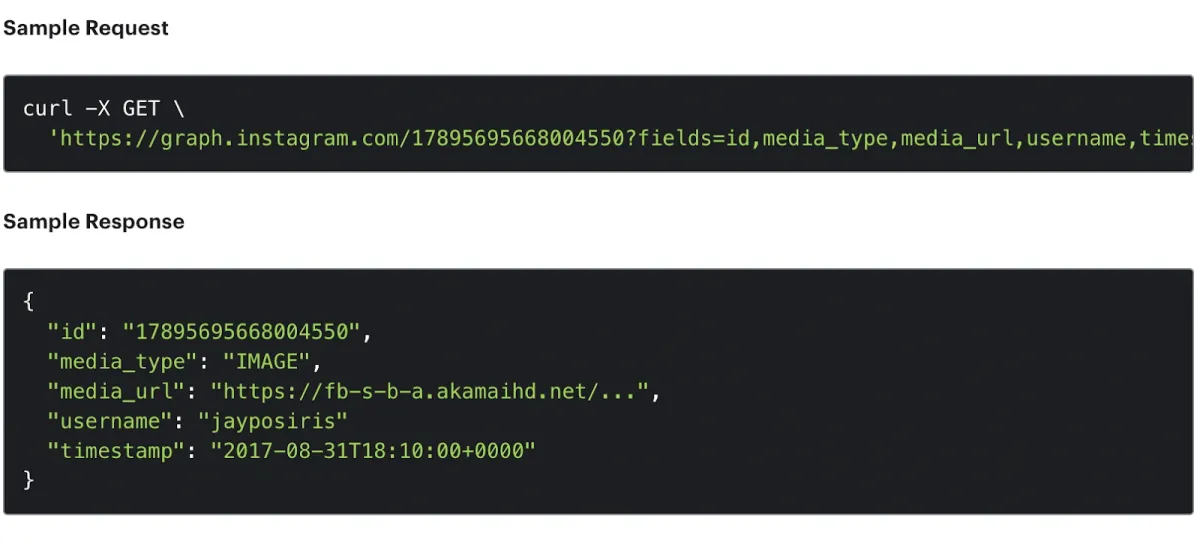
Source: Meta
Data extraction with APIs: Why and when should you use APIs?
There are a few common methods for obtaining data, including pre-packaged datasets, collecting your own data, or data from outside sources. Either way, when it comes to data collection, you will need a tool to handle data collection issues.
Web scraping tools and APIs enable businesses to collect data from internal and external sources. However, they have some differences regarding technical effort, cost, and data accessibility.
The technical difficulty of web scrapers varies depending on whether you use in-house or outsourced web scrapers. However, web scraping tools are less flexible than code-based web scraping solutions such as scraping APIs.
If you have basic programming knowledge and do not have a budget for pre-built web scraping solutions, you can use APIs for your data collection projects.
However, the website from which you want to collect the data must provide the API technology if you intend to use APIs for data collection. Otherwise, APIs cannot be an option to collect data.
APIs, such as the Twitter API, are provided by the website from which you require the data. Because the website’s API provides the data, requesters have authorized access to it. You need not be concerned about being identified as a malicious actor. You must, however, follow the terms and conditions outlined in their API guideline.
Key features to consider while choosing web scraping API
1. JavaScript rendering
Websites collect data and provide tailored content based on visitor activities using various tracking techniques such as browser fingerprinting, cookies, and web beacons. Every time a user visits a website, the content changes.
Dynamic websites utilize client-side scripting to dynamically change content based on users’ input and behaviors, such as resizing images according to users’ screen sizes or displaying website content based on visitors’ countries.
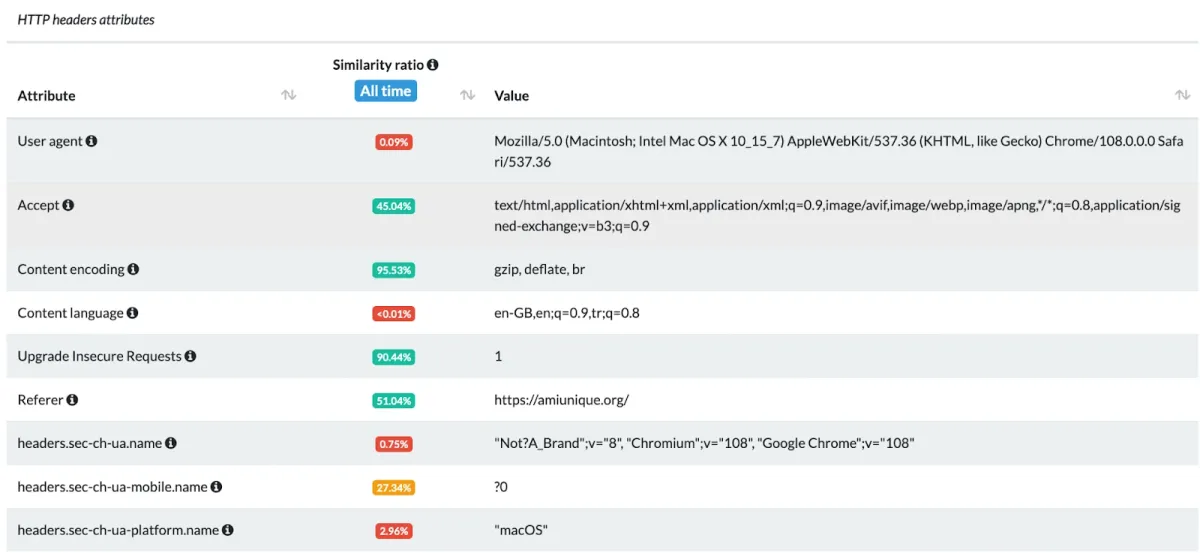
For example, when you make a connection request to an API to access the target website’s data, the API receives your request and returns the requested information. Unless you use a headless browser, the target web server and the website’s API can access information about your device, such as your machine’s IP address, browser type, geolocation, and preferred language, along the way (see Figure 5).
JavaScript rendering handles the parsing of HTML, CSS, and images on the requested page, and displays the parsed content in the client’s browser screen.
To render dynamic website content, you need to make an HTML request to the target website and invoke the render function to run JavaScript code in the background, displaying the web content in your browser. If you do not want to deal with dynamic web page rendering, you should look for a scraping API that supports JavaScript rendering.
Figure 5: Example of a browser fingerprinting
2. Unlimited bandwidth
The maximum rate of data transfer in a computer network is referred to as bandwidth. The amount of data you need to collect should be balanced by your bandwidth rate. Otherwise, the data transferred from the web server to your machine will exceed the maximum data transfer rate, resulting in bandwidth throttling. Unlimited bandwidth allows businesses to:
- Manage data traffic in the network
- Keep data speed under control and allow for much faster data transmission than a constrained bandwidth rate
- Receive large amounts of data from other servers without bandwidth throttling
3. CAPTCHA & Anti-Bot Detection
Websites employ various anti-scraping techniques, such as Robots.txt, IP blockers, and CAPTCHA, to manage the connection requests to their websites and protect their content from a specific type of attack, such as bots.
CAPTCHA (Completely Automated Public Turing Test to Tell Computers and Humans Apart) is an anti-scraping method used by web services such as Google to prevent unauthorized users from accessing web data. CAPTCHAs are programmed to be unreadable by machines. Websites use CAPTCHA technologies to distinguish between human and malicious bot activities. There are three types of CAPTCHAs:
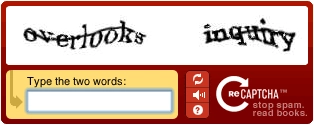
- Text-based: This CAPTCHA type requires users to retype distorted words and numbers they see in a given image (see Figure 6). The provided text is unrecognizable by bots.
Figure 6: An example of text-based CAPTCHA
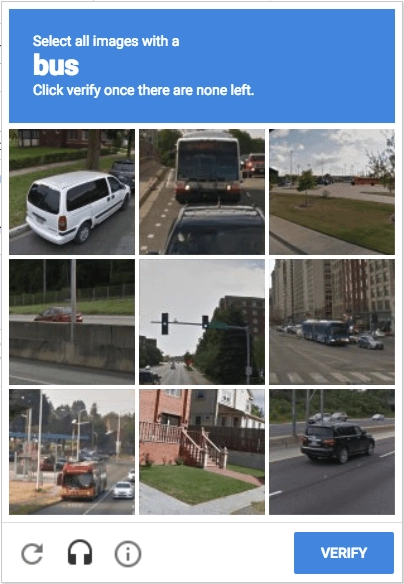
- Image-based: Image-based CAPTCHAs use object detection and target recognition technologies. The user is asked to select specific objects from a set of images that the website provides (see Figure 7).
Figure 7: An example of image-based CAPTCHA
- Audio-based: When you click the audio icon in a distorted image, it will speak the letter in the image for you, accompanied by some gibberish noises to prevent bots.
If the target website from which you need data has its API, you do not need to worry about the legality of data scraping or being detected by the website. However, if you use a third-party scraping API solution, you need to either overcome the captcha yourself or outsource the captcha solving to the service provider.
Learn more about web scraping best practices
4. Auto Parsing
After data extraction, the collected data may be structured, semi-structured, or unstructured as it is gathered from various data sources. To extract value from collected data, you must parse the extracted data to convert it into a more readable format.
You can build your own parser or leverage outsourced data parsing tools to convert the extracted data into the desired format. However, in-house data parsing tools might have additional overhead costs. Outsourcing the development and maintenance of data parsing infrastructure will allow you to focus on data analysis.
5. Geotargeting
Websites block or restrict access to specific content based on users’ geolocations for various reasons, including fraud prevention, price discrimination, and blocking malicious traffic. Scraping APIs enable users to access geo-targeted content, providing localized information.
6. Automatic Proxy Rotation
The crawl rate limit is an anti-scraping technique that websites use to manage the volume of requests to their websites. When a client repeatedly requests a web server’s API from the same IP address, the website recognizes the client as a bot and restricts access to the web content. Automatic proxy rotation enables clients to change their IP addresses for each connection request.



Comments
Your email address will not be published. All fields are required.