

IBM identifies the top AI adoption challenges as concerns over data bias (45%), lack of proprietary data (42%), insufficient generative AI expertise (42%), unclear business value (42%), and data privacy risks (40%).1 These obstacles can hinder AI implementation, slow innovation, and reduce the return on investment for organizations adopting AI technologies.
To overcome these challenges, explore the top 10 steps to developing AI systems.
10 steps to developing AI systems
| Step | Techniques | Strategies to Use |
|---|---|---|
| Define objectives and requirements | Goal setting, scoping, resourcing | Responsible AI principles, cloud tools, AI vendors |
| Gather data | Structured/unstructured data, synthetic | Federated learning, differential privacy, synthetic data |
| Data preparation and manipulation | Cleaning, transformation, annotation | Python tools, AutoML, human-in-the-loop, LLM-based annotation |
| Model selection and development | Algorithm choice, transfer learning | Pre-trained models (GPT, CLIP, SAM), LangChain, LlamaIndex |
| Train the model | Supervised learning, LoRA, RAG | Transfer learning, data splits, RAG, online pipelines |
| Validate and test | Metrics, bias audit | SHAP, LIME, QLoRA, adapters |
| Deployment and maintenance | Cloud deployment, monitoring | GCP, Azure, AWS Lambda, Arize AI, WhyLabs, automated retraining |
| Responsible AI and governance | Documentation, compliance frameworks | Model cards, data sheets, internal audits, EU AI Act alignment |
| LLM integration and orchestration | Tool-using agents, RAG | LangChain, Semantic Kernel, Auto-GPT, real-time grounding |
| Model evaluation | Fairness, UX testing | Synthetic edge cases, human feedback, consistency checks |
1. Defining objectives and requirements
This phase begins the AI action plan and sets the foundation for the entire AI development process.
1.1. Determine the scope
Start by defining the problem your AI system will address. Whether it’s automating customer support or analyzing unstructured data for market insights, the objective must be clear. Align your scope with responsible AI principles, such as fairness, transparency, and risk mitigation.
1.2. Resource allocation
Estimate what the AI project will need. This includes human intelligence, computing infrastructure, software development tools, and data engineering capabilities. Plan for both the development phase and ongoing maintenance. Consider whether you need internal teams, external partners, or a combination.
2. Gathering data
Training data fuels every machine learning model. Without high-quality data, even the most advanced algorithms can fail.
2.1. Understanding data types
AI systems typically process two main data types:
- Structured data: Organized in rows and columns (e.g., Excel, databases).
- Unstructured data: Text, images, video, audio, and other non-tabular formats.
2.2. Data sources
Use data from internal databases, public datasets, web scraping tools, crowdsourcing platforms, and data partners. Synthetic data generation is now a viable option in sectors with privacy constraints, such as healthcare and finance.
2.3. Data privacy enhancements
Adopt modern strategies, such as federated learning and differential privacy. These techniques protect sensitive information while still allowing the AI’s learning process to continue across decentralized datasets.
3. Data preparation and manipulation
This stage makes the collected data usable for building AI models.
3.1. Data quality and cleaning
AI models depend on accurate input. Data cleaning involves detecting and correcting errors, handling missing values, and validating data formats. This helps limit AI errors during model training.
3.2. Transforming raw data
Use statistical analysis and feature engineering to convert raw data into useful variables. AutoML platforms often automate this task using AI tools that identify predictive patterns.
3.3. Feature selection
Modern feature selection methods prioritize variables based on relevance. This reduces noise and improves the model training outcome.
3.4. Data annotation
Use large language models (LLMs)-assisted tools and human-in-the-loop systems to annotate unstructured data. This step is crucial for supervised learning tasks, such as computer vision or natural language processing.
4. Model selection and development
Choosing the right model architecture is central to developing AI effectively.
4.1. Choosing the right algorithms
Select your algorithm based on the task (classification, clustering, regression), available training data, and hardware constraints. Deep learning models remain effective for unstructured data, but transformers and foundation models now dominate tasks in vision and text. Check out deep learning applications to learn how deep learning models can be used across various dimensions.
Popular models include:
- Vision Transformers (ViTs) for image tasks
- BERT/GPT for language
- SAM for segmentation
Read large language model training to learn more.
4.2. Using pre-trained models
Pre-trained models, such as ResNet, CLIP, and GPT, can reduce the time required to create AI.
Fine-tune them with your training data for domain-specific performance. Use transfer learning or low-rank adaptation (LoRA) for resource efficiency.
4.3. Programming languages and tools
Python and R remain dominant programming languages for data science. Tools like TensorFlow, PyTorch, and JAX support advanced model training.
Use LangChain, LlamaIndex, and other orchestration frameworks for building LLM-based applications.
5. Training the model
This step is where the model learns from the data to perform its task.
5.1. The training process
Feed your training data into the AI model. During this stage, the system identifies patterns, relationships, and behaviors relevant to the task.
For large models, consider transfer learning and low-rank adaptation (LoRA) to reduce computational cost.
5.2. Continuous learning
AI systems can evolve through online learning pipelines. Use retrieval-augmented generation (RAG) to inject real-time information into model responses. This ensures the AI stays current and effective in a real-world environment.
6. Validation and testing
This step evaluates how well your AI model performs on unseen data.
6.1. Assessing model performance
Use training and validation sets to measure metrics like accuracy, recall, and F1 score. Also perform bias audits, fairness checks, explainability analysis (using SHAP or LIME), and adversarial tests to ensure the model is reliable.
Learn how to measure AI performance.
6.2. Fine-tuning
If the results are below expectations, improve the model by using additional training data or alternative algorithms. For efficiency, consider applying parameter-efficient fine-tuning (PEFT) techniques, such as LoRA or QLoRA.
7. Deployment and maintenance
Deployment integrates the AI model into existing systems, while maintenance ensures long-term viability.
7.1. Deploying the AI model
Deploy AI using tools like Google Cloud Platform, Microsoft Azure Machine Learning, or Amazon SageMaker.
Consider serverless AI and edge AI for low-latency tasks and scalable infrastructure. Model-as-a-Service (MaaS) options help deploy without managing infrastructure.
7.2. Long-term maintenance
Utilize tools such as Arize AI, Fiddler, or WhyLabs for monitoring.
Implement drift detection and set up automated retraining. Ethical considerations, transparency logs, and user feedback loops help limit AI misuse.
8. Responsible AI and governance
Incorporate governance frameworks to guide the AI development process responsibly.
- Fairness and transparency: Adopt FATE principles (Fairness, Accountability, Transparency, Ethics).
- Compliance: Align with AI regulations like the EU AI Act and U.S. Executive Orders.
- Documentation: Use model cards and data sheets to document model behavior and data sources for reproducibility.
9. LLM integration and orchestration
Large Language Models (LLMs) now power many AI applications. Tools like LangChain and Semantic Kernel help create AI agents that can interact with external tools or documents.
- Use agents like Auto-GPT for task automation.
- Adopt orchestration frameworks for scalable large language model (LLM) pipelines.
10. Model evaluation beyond accuracy
Performance metrics are no longer enough. Expand evaluation to include:
- Trustworthiness: Bias detection.
- Explainability: For high-stakes use cases.
- User experience: Essential for AI copilots and chatbots.
Deploying AI systems across various industries
Healthcare
Cancer Center.AI developed a platform on Microsoft Azure that enables physicians to digitize pathology scans and utilize AI models for analysis. This system has improved diagnostic accuracy and reduced errors in initial pilot studies.2
Robotics and security
Boston Dynamics’ Spot robot dogs have been deployed in industrial settings by companies such as GSK and AB InBev for tasks including safety inspections and efficiency enhancements.

Figure 2: Boston Dynamics’ Spot robot dog example.3
Maritime operations
The Port of Corpus Christi has implemented an AI-powered digital twin system called OPTICS to enhance real-time tracking and safety. The system utilizes machine learning to predict ship positions and supports emergency response training through the use of generative AI.
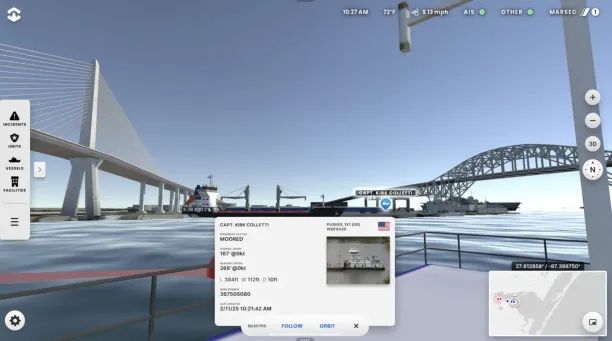
Figure 3: An example of OPTICS, showing ship information.4
Workplace productivity
Access Holdings Plc has adopted Microsoft 365 Copilot, integrating generative AI into its daily tools, resulting in significant time savings on tasks such as coding and presentation preparation.
Agriculture
KissanAI released Dhenu 1.0, the world’s first agriculture-specific large language model designed for Indian farmers.
It provides voice-based, bilingual assistance, helping farmers access information and improve practices.5
Music and entertainment
Imogen Heap partnered with the generative AI music company Jen to launch the StyleFilter program, allowing users to generate songs with the same “vibe” as licensed tracks. This initiative represents a fusion of AI and creative expression.6
External Links
- 1. AI Adoption Challenges | IBM.
- 2. How real-world businesses are transforming with AI — with 261 new stories - The Official Microsoft Blog.
- 3. Robot dogs proliferate, from production line to front line. Financial Times
- 4. How the Port of Corpus Christi Is Using AI Tech to Improve Operations - Business Insider. Business Insider
- 5. KissanAI Partners with UNDP to Launch CoPilot for Farmers. Analytics India Magazine
- 6. Imogen Heap and Jen Launch AI Voice and Music Models to Mimic Style. Billboard



Comments
Your email address will not be published. All fields are required.