

Businesses use a variety of data sources, including internal sources (e.g., CRM, ERP), external sources (e.g., social media platforms), and third-party web analytics services ( e.g., Google Analytics). Through the diversity of data sources, businesses use different technologies to capture data from their sources such as web scraping tools and browser fingerprinting technologies.
Apart from the diversity of data sources, it is difficult for businesses to capture large amounts of data, convert it into a unique data format, and store it in a unified repository. Data pipeline tools allow companies to extract, process, and transform data in order to make the most out of their data.
In this article, we explore the top 7 data pipeline tools & 4 main capabilities of data pipeline tools to assist businesses in selecting the best fit for their business applications.
What is a data pipeline?
Data pipeline is the process of moving data from one data source to a target repository. Businesses can use data pipeline tools to extract data from various sources and load it into a destination such as a data warehouse or data lake. Along the way, data pipeline architecture ingests and organizes extracted data, allowing business analysts and other users to analyze and gain insights.
How does a data pipeline work?
The type of data pipeline varies depending on the business use case, such as simple reporting, building a machine learning model, or a data science project. Streaming, batch, and hybrid data pipeline processing are the three types of data pipeline processing techniques.
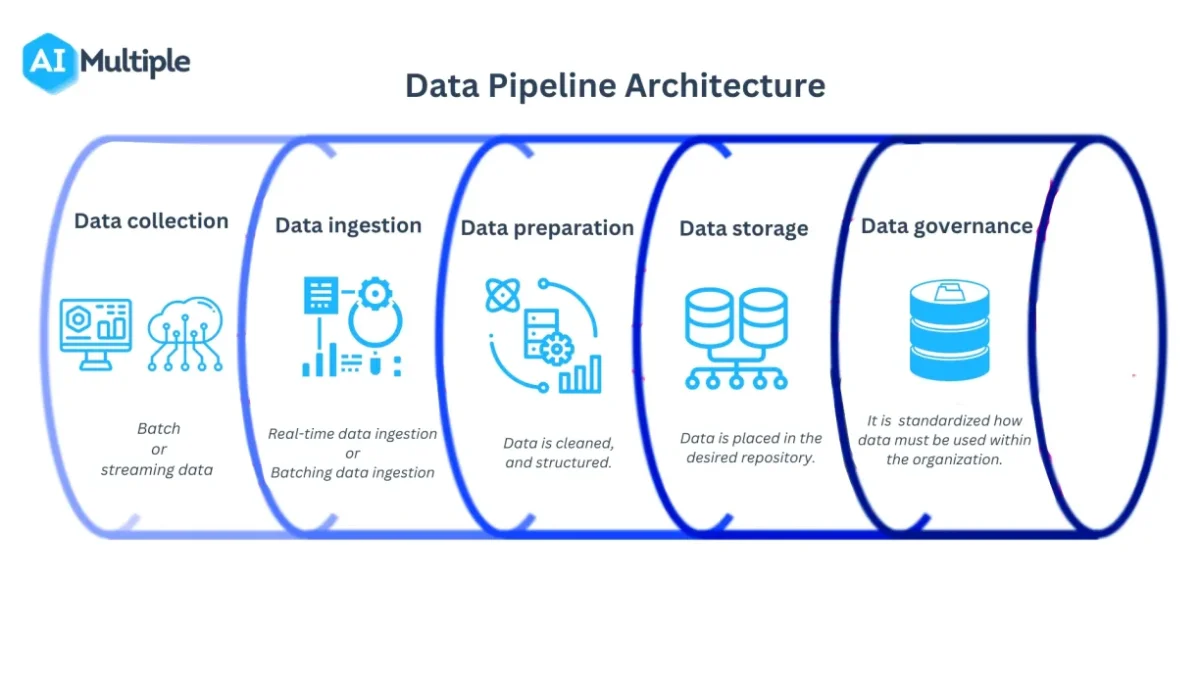
A data pipeline process typically consists of five steps (see Figure 2):
- Data collection: Data can be collected in batches (e.g., a traditional database) or in real-time (e.g., sensors or sales transactions).
- Data ingestion: Stream or batch ingestion is used to extract data. For example, if you want to extract data from an IoT system, you must use the stream ingestion method. However, if data is extracted at regular intervals. Then you must process and store the data in batches.
- Data preparation: Data is cleaned and organized.
- Data storage: Data is placed in the target repository.
- Data governance: It is the process of identifying and standardizing how various departments within an organization should use data.
Figure 2: The diagram represents the main phases of data pipeline architectures.
Why do you need a data pipeline tool?
Businesses have a large amount of data stored in their data sources and applications. However, when it comes to moving data from one location to another, data can be lost, duplicated, or breached along the way. Data pipeline tools allow businesses to automatically ingest data from multiple sources and transfer it to a target repository while ensuring data quality.
What are the different types of off-the-shelf data pipeline tools?
1. Open-source data pipeline tools
An open source data pipeline tools is freely available for developers and enables users to modify and improve the source code based on their specific needs. Users can process collected data in batches or real-time streaming using supported languages such as Python, SQL, Java, or R.
2. Batch data pipeline tools
Batch-based data pipelines extract data (i.e. historical data) from multiple data sources and transfer data into a repository, such as a data lake or data warehouse, at regular intervals but not in real time. Batch data pipeline tools collect data from various sources and store it in a database, such as data warehouses or data lakes, for later processing.
3. Real-time/streaming data pipeline tools
Data streaming refers to the continuous flow of data with no beginning or end points, such as activity logs, IoT, and sensors from company web browsers. Real-time data pipeline tools enable businesses to process, store and analyze streaming data in real time. Streaming data pipeline tools, as opposed to batch data pipeline tools, process and analyze incoming data as it is generated in order to get real insights from data.
4. On-Premise data pipeline tools
On-premises data pipeline tools extract data from any on-premises source, process it based on business requirements, and then transfer it to a local server. Businesses have more data control with an on-premises data pipeline tool because it is integrated into the organization’s internal system.
5. Cloud-based data pipeline tools
Cloud-based data pipeline tools, also known as cloud orchestrators, enable businesses to process and store large amounts of data. Data is stored in cloud-based storage like cloud data warehouses. Cloud-based data pipeline tools apply data processing on the cloud to provide users with data in the required format, and cloud-based data pipeline solutions make it easy to use and access data when needed.
How to select a data pipeline tool
1. Data streaming
Streaming data refers to data that is generated on a continual basis by different sources such as IoT sensors, e-commerce purchases, system logs, etc. Companies use streaming data for various purposes, including real-time fraud detection, tracking stock market changes, and making real-time property recommendations.
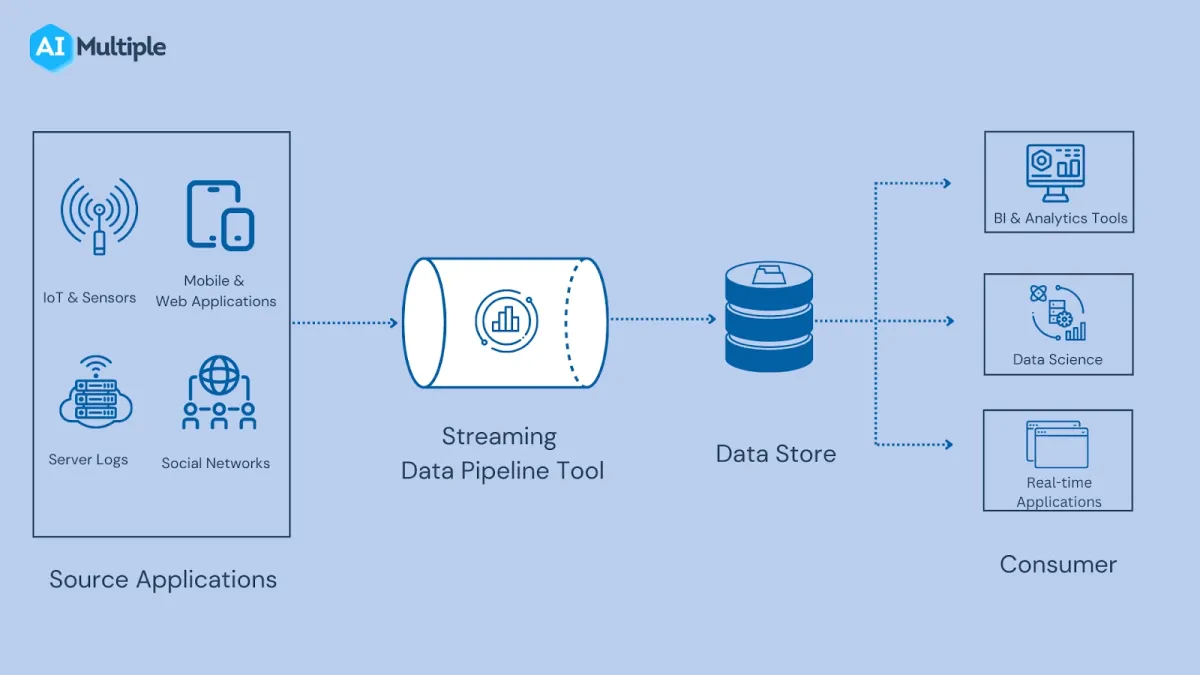
Streaming data, on the other hand, is time sensitive. You must process streaming data as it is generated to gain valuable insights. Streaming data processing enables businesses to extract data from data producers such as databases, IoT, and SaaS applications in real-time. Extracted data is processed incrementally and passed to another database or an application (see Figure 4).
Figure 4: Representation of a streaming data pipeline workflow.
2. Cloud-Scale Architecture
According to a 2022 survey, 90% of respondents said multi-cloud helped them achieve their business goals (see Figure 5).1
Businesses can store their data either on-premises or in the cloud. Data pipelines with cloud warehouse solutions allow businesses to store data on databases and warehouses in the cloud. Cloud-based data warehouses, as opposed to traditional data warehouses (also known as on-premise data warehouses), do not require businesses to purchase and maintain hardware.
Figure 5: Global cloud storage market size 2021-2029
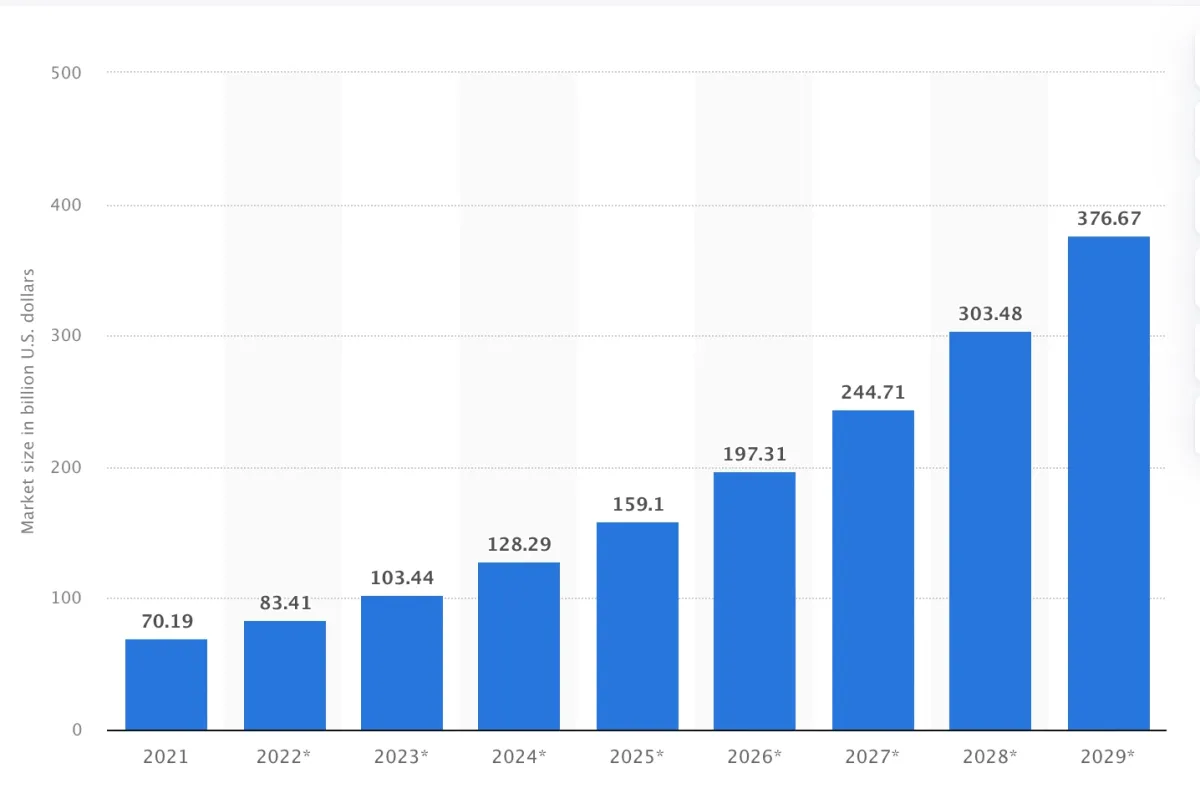
Source: Statista
3. Data warehousing
Data warehousing is the process of organizing and compiling data collected from various sources in a warehouse. Data pipeline tools supporting data warehousing enable businesses to integrate data from multiple sources into a central data warehouse destination.
A destination such as a data warehouse and data lake is the endpoint of the data pipeline process. Data warehouses, unlike data lakes, can only store structured data. Extracted data is cleaned and structured before being stored in the data warehouse.
4. SaaS data sources
Software as a Service (SaaS) is one of the cloud computing solutions. Instead of installing software, SaaS applications provide users with data access via internet-connected devices such as a desktop, laptop, or mobile device.
Data pipeline tools extract data from SaaS applications such as CRM and ERP and transfer it to a destination such as BI, analytics application, or another database.
A data source can be an on-premise, cloud database, or SaaS application. If you intend to collect data from applications such as ERP, HRM or MIS, make sure you pick a data pipeline tool with integrations for SaaS applications.
How did we select top data pipeline vendors?
We chose the vendors based on their employee count and reviews on review platforms. We filtered vendors based on these verifiable criteria:
- 15+ employees on LinkedIn
- 5+ reviews on review sites such as G2, Trustradius, and Capterra.
According to employee and reviews data we have aggregated from public sources, the following companies fit these criteria:
- Fivetran
- Segment
- Hevo Data
- StreamSets
- Striim
- Keboola
- Stitch
Which vendors provide these capabilities?
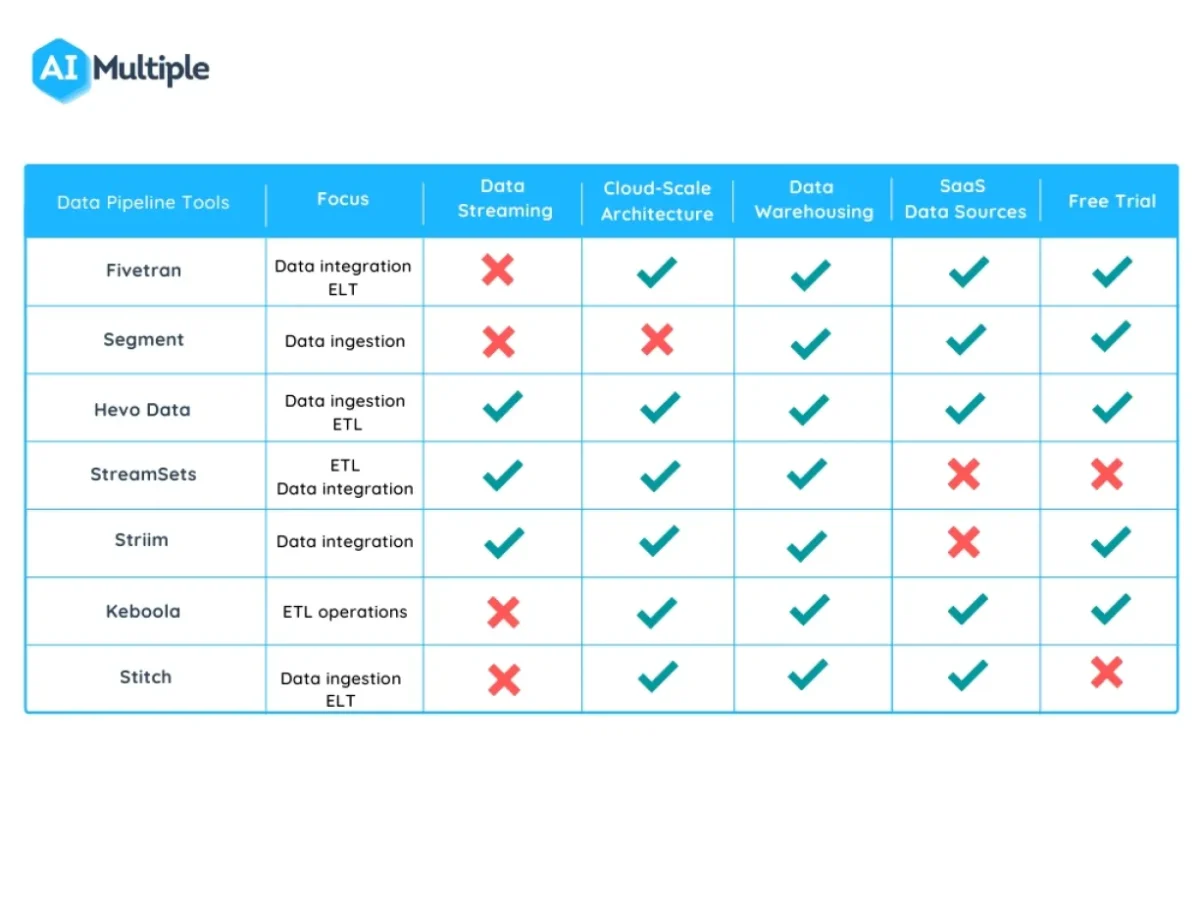
The four main capabilities mentioned above (see “what are the main capabilities to consider when selecting a data pipeline tool?”) are the distinctive features of data pipeline tools.
Figure 7: Comparison of data pipeline vendors based on the main capabilities.
Data pipeline vs. data orchestration
Data pipeline tools: Data pipeline tools focus on moving data from one system to another in a predefined sequence. They enable ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) processes, ensuring data flows smoothly between sources and destinations.
Data orchestration tools: Data orchestration platforms manage and coordinate multiple data pipelines, workflows, and dependencies across systems. They provide a higher level view and control, ensuring data flows are synchronized, optimized, and executed in the right order, especially in complex environments.
Explore other orchestration tools to manage specific workflows and resources, such as:
Limitations and next steps
We relied on vendor claims to identify the capabilities of data pipeline tools. As we have a chance to try out these tools, we will update the above table with the actual capabilities of these tools observed in our research.
If we missed any data pipeline provider or our tables are outdated due to new vendors or new capabilities of existing tools, please leave a comment.
If you have any additional questions about data pipeline tools, let us know:


Comments
Your email address will not be published. All fields are required.