Marketing teams today face growing pressure to collect data more intelligently and responsibly. As privacy regulations tighten, AI becomes more embedded in campaigns, and customer acquisition costs rise, outdated data collection methods can quickly lead to compliance issues and underperforming strategies.
Explore data collection for marketing use cases and practical strategies to help marketers collect data transparently.
What is marketing data collection?
Marketing data collection refers to gathering all data generated from marketing efforts, campaigns, and projects to assess their effectiveness and inform future strategies. This process involves capturing high-quality data from various sources, organizing it systematically, and standardizing it for usability.
Effective data collection in marketing requires the application of diverse data collection methods, a focus on data quality, and often a mix of qualitative data and quantitative data to provide a comprehensive understanding of customer behavior and market trends.
Types of marketing data collected by businesses
| Type of data | Description | Examples | Collection methods | Primary use |
|---|---|---|---|---|
| Personal data | Identifies or tracks individuals. | IP address, gender, cookies, device info. | Forms, surveys, tracking tools. | Personalization, compliance. |
| Behavioral data | Captures user actions and habits. | Purchase history, browsing behavior, mouse movements. | Web analytics, social media, transaction tracking. | Strategy optimization, journey insights. |
| Engagement data | Measures interaction with brand touchpoints. | App usage, website clicks, email opens, social activity. | Website/app tracking, email tools, social media platforms. | Campaign performance, experience improvement. |
| Attitudinal data | Reflects opinions and satisfaction. | Product preferences, satisfaction ratings, buying criteria. | Surveys, interviews, focus groups. | Customer insight, brand alignment. |
Organizing marketing data collection into categories allows businesses to adopt a data-driven approach and design a successful marketing strategy. By leveraging first-party data and combining it with insights from third-party data, companies can:
- identify patterns,
- improve data quality,
- drive informed business decisions.
These types of collected data can be categorized as follows:
Personal data
Personal data comprises information that identifies or tracks individuals. Businesses collect personal data to understand their target audience and customize offerings. Examples include social security data, gender data, IP address, browser cookies, and device data.
Personal data is often collected using online tracking tools and data collection methods like customer registration forms and surveys. Managing data privacy is critical when handling this information.
Behavioral data
Behavioral data deals with customer actions and allows businesses to analyze customer behavior and adapt their strategies. This includes:
- Buying behavior
- Purchase history
- Online navigational data (e.g., mouse movements on a website)
Behavioral data is often derived from transactional tracking, web analytics, and social media monitoring, therefore providing valuable insights into what drives consumer decisions.
Engagement data
Engagement data tracks how consumers interact with a brand across various touchpoints. It is essential in evaluating the success of marketing campaigns and refining marketing strategies. Examples of engagement data include:
- Website interactions
- Mobile app usage
- Text message responses
- Social media platform activity
- Email engagement metrics
Marketing teams mostly rely on this data to improve customer experiences and enhance effective market research.
Attitudinal data
Attitudinal data reflects customer opinions, preferences, and satisfaction. It helps businesses understand customer behavior and align with their business goals. This data includes:
- Customer satisfaction data
- Product desirability metrics
- Purchasing criteria
Attitudinal data is often collected through focus groups, surveys, and interviews, combining qualitative and quantitative data to achieve a comprehensive understanding.
Data collection for marketing use cases
Marketing data is essential for understanding target audiences and segmenting them based on preferences and behaviors to tailor campaigns and boost engagement. By leveraging behavioral and first-party data, businesses can personalize messages, recommend products, and enhance customer loyalty.
Data also refines marketing strategies through analytics and performance metrics, while insights from market research guide product development and promotional efforts.
Additionally, data-driven approaches optimize ROI by focusing resources on effective channels, supporting engaging content creation, and strengthening customer relationships through improved experiences and trust-building. Here are some of the use cases to leverage data collection for your marketing strategies:
1. Training AI models
The global market for AI-enabled marketing solutions was valued at around $8.2 billion in 2021 and is projected to grow to $23.2 billion by 2027.1 Below are some applications of AI in marketing analytics:
- Creating personalized marketing campaigns tailored to individual behavior, preferences, and demographic data.
- Measuring ROI from various marketing campaigns with enhanced precision through marketing analytics.
- Forecasting campaign results, sales trends, and market shifts using predictive algorithms trained on first-party, behavioral, and social media data.
The quality and scale of data collected—from online forms, web analytics, social media platforms, and online tracking tools—determine the reliability of these models. Data validation, data governance, and using multiple sources for primary and third-party data are essential to avoid inaccurate data and improve AI outcomes. For more, check out responsible AI best practices.
AI-trained models help sales and marketing teams optimize marketing strategies, identify patterns in customer behavior, and make informed business decisions that drive business growth.
However, companies must start collecting data with clear research objectives, structured collection methods, and a focus on data quality and privacy to maximize impact.
2. Improving the customer experience
A key reason for collecting data in marketing is to enhance and personalize the customer experience. Many companies rely on collecting data to understand how customers interact with, behave with, and purchase from the brand, improving their services:
Identify friction points in the customer journey
- Track engagement metrics like page views, click paths, time spent on pages, and cart activity.
- Use insights to improve website design, content layout, and navigation for a more intuitive user experience.
Gather and analyze customer feedback
- Collect qualitative data through surveys, reviews, and social listening.
- Identify gaps in service delivery, product performance, and customer support.
Predict and proactively meet customer needs
- Apply predictive analytics to forecast customer behavior and timing.
- For instance, remind customers to reorder products based on usage cycles or suggest complementary items at the right time.
3. Optimizing content
Content is one of the most critical assets in online marketing. This includes product information, product descriptions, and any material your customers might read while interacting with the website or brand.
Data collection can help adjust the content added to your website by aligning it with your customers’ needs. For instance, if customers like reading information about product usage, marketers can add individual product usage instructions to every product.
They can also outsource or crowdsource content creation for their website to enable multi-language content creation and content diversity.
The image below shows the steps to optimize your content:
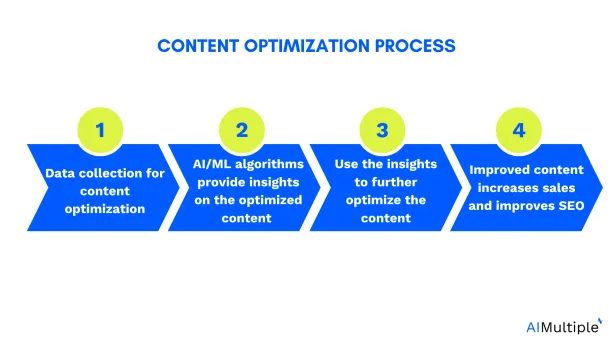
4. Target marketing
Target marketing leverages data to focus on specific audience segments that are most likely to engage with a business’s products or services. By collecting and analyzing data, companies can refine their marketing efforts to reach the right people with the right message at the right time.
AI and machine learning tools are critical in enhancing target marketing strategies. These tools can process large amounts of behavioral data, demographic data, and other customer insights to identify high-potential leads.
They can accurately predict customer preferences, purchasing intent, and likelihood of engagement to enable marketers to prioritize their efforts for maximum impact efficiently.
Moreover, these tools can filter out low-quality or irrelevant leads to save time and resources while increasing the effectiveness of marketing campaigns. Target marketing, supported with accurate data and analytics, can optimize marketing strategies and also create a more personalized and impactful customer experience.
Real-life example of how data can be leveraged for marketing campaigns:
HubSpot’s Marketing Analytics Software2 is designed to help businesses measure and optimize their marketing efforts by providing comprehensive insights into campaign performance. Here’s how it works:
- Reporting: The software offers built-in analytics and reporting tools that deliver detailed insights into each marketing asset. Users can access reports on website performance, email campaigns, blog posts, and social media activities to understand what drives engagement and conversions.
- Customizable dashboards: Users can create personalized dashboards to monitor key performance indicators (KPIs) relevant to their business objectives. These dashboards provide a centralized view of all marketing metrics, facilitating informed decision-making.
- Customer lifecycle analysis: HubSpot’s analytics tools allow businesses to track the complete customer journey, from initial interaction to final conversion. This visibility helps identify which marketing efforts contribute most to revenue generation.
- AI-powered insights: Leveraging artificial intelligence, HubSpot provides features like customer engagement scoring and AI-assisted reporting. These tools help businesses understand customer behavior and optimize marketing strategies accordingly.
Check out email marketing analytics software for more examples.
5. Dynamic pricing and personalization
Marketing data collection helps businesses adjust pricing and promotional offers in real-time, maximizing customer engagement and revenue. By leveraging behavioral data, sales figures, and first-party data collected through web analytics, online tracking, and transactional tracking, marketers can fine-tune offers based on:
- Customer segments and demographic data
- Historical buying patterns and consumer behavior
- External factors such as competitor pricing, inventory status, or time-sensitive events
Using data analytics and marketing analytics tools, sales and marketing teams can identify patterns in customer behavior, track high-quality data from multiple sources, and deploy personalized marketing campaigns aligned with the preferences of their target audience.
Real-life example: Salesforce with Google Analytics 360
Salesforce’s transition to Google Analytics 3603 aimed to better align its analytics tools with the personalized needs of its teams and customers.
To guide the move, Salesforce began by surveying internal teams to understand their expectations, challenges, and support requirements. This personalized approach helped shape the selection and implementation process.
Partnering with Cardinal Path, Salesforce restructured its digital analytics strategy focusing on simplicity and accessibility. A major reason for choosing Analytics 360 was its integration with Salesforce Marketing Cloud.
It allows for highly personalized customer experiences, such as automated, tailored email journeys and optimized cross-channel interactions.
Michael Andrew, VP of Data, AI, and Personalization, emphasized that combining Google’s advanced analytics with Salesforce’s CRM data empowers marketers to make smarter, more personalized decisions that enhance ROI and customer success.
The outcomes of this integration are:
- Quicker access to insights on campaign performance and user engagement.
- 86% of multichannel performance reporting is consolidated through built-in product integrations.
6. Cross-channel attribution
Customers interact with brands across many social media platforms, email, search engines, websites, and mobile apps. Accurate data collection for marketing is essential to understanding which channels drive real results.
Through multi-touch attribution modeling, marketers can use marketing data to:
- Determine the value of each marketing channel in the buyer journey.
- Reallocate the budget to high-performing platforms and cut spend on underperforming ones.
- Optimize customer journeys across social media data, email campaigns, search ads, and websites.
This process relies on both quantitative and qualitative data collected via online surveys, social media monitoring, online forms, and focus groups. It also involves data analysis, data visualization, and strong data governance to ensure data quality and avoid inaccurate data.
Effective attribution gives sales and marketing teams the actionable insights they need to refine their marketing strategies and make informed business decisions.
7. Competitive benchmarking
Companies must continuously monitor how they stack up against competitors to maintain a competitive edge. Marketing data collection plays a critical role here by providing reliable insights into market dynamics and consumer sentiment.
By gathering third-party data, primary data, and consumer data through effective data collection methods—such as market research, social media platforms, and business analytics—companies can:
- Benchmark brand performance against industry standards
- Detect emerging trends in customer opinions and preferences
- Reposition messaging and product offerings based on specific data points and attitudinal data
Using sales volumes, engagement metrics, and non-numerical data from focus groups or customer feedback, businesses gain invaluable insights into how their offerings resonate with the target market. This leads to more precise marketing efforts and sharper strategic planning.
8. Regulatory compliance and risk mitigation
As data privacy regulations like GDPR and CCPA become more stringent, businesses must implement effective data collection strategies prioritizing transparency, security, and data governance. Poor handling of customer data risks legal penalties and damages consumer trust.
Through proper data collection methods—such as consent-based online forms, opt-in tracking mechanisms, and validated surveys—organizations can:
- Maintain detailed records of consent and ensure data validation.
- Reduce the risk of inaccurate data or mishandled collected data.
- Build brand credibility by showing commitment to ethical data handling practices.
Complying with data regulations isn’t just about avoiding fines—it’s about enabling data-driven, trust-based marketing strategies that align with broader research objectives and long-term customer loyalty. Collecting data responsibly ensures that marketing campaigns are both effective and sustainable.
Conclusion
Marketing data collection is the backbone of modern, data-driven strategies. Businesses can unlock powerful insights that drive smarter decision-making by systematically gathering, organizing, and analyzing diverse data types—ranging from behavioral and engagement data to attitudinal and personal information.
Effective data collection enhances every aspect of the marketing function, from training AI models and improving customer experiences to enabling dynamic pricing, personalization, and competitive benchmarking.
It empowers organizations to target the right audience, optimize content, refine campaigns across channels, and ensure regulatory compliance.
As the digital landscape continues to evolve, the ability to collect high-quality data ethically and strategically will be critical for gaining a competitive edge and building lasting customer trust and loyalty.
Companies that invest in advanced data collection frameworks today are better positioned to adapt, innovate, and lead in the marketing ecosystems of tomorrow.



Comments
Your email address will not be published. All fields are required.