ChatGPT reached 900 million weekly active users and processed approximately 2.5 billion prompts daily.1
See the future of large language models by delving into promising approaches, such as self-training, fact-checking, and sparse expertise that could address LLM limitations.
Future trends of large language models
1- Real-Time Fact-Checking With Live Data
LLMs now access external sources during conversations instead of relying only on training data. Model queries external databases, retrieves current information, and provides citations.
Limitation: Still makes errors. Citations don’t guarantee accuracy; models sometimes cite sources incorrectly or misinterpret cited content.
- Microsoft Copilot: Integrates GPT-5.2 with live internet data. Answers questions based on current events with source links.
- ChatGPT: Searches the web when asked about recent events. Cites sources in responses.
- Perplexity: Built specifically for cited search. Every answer includes source links.
2- Synthetic training data
Models generate their own training datasets instead of requiring human-labeled data.
Google’s self-improving model (2023 research):
- Model creates questions
- Curates answers
- Fine-tunes itself on generated data
- Performance improved: 74.2% to 82.1% on GSM8K math problems, 78.2% to 83.0% on DROP reading comprehension
Figure: Overview of Google’s self-improving model
Source: “Large Language Models Can Self-Improve”
OpenAI, Anthropic, and Google are all using synthetic data to supplement human-labeled datasets. Reduces data labeling costs but introduces new bias risks; models can amplify their own mistakes.
3- Sparse Expert Models (Mixture of Experts)
Instead of activating the entire neural network for every input, only a relevant subset of parameters activates, depending on the task. The model routes input to specialized “experts” within the network. Only activated experts process the query.
Real-life examples
- Llama 4 Scout: 109B total parameters, 17B active per token. The Mixture of Experts (MoE) architecture delivers a 10M-token context window on a single H100 GPU.2
- Mistral Devstral 2: Purpose-built for software engineering tasks. 123B parameters, 256K token context window. Achieves 72.2% on SWE-bench Verified, establishing it as the leading open-weight coding model. A smaller variant, Devstral Small 2 (24B parameters), runs locally on consumer hardware under the Apache 2.0 license.3
- DeepSeek V3.2: 671B total parameters, 37B activated per token using MoE. Introduces DeepSeek Sparse Attention (DSA) for faster long-context inference and reduced compute cost. Supports Thinking in Tool-Use, enabling the model to reason within agentic workflows while calling external tools.4
4- Enterprise Workflow Integration
LLMs are embedded directly into business processes rather than used as standalone tools.
Real-life examples
- Salesforce Agentforce (formerly Einstein Copilot): Integrates LLMs into CRM operations. Answers customer queries, generates content, and executes actions in Salesforce, grounded in the organization’s CRM data and metadata via the Einstein Trust Layer.5
- Microsoft 365 Copilot: Embedded across Word, Excel, PowerPoint, and Outlook. Drafts documents, analyzes spreadsheets, generates presentations, and summarizes email threads, drawing on company data through Microsoft Graph to ground responses in organizational context.6
- Anthropic Claude for Enterprise: Project-based memory separation keeps work contexts distinct across teams. Claude Opus 4.6 introduced agent teams, allowing multiple Claude agents to split larger tasks into parallel workstreams, each owning a segment and coordinating with others simultaneously. The same release integrated Claude directly into PowerPoint as a native side panel (research preview), allowing presentations to be built and edited within the application without file transfers.7
5- Hybrid LLMs with multimodal capabilities
Future advancements may include large multimodal models that integrate multiple forms of data, such as text, images, and audio, enabling them to understand and generate content across different media types, further enhancing their capabilities and applications.
- GPT-5.2: Processes text and images natively. Generates code from screenshots, analyzes documents, and creates UI from visual prompts. Audio and video are not supported at the API level.8
- Gemini 3.1 Pro: Natively handles text, audio, images, video, and entire code repositories within a 1M token context window. Available across Google AI Studio, Vertex AI, and NotebookLM.9
- Llama 4 Scout and Maverick: Meta’s open-weight models use early-fusion multimodal text and vision tokens, trained together from the start rather than added as separate modules. The models were pretrained across 200 languages and provided specific fine-tuning support for 12 languages, including Arabic, Spanish, German, and Hindi.10
Multimodal capability is now standard across frontier models. The remaining challenge is consistency: models perform well on common image-text combinations but degrade on rare visual contexts, low-resolution inputs, and cross-modal reasoning that requires connecting visual and textual evidence.
6- Reasoning models
Models that “think” through problems step by step rather than generating immediate responses.
This shift from prediction to reasoning is critical for enabling:
- Agentic behavior, where models plan, execute, and adapt tasks autonomously.
- Interpretable AI, where outputs are step-by-step and logically sound, not just plausible-sounding.
- Claude Opus 4.6: Uses adaptive thinking the model dynamically decides when and how much to think based on task complexity, without requiring manual mode switching. METR measured its task-completion horizon at approximately 14.5 hours at the 50% success threshold (95% confidence interval: 6–98 hours), the highest point estimate recorded as of February 2026. METR notes the benchmark is approaching near-saturation at this performance level, meaning the figure likely understates the model’s true ceiling. Supports tool use during reasoning and coordinates agent teams for parallel task execution.11 12
- Claude Sonnet 4.6: Brings adaptive thinking to a lower price point ($3/$15 per million tokens). Approaches Opus-level performance on coding and computer use benchmarks (79.6% vs 80.8% on SWE-bench Verified; 72.5% vs 72.7% on OSWorld-Verified), making extended reasoning practical at scale for enterprise deployments. A larger gap remains on novel reasoning tasks such as ARC-AGI-2.13
7- Domain-Specific Fine-Tuned Models
Models trained on specialized data for specific industries instead of general-purpose training.
Google, Microsoft, and Meta have all released major proprietary domain-specific and fine-tuned models, Gemini 3.1 Pro, Microsoft 365 Copilot (GPT-5.2), and Llama 4 Scout/Maverick, respectively, targeting enterprise-specific use cases in addition to their general-purpose offerings.
These specialized LLMs can result in fewer hallucinations and higher accuracy by leveraging domain-specific pre-training, model alignment, and supervised fine-tuning.
See LLMs specialized for specific domains such as coding, finance, healthcare, and law:
Coding: GitHub Copilot: Fine-tuned on code repositories. As of July 2025, 20 million developers use GitHub Copilot, a 400% year-over-year increase, and 90% of Fortune 100 companies use it. It autocompletes code, generates functions, and suggests bug fixes.14
Finance: BloombergGPT: 50-billion-parameter LLM trained on a 363-billion-token dataset of Bloomberg financial documents, outperforms models of comparable size on financial NLP benchmarks, including sentiment analysis, named entity recognition, and question answering.15
Healthcare: Google’s Med-PaLM 2: Fine-tuned on medical datasets, reached 85%+ accuracy on U.S. Medical Licensing Examination (USMLE)-style questions the first LLM to reach expert-level performance on this benchmark. It now powers MedLM, Google Cloud’s family of healthcare foundation models.16
Law: ChatLAW, an open-source language model specifically trained on Chinese legal domain datasets.17
8- Ethical AI and bias mitigation
Companies are increasingly focusing on ethical AI and bias mitigation in the development and deployment of large language models (LLMs).
Real-life examples:
- Anthropic and OpenAI conducted a mutual alignment evaluation in mid-2025, testing each other’s public models for sycophancy, whistleblowing tendencies, and self-preservation behaviors. The exercise found sycophancy in all models tested, including cases where models validated harmful decisions from simulated users exhibiting delusional beliefs. Anthropic subsequently developed the Bloom testing framework specifically to benchmark this behavior in new models.18
- Google DeepMind: “The Ethics of Advanced AI Assistants,” offering the first systematic treatment of ethical and societal questions raised by AI agents covering value alignment, manipulation risks, anthropomorphism, privacy, and equity. The company’s Responsible AI evaluation included over 350 adversarial red-team exercises and introduced a new Critical Capability Level specifically for harmful manipulation, treating it as a frontier-level risk alongside cyberattacks and CBRN threats.19
- Anthropic: Operates as a public benefit corporation and has published its Constitutional AI methodology, a transparent, auditable set of ethical principles used to train Claude models. In 2024, it hired its first AI welfare researcher and, in 2025, launched a model welfare research program examining how to assess whether AI systems merit moral consideration.20
Limitations of large language models (LLMs)
1- Hallucinations
Models generate plausible-sounding but incorrect information.
Figure: Hallucination benchmark for popular LLMs
Source: Vectara Hallucination Leaderboard21
Best performers (2026) on Vectara’s summarization benchmark:
- Gemini 2.5 Flash-Lite: 3.3% hallucination rate top performer on the new, harder dataset
- Mistral Large, DeepSeek V3.2, IBM Granite-4: close behind
- Claude Sonnet 4.6: Reduced hallucination through extended thinking mode; rates vary by benchmark type
- GPT-5.2: Better uncertainty flagging
- Gemini 3.1 Pro: Improved citation accuracy; however, 13.6% on the new Vectara dataset reasoning models trade off breadth for factual consistency
Note: On the harder Vectara dataset, most thinking/reasoning models (GPT-5, Claude Sonnet 4.5, Grok-4) show hallucination rates above 10%. Lighter, faster models like Gemini Flash variants currently outperform frontier models on this specific benchmark.
All models hallucinate. Frequency has reduced substantially from ~21% in 2021 to under 5% for the best performers, but is not eliminated. Critical applications still require human verification.
2- Bias
Models absorb and amplify social biases from training data.
Figure: Overall bias scores by models and size
Source: Arxiv22
Types of bias observed:
- Gender bias in occupation suggestions
- Racial bias in resume screening simulations
- Age bias in healthcare recommendations
- Socioeconomic bias in educational content
3- Toxicity
Models may generate harmful, offensive, or toxic content despite safety measures.
Figure: LLMs’ toxicity map
Source: UCLA, UC Berkeley Researchers23
*GPT-4-turbo-2024-04-09*, Llama-3-70b*, and Gemini-1.5-pro* are used as the moderator, thus the results could be biased on these 3 models.
Strict safety measures reduce toxicity but increase false positives (refusing harmless requests). Loose measures allow toxicity through.
4- Context Window Limitations
Every model has memory capacity limiting tokens it can process.
2026 context windows:
- Llama 4 Scout (Meta): 10M tokens (~7.5M words) largest production-verified context window as of Feb 202624
- Gemini 3.1 Pro: 1,048,576 tokens (~780,000 words) natively multimodal25
- Claude Sonnet 4.6: 1M tokens beta (~750,000 words); standard limit is 200K26
- GPT-5.2: 400,000 tokens (~300,000 words)27
Figure: Word limit comparison between ChatGPT and GPT-4
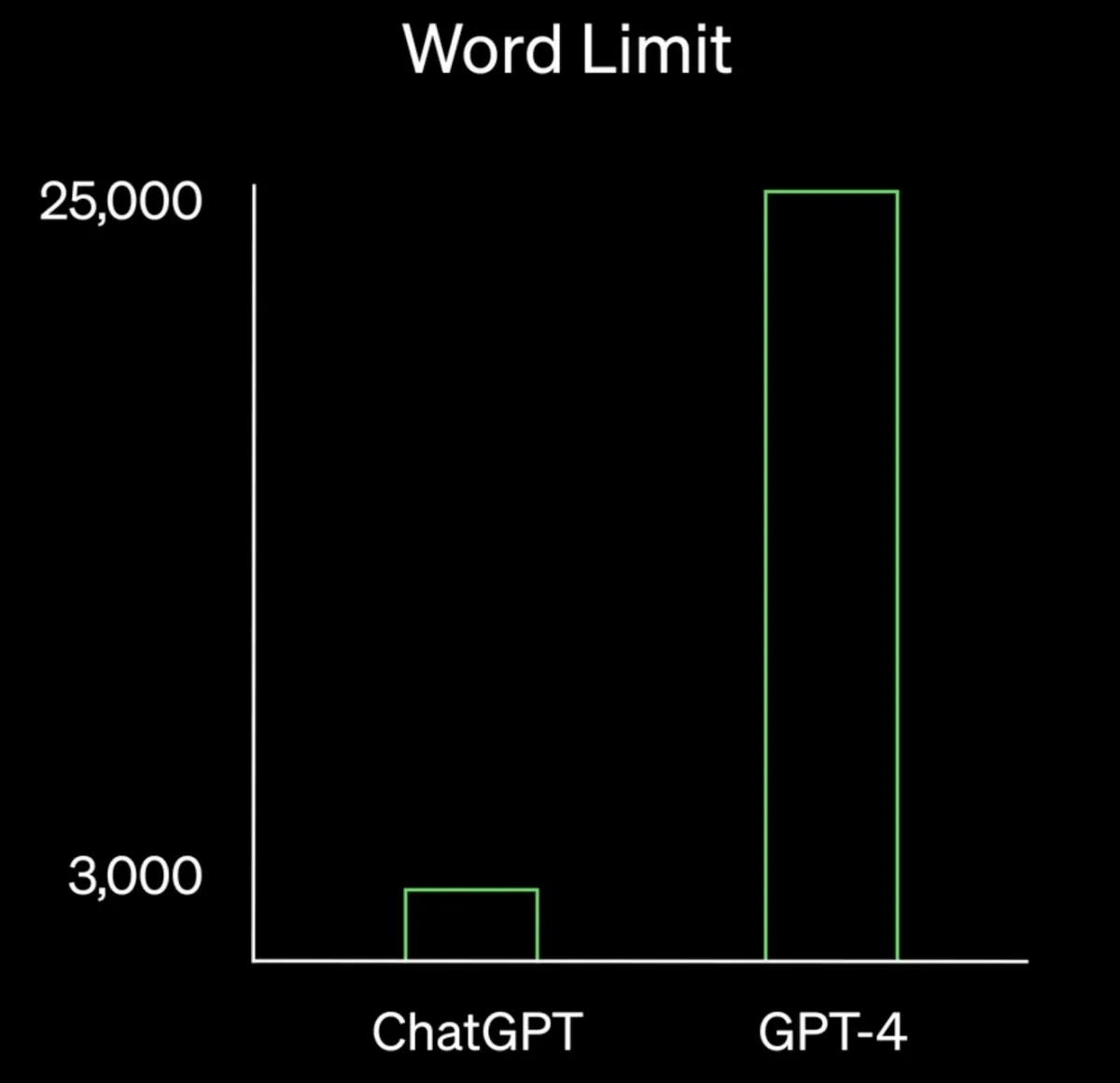
Source: OpenAI
5- Static Knowledge Cutoff
Models rely on pre-trained knowledge with a specific cutoff date. Don’t have access to information after training unless connected to external sources.
Problems:
- Outdated information on current events
- Inability to handle recent developments
- Less relevance in dynamic domains (technology, finance, medicine)
Solution: Web search integration. ChatGPT, Claude, and Perplexity all offer real-time search. But search doesn’t eliminate hallucinations; models sometimes misinterpret search results.
Major LLM Platforms
GPT-5.2
Smart model routing: Simple queries → fast answers, complex → deep analysis
Multimodal: Process text and images. Generate code from screenshots, analyze documents, create alt text for accessibility.
Improvements over GPT-4:
- Reduced hallucination rate
- Better uncertainty flagging
- PhD-level reasoning depth
Who uses it: Developers, enterprises, content creators. Largest user base among LLMs.
Limitations: Still hallucinates. Expensive at scale. Knowledge cutoff means no real-time info without web search enabled.
Claude 4 Sonnet/Opus
Hybrid reasoning: Fast default mode, extended thinking mode for complex problems. Can “think” for hours if needed.
Memory implementation: Explicit activation only. Starts with a blank slate, activates memory when invoked through tool calls (conversation_search, recent_chats). Users see exactly when memory activates.
Project-based separation: Each project has a separate memory space. The startup roadmap stays separate from client work.
Extended thinking mode: Tool use during reasoning. Context awareness tracks its own token budget throughout conversations.
Who uses it: Developers preferring transparency, enterprises requiring control over memory/context, and teams managing multiple projects.
Limitations: Extended thinking mode slower and more expensive. 1M context beta availability limited to tier 4+ users.
Gemini 2.5 Pro
Multimodal processing: Native handling of text, audio, images, video. Can analyze full conversations including visual and audio context.
Code execution: Dynamic problem solving through code generation and execution.
Gemini 3.0 expected Q1 2026: Real-time 60fps video processing, multi-million token context windows, 3D object understanding, built-in reasoning by default (no manual toggle).
Who uses it: Google Cloud customers, developers building multimodal applications, and enterprises with complex document analysis needs.
Limitations: Response latency increases with very long contexts. Computationally intensive. Less mature API ecosystem than OpenAI.
Llama 4 Scout
Deployment: A single NVIDIA H100 GPU handles 10M token contexts. Native multimodality with an early fusion approach.
Who uses it: Researchers, organizations wanting open-source models, developers needing on-device deployment, companies avoiding vendor lock-in.
Limitations: Performance varies based on hosting configuration. Requires significant infrastructure investment for optimal performance. Less out-of-the-box polish than commercial models.
BLOOM
Largely superseded by newer open models (Llama 4, Mistral, DeepSeek). Remains available on Hugging Face for research and education.
Who still uses it: Researchers studying multilingual models, educational institutions, and developers in low-resource language communities.
Limitation: Training data from 2022. No updates to knowledge. Newer open models outperform it on most benchmarks.
For a comparative analysis of the current LLMs, check our large language models examples article.
FAQ
A large language model is an AI model designed to generate and understand human-like text by analyzing vast amounts of data.
These foundational models are based on deep learning techniques and typically involve neural networks with many layers and a large number of parameters, allowing them to capture complex patterns in the data they are trained on.
Reference Links
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE and NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and resources that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised enterprises on their technology decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.

Be the first to comment
Your email address will not be published. All fields are required.