Words are the most powerful tools to express our thoughts, opinions, intentions, desires, or preferences. However, the complexity of human languages constitutes a challenge for AI methods that work with natural languages, such as sentiment analysis.
Explore sentiment analysis challenges and ways to improve sentiment analysis accuracy:
Top 7 challenges in sentiment analysis
1. Context-dependent errors
Sarcasm
People tend to use sarcasm as a way of expressing their negative sentiment, but the words used can be positive (e.g., “I am so glad that the product arrived in one piece!”). In such cases, sentiment analysis tools can classify the feedback as positive, which in reality is negative.
Solution: Determine the boundaries of sarcasm in the training dataset. For instance, researchers used a multi-head self-attention-based neural network architecture to identify terms that include sarcasm.1 It highlights the parts that have a sarcastic tone, then connects these parts to each other to obtain an overall score.
Polarity
Although the emotional tone in some sentences can be very apparent and robust (e.g., “It was a terrible experience.”), the others are not easily classified as positive, negative, or neutral (e.g., “The service quality is not mentionable.”). So, the polarity of the statement cannot always be easily inferred by the algorithms.
Solution: Give polarity scores to the words in the training datasetso that the algorithm can classify the difference between statements such as “very good” and “slightly good.”
Polysemy
When words have more than one meaning (e.g., the head of the sales team vs. wearing an earbud hurts the head), then it becomes more challenging for the algorithm to differentiate what the intended meaning is. Thus, as the word is not evaluated in its context, the results of the analysis can be inaccurate.
Solution: Incorporate domain knowledge during text annotation and model training phases. It can help your sentiment analysis algorithms to differentiate between words that have different meanings in different contexts.
2. Negation detection
Just because a sentence contains negation (e.g., no, not, -non, -less, -dis), it does not mean that the overall sentiment of the statement is negative. Current negation detection methods are not sufficient to classify the sentiment correctly.2 For instance, “It was not unpleasant” is a statement with negation and can be classified by the algorithm as negative, but it conveys a positive meaning.
Solution: Train your algorithm with large datasets, including all possible negation words. A combination of term-counting methods that regard contextual valence shifters and machine learning methods is found to be effective in identifying negation signals more accurately.3
3. Multilingual data
Although English is the common language used worldwide, as companies grow, they engage with customers globally. This results in customers using different languages while providing feedback. However, the sentiment analysis tools are primarily trained to categorize the words in one language, and some sentiments may get lost in translation. This causes a significant problem, especially while conducting sentiment analysis on non-English reviews or feedback.
Solution: Design systems that can learn from multilingual content and can make predictions regardless of the language. For instance, you can use a code-switching approach that includes parallel encoders at a word and implements models such as deep neural networks.4
4. Emojis
Figure 2. The valence and arousal rates for the most used emojis
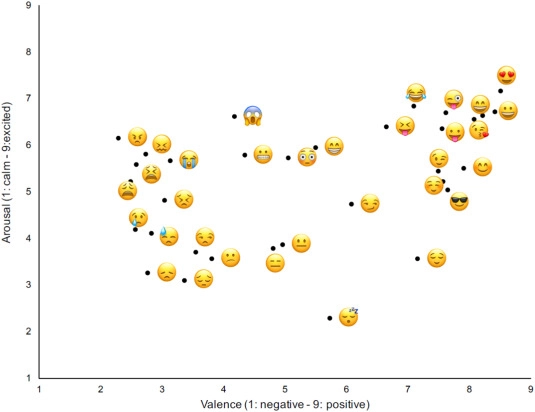
Source: ScienceDirect5
Emojis have become a part of daily life and are more effective in expressing one’s sentiment compared to words.6 However, as the sentiment analysis tools depend on written texts, emojis cannot be classified accurately and thus are removed from many analyses. In turn, one ends up with a noncomprehensive analysis.
Solution: Determining the emoji tags and implementing them into your sentiment analysis algorithm can improve the accuracy of your analysis.7
5. Potential biases in model training
Although AI algorithms are powerful tools to make accurate predictions, they are trained by humans. This means that they inevitably reflect human biases in the training dataset in their results. For instance, if the algorithm is trained to label the sentence “I am a sensitive person” as negative and label the sentence “I can be very ambitionist” as positive, the results can be biased towards some people with emotional tendencies and may distinguish overly ambitious people.
Solution: Minimize bias in AI systems by conducting debiasing methods. For instance, you can detect the words in your dataset that might involve human bias and develop a dictionary for these words.8 This way, you can tag them and then compare the overall sentiment in the text with and without these tagged words.
6. Subjective statements and qualitative data
Subjective statements and qualitative data can be challenging to quantify. Positive emotions and negative emotions are often expressed in ways that are not easily captured by simple sentiment classification.
Solution: Employ machine learning algorithms and deep learning models to process and analyze complex, subjective sentences. Enhancing sentiment analysis models with an advanced natural language toolkit can help in understanding nuanced expressions.
7. Positive and negative words ambiguity
Some positive words and negative words may have ambiguous meanings depending on the context, leading to incorrect sentiment scoring.
Solution: Use context-aware sentiment analysis techniques to disambiguate these words. Advanced sentiment analysis algorithms can be trained to understand the context in which these words are used.
Improving sentiment analysis accuracy
1. Enhanced algorithms
Employ deep learning techniques and neural networks for more nuanced sentiment detection. Sentiment analysis algorithms should be continuously updated to reflect changes in language and sentiment expression.
2. Contextual analysis
Incorporate context-aware methods to better understand and interpret subjective statements and positive or negative sentiment. Techniques such as part of speech tagging and contextual sentiment analysis can enhance model performance.
3. Human-in-the-loop
Combining automated sentiment analysis with human expertise can help in fine-tuning sentiment analysis models and addressing edge cases that algorithms might miss.
4. Customized solutions
Develop sentiment analysis solutions that cater to specific needs, such as aspect-based sentiment analysis for detailed insights or intent-based analysis for understanding underlying motivations.
5. Comprehensive training data
Using diverse and comprehensive training data that includes a variety of textual data, such as social media comments, video data, and customer feedback, can enhance the robustness of sentiment analysis models.
6. Comprehensive evaluation
Regularly evaluate the performance of sentiment analysis models using metrics like sentiment score and model performance. Adjust algorithms and training methods based on feedback and results to ensure ongoing improvement.
7. Regular updates
Continuously updating sentiment analysis models with new data and feedback can help in maintaining high accuracy and adapting to changing language trends.
Why is it challenging to conduct sentiment analysis?
Consider the following example:
Figure 1. Consumer feedback on a product
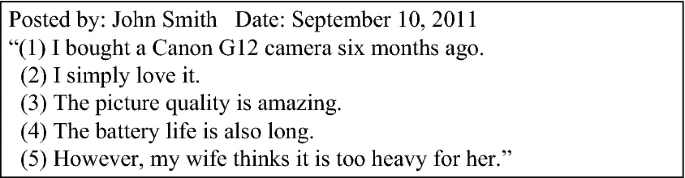
Source: A survey of sentiment analysis in social media9
The consumer states in his review that he is content with the product, and his words can be classified as positive (e.g., “love,” “amazing,” and “long battery life”). However, in the fifth sentence, he says that his wife does not have similar thoughts. Instead, her sentiment regarding the product is negative (e.g., “too heavy”). So, how would the algorithm classify this review? As positive, negative, or neutral?
Sentiment analysis helps machines understand how people feel when they write. It looks at the emotional clues in language instead of just the words themselves. However, identifying words based on emotional tone and giving a score for each sentence as either positive, negative, or neutral can be tricky . In instances similar to presented above, the algorithm may provide inaccurate results, which decreases its value.
FAQs
Why do companies depend on sentiment analysis?
Companies rely on sentiment analysis to gain a deeper understanding of customer sentiment and make more informed decisions. This leads to higher returns on investment through more effective marketing strategies and improved customer experiences. Insights derived from sentiment analysis tools and sentiment analysis models help enhance product features, pricing, store locations, and employee satisfaction.
What are some limitations of sentiment analysis?
Sentiment analysis faces several limitations, known as sentiment analysis challenges. One significant challenge is achieving accurate sentiment analysis, as sentiment analysis tools and sentiment analysis models can struggle with the nuances of human language. Sentiment analysis algorithms may misinterpret sarcasm, irony, and context, leading to incorrect sentiment classification of textual data.
Performing sentiment analysis often involves dealing with positive and negative words, but the presence of negation words can complicate the sentiment analysis process. Additionally, sentiment analysis accuracy can be affected by the quality of training data used in machine learning.
Aspect-based sentiment analysis, which focuses on specific elements of text data, can also encounter difficulties in detecting sentiment accurately. Multilingual data presents another sentiment analysis challenge, as sentiment analysis software must handle multiple languages and cultural contexts.
Overall, while sentiment analysis provides valuable insights, mastering sentiment analysis requires addressing these common sentiment analysis challenges to improve the reliability of sentiment analysis results.
To learn more about sentiment analysis, read our other articles:
- Top 5 Benefits of Sentiment Analysis for Businesses
- How To Benefit From Social Media Sentiment Analysis?
- Top 4 Use Cases of Sentiment Analysis in Marketing
If you think your company can benefit from sentiment analysis, check our data-driven list of sentiment analysis services.
External Links
- 1. Social Media Scraping Benchmark: Tools & Case Studies in 2025. AIMultiple
- 2. Dadvar, M., Hauff, C., & De Jong, F. M. (2011, February). Scope of negation detection in sentiment analysis. In 11th Dutch-Belgian Information Retrieval Workshop, DIR 2011 (pp. 16-20). University of Amsterdam.
- 3. Dadvar, M., Hauff, C., & De Jong, F. M. (2011, February). Scope of negation detection in sentiment analysis. In 11th Dutch-Belgian Information Retrieval Workshop, DIR 2011 (pp. 16-20). University of Amsterdam.
- 4. Agüero-Torales, M. M., Salas, J. I. A., & López-Herrera, A. G. (2021). Deep learning and multilingual sentiment analysis on social media data: An overview. Applied Soft Computing, 107, 107373.
- 5. Jaeger, S. R., Roigard, C. M., Jin, D., Vidal, L., & Ares, G. (2019). Valence, arousal and sentiment meanings of 33 facial emoji: Insights for the use of emoji in consumer research. Food research international, 119, 895-907.
- 6. Liu, C., Fang, F., Lin, X., Cai, T., Tan, X., Liu, J., & Lu, X. (2021). Improving sentiment analysis accuracy with emoji embedding. Journal of Safety Science and Resilience, 2(4), 246-252..
- 7. Liu, C., Fang, F., Lin, X., Cai, T., Tan, X., Liu, J., & Lu, X. (2021). Improving sentiment analysis accuracy with emoji embedding. Journal of Safety Science and Resilience, 2(4), 246-252..
- 8. Think | IBM.
- 9. Yue, L., Chen, W., Li, X., Zuo, W., & Yin, M. (2019). A survey of sentiment analysis in social media. Knowledge and Information Systems, 60, 617-663.



![Top 4 Methods of Sentiment Analysis in Retail Industry ['25]](https://research.aimultiple.com/wp-content/uploads/2022/08/Methods-of-Sentiment-Analysis-IN-Retail-Industry-1-190x107.png.webp)
Comments
Your email address will not be published. All fields are required.