One-third of customers say they will stop doing business with brands they love after just one bad experience.1 Thus, understanding how customers feel about products or services is crucial for business success. Companies use sentiment analysis methods to understand customers’ sentiments and improve their products and services accordingly.
Here, we provide an overview of sentiment analysis methods and the advantages and disadvantages of each.
Sentiment analysis methods
Sentiment analysis is a natural language processing (NLP) method that helps identify the emotions in text. By categorizing sentiments in social media posts, surveys, or reviews, companies can measure how their strategies work and determine new ones for growth. There are several methods to conduct sentiment analysis, each with its strengths and weaknesses.
Figure 1. An overview of the most frequently used sentiment classification techniques
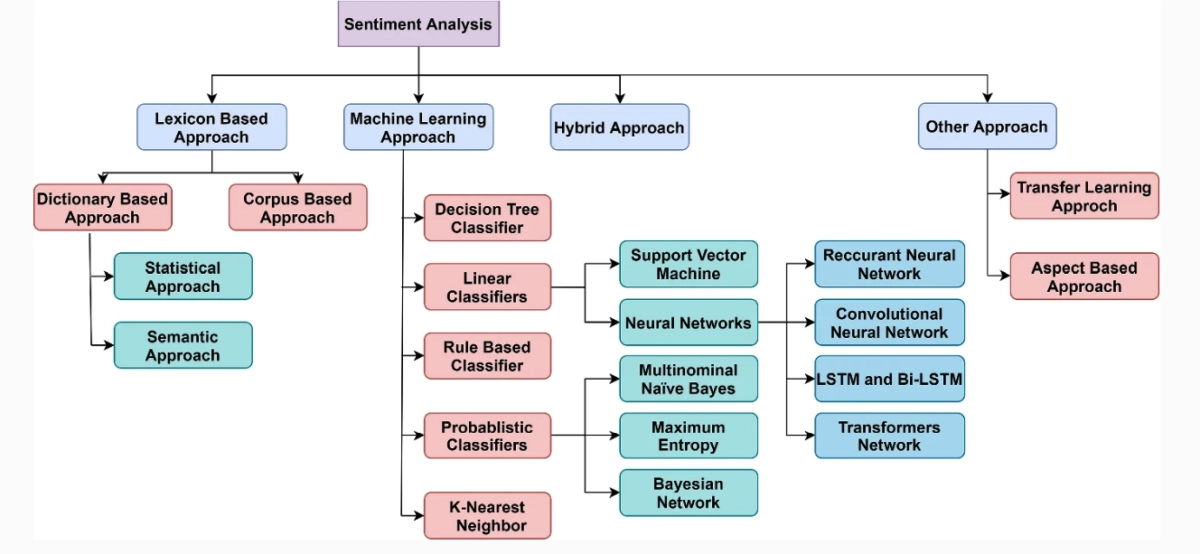
Source: Artificial Intelligence Review2
1. Lexicon-based methods
Lexicon-based, also known as knowledge-based approaches, are pre-developed manually and refer to analyzing semantic and syntactic (i.e., patterns in grammatical syntax) patterns. While the former refers to generating a dictionary by tagging words, the latter involves the consideration of syntactic patterns.
1.1. Corpus-based approach
This method relies on analyzing semantic and syntactic patterns in large text datasets to determine the sentiment of sentences, starting with predefined sentiment terms and expanding by recognizing patterns in a substantial corpus.
Statistical approach
This technique identifies the sentiment orientation of words based on their frequency and co-occurrence patterns within a dataset, such as detecting manipulation in online reviews through randomness tests or using LSA to find semantic links between documents and terms.
Semantic approach
This method calculates the similarity scores between words for sentiment analysis, often employing resources like WordNet to identify synonyms and antonyms, building lexicons to describe the sentiment orientation of various word types.
1.2. Dictionary-based method
This approach uses a manually curated list of sentiment words, which is expanded by finding synonyms and antonyms from lexical resources like thesaurus or WordNet, and is effective for smaller dictionaries but may struggle with domain-specific sentiment variations.
The sentiment score of a text is determined by the following:
- Give each token a separate score based on the emotional tone
- Calculate the overall polarity of the sentence
- Aggregate overall polarity scores of all sentences in the text.
Pros of Lexicon-based methods
- Lexicon-based sentiment analysis methods are easily accessible as many publicly available resources exist.3
- They are less expensive because they do not require implementing advanced sentiment analysis algorithms.
- There is no need for training data, especially if companies use a dictionary-based approach, as the tags are determined manually, and there is quick access to the meaning of the words.
Cons of Lexicon-based methods
- Lexicon-based sentiment analysis methods usually do not identify sarcasm, negation, grammar mistakes, misspellings, or irony. Thus, it may not be suitable for analyzing data gathered from social media platforms.
- As the whole classification is based on tags and rules, companies should have sufficient data to create a reliable dictionary.
- They are very strict and domain-dependent in that a word is labeled as the same no matter the context. For instance, the term “amazing” can be either positive or negative, depending on the context.
- They are prone to human bias. For instance, if the people preparing the dictionary don’t have sufficient domain knowledge, the method won’t yield accurate results.
- As the labeling is handled manually, data preparation can be time-consuming.
Feel free to check our article on the top 5 sentiment analysis challenges and solutions.
2. Automated/machine learning methods
Automated sentiment analysis methods include ML algorithms that categorize sentiment based on statistical models. The sentences must be transformed into vector space to implement machine learning algorithms. Then the models can be trained to predict the sentiment of a sentence.
2.1. Naive Bayes (NB)
It is a supervised, probabilistic classification approach based on Bayes’ Theorem and is used for feature extraction. This approach assumes that each token or feature is independent of the other so it can handle any misspellings or grammar mistakes.
This probabilistic classifier applies Bayes’ theorem to estimate the likelihood of data points belonging to different categories, typically assuming feature independence. It works well with smaller datasets and is often enhanced through models like the one improved.
2.2. Support vector machine (SVM)
SVM identifies optimal decision boundaries or hyperplanes to separate different classes in the data. It’s widely used in sentiment analysis for its effectiveness in classifying and evaluating sentiment across various datasets.
It is a non-probabilistic classification technique that determines the best hyperplane between different vectors, allowing for strict boundaries between categories using maximized margin distances.
Figure 2. Visualization of how a support vector machine works
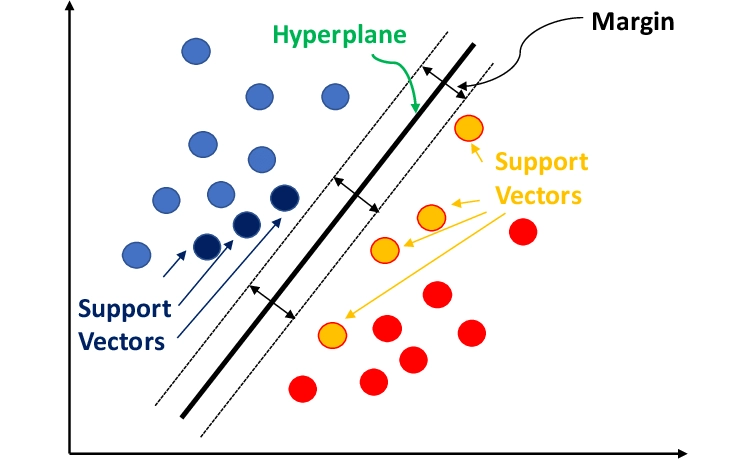
Source: Identification of flow regime in a bubble column reactor with a combination of optical probe data and machine learning technique.4
2.3. Logistic regression (LR)
This technique uses a weighted sum of input features to classify data into binary categories. Logistic regression is known for its application in probabilistic models, evaluating the odds ratios of different predictors, and is frequently used for sentiment analysis with a focus on binary outcomes.
2.4. Decision tree (DT)
DT classifiers use a tree-like model of decisions and their possible consequences to categorize sentiment. This method recursively splits data based on feature values, and when combined with techniques like Random Forest, it reduces overfitting and improves accuracy.
2.5. Maximum entropy (ME)
ME classifiers leverage entropy to model uncertainty in feature labeling. By encoding features into vectors and computing weights, ME is used to enhance sentiment analysis by managing unpredictability in data, providing improvements over models that require extensive training data.
2.6. K-Nearest neighbors (KNN)
KNN classifies data based on the majority sentiment of its nearest neighbors. Though less common in sentiment analysis, KNN can be effective when tuned properly, leveraging proximity in feature space to determine sentiment scores.
2.7. Semi-supervised learning
This approach integrates both labeled and unlabeled data to improve sentiment analysis models, especially when labeled data is scarce. It leverages the vast availability of unlabeled data to enhance the accuracy of sentiment classification.
2.8. Word Embedding (word2vec)
This method takes into account the common context in which words are used. The vectors are learned in a manner similar to neural networks, making word embedding a deep learning technique.
First, the number of dimensions is determined, and each word’s position of vector values is represented in the space. While the words used frequently are closer to each other, the words rarely used together have a long distance between them. Word embedding models have the potential to provide state-of-the-art results, yet due to their resource-demanding mechanism, they are more challenging and expensive than the other methods.
Pros of machine learning methods
Machine learning algorithms:
- Can be trained to detect sarcasm, irony, or negation in sentiment analysis. This can ease social media sentiment analysis.
- Learn the affective valence of the words, so they do not require a pre-determined dataset.
- Are faster than traditional sentiment analysis methods.
- Provide more accurate results.
Cons of machine learning methods
- Companies need a large or high-quality small dataset to have accurate classifications
- Noise (e.g., emojis, slang, or punctuation marks) can reduce accuracy
- Costs are higher compared to traditional, rule-based methods.
Figure 3. A comparison of automated and lexicon-based sentiment analysis methods
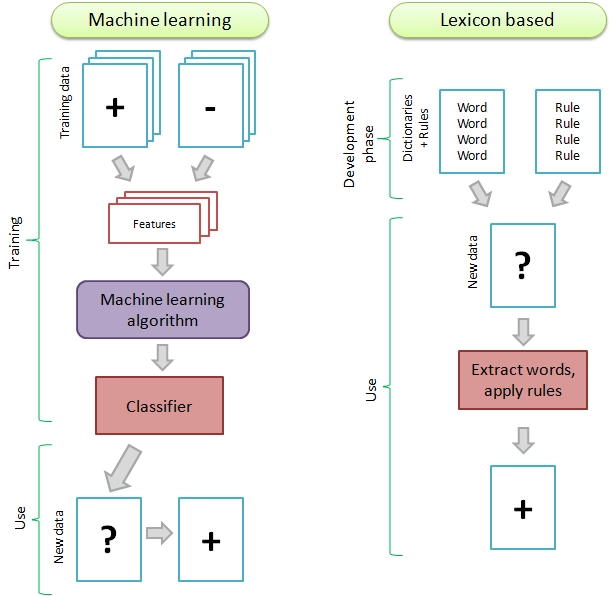
Source: Annual Review of Applied Linguistics5
Check our comprehensive article to learn more about crowdsourcing sentiment analysis and how it differentiates from traditional or automated methods.
3. Hybrid approaches
Both lexicon-based and automated methods have advantages and disadvantages. Thus, companies can implement hybrid methods that include automated and lexicon-based methods so that different approaches can compensate for each other’s flaws. The combination can either be parallel or at different stages of the analysis.
Figure 4. An example of hybrid sentiment classification
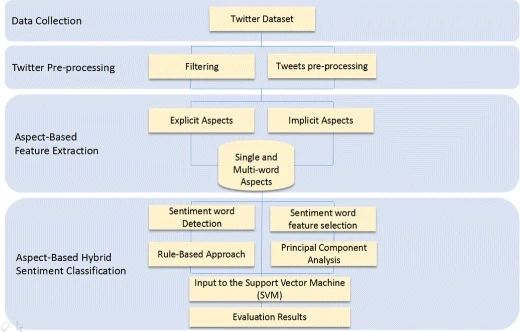
Source: Hybrid sentiment classification on twitter aspect-based sentiment analysis.6
4. Other approaches
4.1. Aspect-based sentiment analysis (ABSA)
Aspect-based sentiment analysis (ABSA) involves three crucial phases: aspect detection, sentiment categorization, and aggregation, where aspects are identified using machine learning and NLP techniques to determine sentiment polarity and aggregate the results for comprehensive analysis.
4.2. Transfer learning
Transfer learning leverages a pre-trained model’s knowledge to adapt to a new task or domain with minimal additional training, enhancing accuracy and efficiency by reusing learned features from one model to another, as seen in techniques like CNN-based transfer learning and BERT-based models.
Check our data-driven list of sentiment analysis services to find out which option satisfies your company’s needs.
Evaluation metrics of sentiment analysis methods
To measure how well a sentiment analysis method works, we use several evaluation metrics. These metrics help us understand the strengths and weaknesses of a model. The most common ones are accuracy, precision, recall, and F1-score. Some additional metrics are also used for more detailed evaluation.
Key Terms
Before going into the metrics, here are a few basic terms:
- True positive (TP): The model correctly predicts a positive sentiment.
- False positive (FP): The model wrongly predicts a negative sentiment as positive.
- False negative (FN): The model misses a positive sentiment and predicts it as negative.
- True negative (TN): The model correctly predicts a negative sentiment.
Some common evaluation metrics of sentiment analysis methods are:7
| Metric | What It Measures | Explanation |
|---|---|---|
| Accuracy | Overall correctness | The percentage of correct predictions (both positive and negative) out of all predictions. |
| Precision | Correct positive predictions | Out of all predicted positive sentiments, how many are actually positive. |
| Recall (Sensitivity) | Found positives | Out of all actual positive sentiments, how many were correctly predicted. |
| F1-score | Balance between precision and recall | The average of precision and recall. Useful when data is unbalanced. |
| Specificity | Correct negative predictions | Measures how well the model identifies negative sentiments. |
| Mean Square Error (MSE) | Prediction error | Shows how far predicted values are from actual values. Lower is better. |
| Mean Absolute Error (MAE) | Average prediction error | The average of how much predictions differ from actual values. |
| Ranking Loss | Order of predictions | Measures how far the ranking of predicted classes is from the true order. |
| Area Under Curve (AUC) | Overall model performance | A higher AUC means better classification. It shows how well the model separates positive and negative sentiments. |
Sentiment analysis levels
Sentiment analysis can be performed at different levels of text detail, depending on the use case. Each level has its strengths and limitations. Here’s a simple breakdown:8
1. Document-level sentiment analysis
This method looks at the overall sentiment of an entire document. For example, it can classify a full product review or blog post as either positive or negative.
- Use case: Sorting movie reviews as “positive” or “negative.”
- Challenge: It may miss mixed feelings. For instance, a long review might praise one feature but criticize another, and this nuance could be lost.
2. Sentence-level sentiment analysis
This approach focuses on individual sentences and their tone. It’s useful for short texts.
- Use case: Analyzing tweets or news headlines for public sentiment.
- Challenge: Sarcasm and hidden emotions are often hard to detect in brief or informal sentences.
3. Aspect-level (or feature-level) sentiment analysis
This level digs deeper. It identifies opinions about specific parts (aspects) of a product or service.
- Use case: In a review like “The screen is great, but the battery drains fast,” the system can tag “screen” as positive and “battery” as negative.
- Challenge: It’s hard to detect aspects when users use vague language or mention several features in one sentence.
- Strength: Helps businesses understand what people like or dislike about each feature, not just the product as a whole.
4. Phrase-level sentiment analysis
Here, the focus is even more detailed—on phrases and word combinations.
- Use case: A phrase like “not very good” is recognized as negative, even though the word “good” is usually positive.
- Challenge: It needs to understand modifiers (like “not”) and the way words work together.
FAQs
Why is sentiment analysis important?
Sentiment analysis is crucial for understanding and interpreting the emotional tone behind textual data across various domains. By utilizing sentiment analysis tools, methods and algorithms, organizations can perform sentiment analysis to classify sentiments as positive, negative, or neutral, thereby gaining insights from customer feedback, social media posts, and online reviews.
Through aspect-based sentiment analysis, specific aspects of products or services can be evaluated, allowing for targeted improvements. Advanced techniques, such as machine learning and neural networks, enhance the accuracy of sentiment analysis models by analyzing sentiment scores and utilizing natural language processing (NLP) tools.
This enables fine-grained sentiment analysis that is essential for market research, opinion mining, and social media monitoring, ultimately aiding businesses in understanding customer sentiment and making data-driven decisions.
How does sentiment analysis work?
Sentiment analysis, also known as opinion mining, uses natural language processing (NLP) and machine learning techniques to automatically determine the emotional tone behind textual data from online sources. This process involves various sentiment analysis methods and algorithms tailored to the data volume and desired accuracy.
Types of sentiment analysis algorithms
Sentiment analysis algorithms fall into three main categories:
1. Rule-based approaches
Rule-based systems use manually crafted rules to analyze text. These rules leverage various NLP techniques from computational linguistics, such as:
Stemming,
Tokenization,
Part-of-Speech Tagging, and Parsing,
Lexicons of Positive and Negative Words
2. Automatic approaches
Automatic systems rely on machine learning algorithms to learn from sentiment analysis datasets without predefined rules. These systems model sentiment classification as a text classification problem, using steps such as:
Training Process
Convert text into feature vectors.
Use feature vectors and sentiment tags (positive, negative, neutral) to train a machine learning model.
Prediction Process
Transform new text into feature vectors.
Use the trained model to predict sentiment tags.
Feature Extraction Techniques:
Bag-of-Words or Bag-of-Ngrams
Word Embeddings (Word Vectors)
3. Hybrid approaches
Hybrid systems combine rule-based and automatic methods to perform accurate sentiment analysis. These systems leverage the strengths of both approaches, providing a robust sentiment analysis solution that often yields more accurate results.
Further Reading
- Top 4 Real-Life Examples of Sentiment Analysis
- Top 5 Open Source Sentiment Analysis Tools
- Challenges and Methods for Multilingual Sentiment Analysis
Feel free to contact us if you have questions regarding sentiment analysis:
External Links
- 1. Customer experience is everything: PwC .
- 2. Wankhade, M., Rao, A. C. S., & Kulkarni, C. (2022). A survey on sentiment analysis methods, applications, and challenges. Artificial Intelligence Review, 55(7), 5731-5780.
- 3. e.g., SentiWordNet(Sebastiani, F., & Esuli, A. (2006, May). Sentiwordnet: A publicly available lexical resource for opinion mining. In Proceedings of the 5th international conference on language resources and evaluation (pp. 417-422). European Language Resources Association (ELRA) Genoa, Italy.)
- 4. Manjrekar, O. N., & Dudukovic, M. P. (2019). Identification of flow regime in a bubble column reactor with a combination of optical probe data and machine learning technique. Chemical Engineering Science: X, 2, 100023.
- 5. Taboada, M. (2016). Sentiment analysis: An overview from linguistics. Annual Review of Linguistics, 2(1), 325-347.
- 6. Zainuddin, N., Selamat, A., & Ibrahim, R. (2018). Hybrid sentiment classification on twitter aspect-based sentiment analysis. Applied Intelligence, 48, 1218-1232.
- 7. Mao, Y., Liu, Q., & Zhang, Y. (2024). Sentiment analysis methods, applications, and challenges: A systematic literature review. Journal of King Saud University-Computer and Information Sciences, 102048.
- 8. https://www.irjet.net/archives/V12/i4/IRJET-V12I4134.pdf



Comments
Your email address will not be published. All fields are required.