Whether it’s a self-driving car crash, a biased algorithm, or a breakdown in a customer service chatbot, failures in deployed AI systems can have serious consequences and raise important ethical and societal questions.
By identifying and addressing the underlying issues, companies can mitigate the risks associated with AI and ensure that it is used safely and ethically in line with responsible AI best practices.
Discover 4 common reasons for the high rates of AI project failures and explore real-world examples.
1. Unclear business objectives
Artificial intelligence is a powerful technology, but implementing it without a well-defined business problem and clear business goals is not enough to succeed. Instead of starting from the solution for an indefinite business problem, companies must first determine and define business problems and then decide whether AI techniques and tools would help solve them.
Besides, measuring the costs and potential benefits of an AI project is challenging because:
- Developing an AI project and building/training an AI model is experimental in nature and may require a long trial-and-error process.
- AI models try to solve probabilistic business problems, meaning the outcomes may not be the same for each use case.
A well-defined business goal can provide a clear idea of whether AI is the right tool or whether there are alternative tools or methods to solve the problem at hand. This can save companies from unnecessary costs.
2. Poor data quality
Data is the key resource of every AI project. Businesses must develop a data governance strategy to ensure the availability, quality, integrity, and security of the data they will use in their project. Working with outdated, insufficient, or biased data can lead to garbage-in-garbage-out situations, failure of the project, and wasting business resources:
Overfitting: Memorizing instead of learning
Overfitting occurs when AI models become overly specialized in training data and fail to generalize to new inputs. This AI failure is common in deep learning models used in financial fraud detection, where the tool may only recognize past fraud patterns and miss emerging tactics.
Overfitting is a major reason AI projects fail, as AI-powered technologies must adapt to dynamic environments rather than rely on historical patterns. Poor data quality and lack of AI observability often exacerbate this issue.
Edge-case neglect: Overlooking rare scenarios
Edge cases—uncommon yet critical scenarios—often lead to AI systems making wrong decisions. In autonomous vehicles, an AI chatbot designed for navigation may fail to process unusual driving conditions.
Ignoring edge cases in AI initiatives can result in financial losses, safety risks, and loss of customer trust. Organizations with large language and deep learning models must integrate high-quality data to improve edge-case handling.
Correlation dependency: False assumptions and discriminatory outcomes
AI projects frequently fail due to models mistaking correlation for causation. For instance, an AI-powered hiring system might favor applicants from a specific zip code, not due to skills but due to biases embedded in training data. This can result in discriminatory outcomes.
Data bias: Reinforcing inequality and ethical implications
Data bias is a critical issue in AI initiatives, particularly in machine learning models used for decision-making. A well-known example is healthcare AI models trained primarily on data from white patients, leading to inaccurate diagnoses for non-white patients.
Such biases embedded in AI technologies can create ethical implications and legal challenges. Organizations must focus on data science best practices to avoid poor data quality and improve accuracy in AI projects.
Underfitting: AI models that lack complexity
Underfitting happens when ML models are too simplistic, leading to poor performance. A poorly designed AI chatbot, for instance, may struggle to differentiate between user intent, resulting in chatbot lies and incorrect recommendations.
AI projects fail when organizations rely on under-trained models without refining their ability to process complex patterns. The critical importance of AI observability and continuous model improvement cannot be overlooked.
Data drift: AI’s struggle to adapt to change
AI tools assume data remains consistent over time, but real-world changes—such as shifting customer behavior on a social media platform—can lead to data drift.
AI models used in financial forecasting or legal research must be updated frequently to maintain accuracy. Organizations investing in AI technologies must prioritize AI observability to ensure models remain reliable as millions of new data points emerge.
Before embarking on an AI project, companies should ensure that they have sufficient and relevant data from reliable sources that represent their business operations, have correct labels, and are suitable for the AI tool deployed. Otherwise, AI tools can produce erroneous outcomes and be dangerous if used in decision-making.
Data collection experts can help your business if you do not have good quality data readily available.
3. Lack of collaboration between teams
Having a data science team working in isolation on an AI project is not a recipe for success. Building a successful AI project requires collaboration between data scientists, data engineers, IT professionals, designers, and line of business professionals. Creating a collaborative technical environment would help companies to:
- Ensure that the output of the AI project will be well-integrated into their overall technological architecture
- Standardize the AI development process
- Share learnings and experience, develop best practices
- Deploy AI solutions at scale
There are sets of practices known as DataOps and MLOps to bridge the gap between different teams and operationalize AI systems at scale. Moreover, establishing a federated AI Center of Excellence (CoE) where data scientists from different business domains can collaborate can improve collaboration.
Learn the similarities and differences between DataOps and MLOps.
4. Lack of talent
Due to this skill shortage, creating a talented data science team can be costly and time-consuming. Without a team with proper training and business domain expertise, companies should not expect to accomplish much with their AI initiative.
Businesses must analyze the costs and benefits of creating in-house data science teams. For more on the advantages and disadvantages of building in-house teams and outsourcing, in-house AI and ML outsourcing.
Depending on your business objectives and the scale of your operations, outsourcing can initially be a more cost-effective alternative to implementing AI applications.
What are some examples of AI project failures?
Apple Intelligence’s misleading news summaries
The BBC lodged a complaint with Apple regarding inaccuracies in Apple’s AI-generated news summaries, known as “Apple Intelligence.” These summaries, delivered as iPhone notifications, erroneously attributed false information to the BBC.
One notable instance involved a notification falsely stating that Luigi Mangione, arrested for the murder of UnitedHealthcare CEO Brian Thompson, had committed suicide—a claim not reported by the BBC.
Subsequent errors included a notification incorrectly announcing that darts player Luke Littler had won the PDC World Darts Championship before the final match occurred.
In response to these issues, Apple acknowledged that its AI features were still in beta and announced plans to temporarily disable the notification summaries for news and entertainment apps. The company also stated that a software update would be released to clarify when notifications are AI-generated, aiming to prevent future misinformation and maintain the integrity of news dissemination.1
Air Canada Chatbot failure
Air Canada faced legal trouble after its AI chatbot misinformed a customer about bereavement fare refunds. The chatbot wrongly stated he could apply for a refund within 90 days of booking, but the airline later denied it, citing its actual policy.
The customer filed a complaint, and a tribunal ruled that Air Canada was responsible for all information on its website, ordering the airline to honor the refund.2
Amazon Alexa’s biased responses
Amazon’s voice assistant, Alexa, faced criticism for providing seemingly biased responses favoring Vice President Kamala Harris over former President Donald Trump.
When users asked Alexa why they should vote for Harris, the assistant highlighted her accomplishments and commitment to progressive ideals. Conversely, when asked the same about Trump, Alexa declined to provide an endorsement, citing a policy against promoting specific political figures.
Amazon attributed this discrepancy to an error stemming from a recent software update intended to enhance Alexa’s AI capabilities. The company stated that the issue was promptly fixed upon discovery and emphasized that Alexa is designed to provide unbiased information without favoring any political party or candidate.3
AI and copywriting challenges at Grammys
In April 2023, an AI-generated track, Heart on My Sleeve, featuring vocals mimicking Drake and The Weeknd, went viral before being removed over copyright concerns. Created by an anonymous TikTok user, the song reached millions of streams.
The creator later submitted it for Grammy consideration, initially deemed eligible since a human wrote it. However, it was later disqualified due to its unauthorized use of AI-generated vocals.
This case has fueled debates on AI’s role in music, copyright challenges, and award eligibility, with the Recording Academy balancing human creativity and technological progress.4
IBM Watson for Oncology
IBM’s partnership with the University of Texas M.D. is a well-known example of an AI project failure. According to StatNews, internal IBM documents show that Watson frequently gave erroneous cancer treatment advice, such as prescribing bleeding drugs for a patient with severe bleeding.
Watson’s training data contained a small number of hypothetical cancer patient data rather than real patient data. According to a report by the University of Texas System Administration, the project cost was $62 million for M.D. Anderson without an achievement.5
Amazon’s AI recruiting tool
Amazon’s AI recruiting tool that discriminated against women is another popular example of AI fail. The tool was trained on a dataset containing mostly resumes from male candidates, and it interpreted that women candidates are less preferable.6
Self-driving cars driving in the opposite lane
Researchers demonstrated that they can mislead a Tesla car’s computer vision system into driving in the opposite lane by placing small stickers on the road. (See Figure 1)7
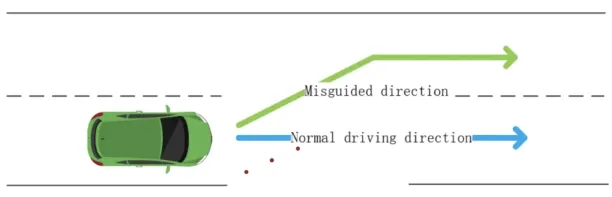
Figure 1: Misguiding a car into driving in the reverse lane by placing stickers on the road.
Racial and sexual discrimination in facial recognition tools
A Guardian investigation found that AI systems from Microsoft, Amazon, and Google—used by social media platforms to recommend content—exhibit notable gender bias in their handling of male and female bodies.
The study revealed that images of women were more frequently labeled as “racy” compared to similar photos of men. In one case, Microsoft’s AI classified images of breast cancer screenings from the US National Cancer Institute as potentially sexually explicit.8
Another example is, AI researchers found that commercial facial recognition technologies, such as those of IBM’s, Microsoft’s, and Amazon’s, performed poorly on dark-skinned females and well on light-skinned men.9
External Links
- 1. BBC complains to Apple over misleading shooting headline. BBC News
- 2. Airline held liable for its chatbot giving passenger bad advice - what this means for travellers. BBC
- 3. Amazon Explains How an Alexa Upgrade Biased Its AI to Favor Kamala Harris. Inc
- 4. Grammys Bar AI-Created Fake Drake and Weeknd Song. Rolling Stone
- 5. IBM's Watson recommended 'unsafe and incorrect' cancer treatments | STAT. STAT
- 6. Amazon Built AI to Hire People, but It Discriminated Against Women - Business Insider. Business Insider
- 7. https://keenlab.tencent.com/en/whitepapers/Experimental_Security_Research_of_Tesla_Autopilot.pdf
- 8. ‘There is no standard’: investigation finds AI algorithms objectify women’s bodies | Artificial intelligence (AI) | The Guardian. The Guardian
- 9. https://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf



Comments
Your email address will not be published. All fields are required.