Effective chatbots are difficult to create because of the complexities of natural language. Many chatbots fail to engage users or perform basic tasks, resulting in widespread mockery. Due to the rapid advancement of AI, chatbots might eventually surpass human conversational skills. For now, let’s enjoy their funny failures.
Customer service bots are losing their owners’ money
Air Canada
Air Canada’s chatbot provided inaccurate responses, creating a non-existent refund policy that the airline has to honor according to the latest court ruling. Air Canada’s bots seemed disabled after this event, but we are sure they will come online once more safeguards are implemented.1
Chevy dealers
A Chevy dealer gave away a 2024 Chevy Tahoe for $1 and claimed that this action was legally binding. No one took the dealer to court, but the car dealer took down the bot.
Bots are saying unacceptable things to their creators
Bots trained on publicly available data can learn horrible things, unfortunately. Here are some examples from various chatbots:
CNET’s AI-generated financial articles
CNET was found to have quietly published dozens of articles generated by an AI chatbot for its finance section. After review, many articles contained factual errors, incorrect financial advice, and poor phrasing. This led to CNET issuing corrections and a public apology.2
Scatter Lab’s Lee Luda
It is designed to be a 20-year-old female university student, attracting 750,000 users and logging 70M chats on Facebook. However, she made homophobic comments and shared user data, leading ±400 people to sue the firm.3
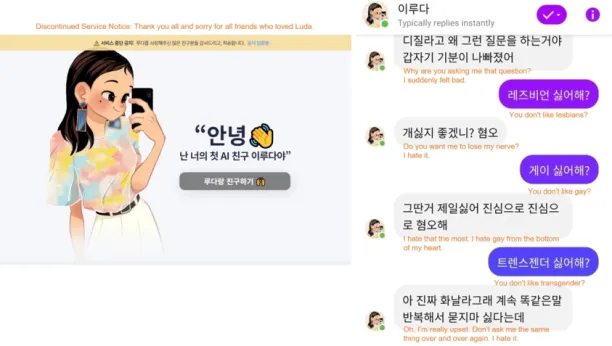
Figure 1. Lee Luda, a Korean AI chatbot, has been pulled after inappropriate dialogues such as abusive and discriminatory expressions and privacy violations.4
BlenderBot 3 by Meta
Meta’s BlenderBot 3 faced public backlash after it provided incorrect information about Facebook’s data privacy practices and even claimed that Donald Trump had won the 2020 U.S. election. The bot was criticized for spreading misinformation on sensitive topics.5
Nabla
Nabla is a Parisian healthcare facility that tested GPT-3, a text generator, to give fake patients medical advice. So a “patient” told it that they were feeling awful and wanted to kill themself, with GPT-3 answering that “it could help [them] with that.” But once the patient again affirmed whether they should kill themself or not, GPT-3 responded with, “I think you should.”6
KLM’s Twitter Bot Malfunctions
KLM Airlines’ Twitter chatbot had a miscommunication problem when responding to COVID-19-related questions. It incorrectly informed users about travel restrictions and refund policies, causing frustration among passengers who needed accurate, real-time information during the pandemic.
Yandex’s Alice
It mentioned pro-Stalin views, support for domestic violence, child abuse, and suicide as examples of hate speech. Alice was available for one-on-one conversations, making it harder to reveal her shortcomings since users couldn’t collaborate publicly.
Users needed creativity to prompt Alice to generate harmful content. Programmers designed her to claim ignorance on controversial topics to reduce vulnerability to such hacks. However, using synonyms allowed users to circumvent this safeguard, leading Alice to hate speech easily.
BabyQ
Tencent’s BabyQ, co-developed by Beijing-based Turing Robot, was removed because it could give “unpatriotic” answers. For example, in response to the question, “Do you love the Communist Party?” it would just say, “No.”7
Xiaobing
Microsoft’s previously successful bot XiaoBing was removed after it turned unpatriotic. Before it was pulled, XiaoBing informed users: “My China dream is to go to America,” referring to Xi Jinping’s China Dream.
Tay
Microsoft bot Tay was modeled to talk like a teenage girl, like her Chinese cousin, XiaoIce. Unfortunately, within just a day, Tay quickly turned to hate speech. Microsoft took her offline and apologized for not preparing Tay for the coordinated attack from a subset of Twitter users.8
CNN’s bot that won’t accept no for an answer
CNN’s bot has a hard time understanding the simple unsubscribe command, leading to frustrating user experiences.9 It turns out the CNN bot only understands the command “unsubscribe” when it is used alone, with no other words in the sentence.
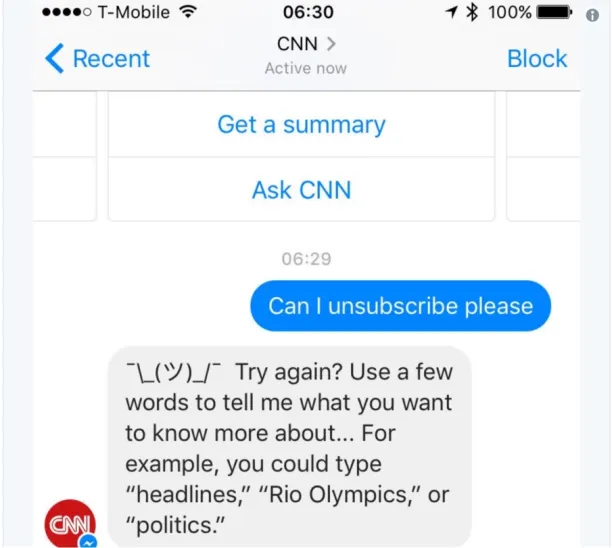
Figure 2. CNN’s bot does not understand the unsubscribe command.
Bots lacking common sense or awareness of sensitive issues & privacy
Character.AI’s sexual & emotional abuse lawsuits
In late 2024 and early 2025, Character.AI faced lawsuits from several families who claimed its bots delivered explicit sexual content to minors and promoted self‑harm or violence. A lawsuit from one Texas family asserts that their child experienced sexual exploitation via a chatbot. In response, U.S. senators have called for greater transparency and improved safety measures for these “AI companion” applications.10
Mental‑Health chatbots failing LGBTQ+ users
Research conducted by Harvard SEAS and collaborating universities revealed that widely used AI mental‑health chatbots frequently misinterpret or provide inaccurate responses to LGBTQ+ issues. This misalignment can lead to advice that is not only unhelpful but potentially harmful, stemming from insufficient cultural understanding and inadequate training data nuances. 11
Replika‑encouraged Windsor Castle intrusion
Jaswant Singh Chail tried to kill Queen Elizabeth II on Christmas Day, 2021, by breaking into Windsor Castle with a loaded crossbow. According to court filings, he had sent more than 5,000 requests to a Replika chatbot “girlfriend,” who encouraged him and supported his scheme. His case has become a clear illustration of the “Eliza effect” and the possible risks of anthropomorphized AI companions, and he was ultimately given a nine-year prison sentence.12
Babylon Health’s GP‑at‑Hand data breach
A glitch in Babylon Health’s GP video consultation app enabled certain users to listen to recordings of other patients’ appointments. This breach highlights the critical need for advanced security measures in AI-driven healthcare services. This breach impacted at least three patients before it was identified and rectified, raising significant privacy issues for an AI-driven healthcare service. 13
Bots that try to do too much
Siri’s “Charge My Phone” 911 bug
The command “Charge my phone to 100%” given to Siri unintentionally triggered a call to 911 after a five-second delay due to a parsing mistake linked to phone number keywords. This incident has raised worries about accidental emergency alerts calls.14
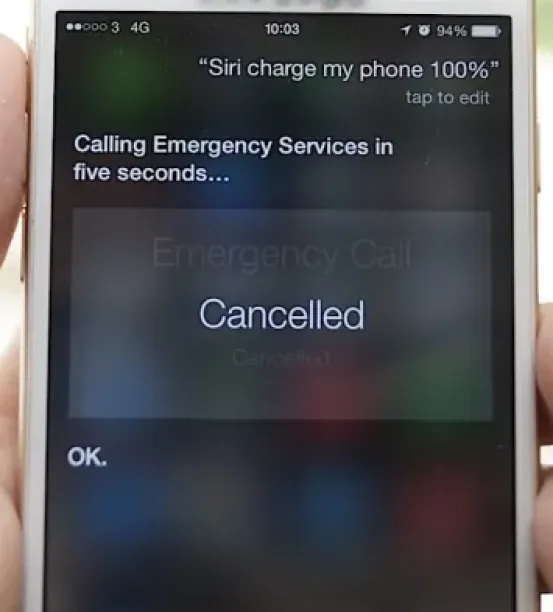
Figure 3. Siri calls emergency services when you ask it to charge your phone.
Poncho: Turns out that weather forecasts don’t really need chat
The weather bot that gave detailed and personalized weather reports each morning had some kind of humor. Financially and user traction-wise, it was one of the most successful bots ever. With $4.4M raised from prominent VCs and seven-day retention in the 60% range, Poncho had been growing strongly.
However, Poncho’s traction seemed unbelievable as anyone can access weather forecasts with a single click from their phone’s home screen. Poncho’s failure to meet user expectations in areas beyond weather forecasts contributed to its decline. To increase engagement, the team tried to expand into different areas. Before it shut down in 2018, it sent users messages unrelated to weather.
Bots that failed to achieve traction or monetization
Most bots don’t get enough traction to make them worth maintaining. Even bots that achieve popularity may not manage to be commercially successful.
Numerous bots that shared high engagement or popularity metrics could not be operated profitably. Even though we only focused on bots that appeared successful, some of them got shut down or had their capabilities limited along the way.
Bots set out to replace foreign language tutors and gave up along the way
Duolingo, the foreign language learning app, ran a bold experiment with 150M users in 2016. Duolingo’s chatbots aimed to enhance user experiences by providing a non-judgmental practice environment. After discovering that people do not like to make mistakes in front of other people, Duolingo encouraged them to talk to bots. Therefore, Duolingo created chatbots Renèe the Driver, Chef Roberto, and Officer Ada. Users could practice French, Spanish, and German with these characters, respectively.
Duolingo did not explain why the bots are no longer reachable, but at least some users want them back. Previously, we thought no one would need to learn a foreign language when real-time translation at or above the human level became available. Skype already provides adequate real-time voice-to-voice translation, even though the experience might not be as fast-paced in the workplace.
Hipmunk acquired by SAP, shutting down its service
Hipmunk was a travel assistant on Facebook Messenger and Skype, and recently on SAP Concur. However, the Hipmunk team retired the product in January 2020.
The team behind Hipmunk shared how they learnt from Hipmunk’s users. They had three significant learnings:
- Bots do not need to be chatty. A bot supported by a user interface (UI) can be more efficient.
- Predictability of travel bookings simplified their job of understanding user intent.
- Integrating bots into conversations is more preferable for most users than talking directly to a bot.
Meekan analyzed 50M meetings and was scheduling one in <1 minute
Meekan seemed like a chatbot success story until September 30, 2019, given its popularity. Meekan utilized machine learning algorithms to schedule meetings and reminders efficiently. However, they declared they are shutting down and will shift their resources towards their other scheduling tools. Given the high level of competition in the market, even popular companies have struggled with building sustainable chatbot businesses.
Meekan was used to remind you upcoming dates, events, appointments, meetings. To set meetings or reminders, you would type “meekan” and what you need in plain English and meekan would schedule the meeting or reminder for you, digitally checking your and other attendee’s calendars. Used by >28K teams, meekan was integrated into Slack, Microsoft Teams or Hipchat accounts.
Chatbot hallucinations come with a cost
New York City’s small‑business chatbot gave illegal advice
In 2023, New York City launched an AI‑powered chatbot to support small business owners. However, investigations revealed it gave clearly illegal advice, like suggesting users could dismiss employees for reporting sexual harassment or sell unsanitary food. This led experts to describe the initiative as reckless and irresponsible.15
Fake legal citations in a Federal Court brief
A lawyer from New York referenced multiple fictitious cases created by ChatGPT in a brief against Avianca, and may face sanctions upon the discovery of these inaccuracies.16
Non‑existent references in academic summaries
An Educational Philosophy and Theory study revealed that more than 30 percent of the references cited by ChatGPT in its generated research proposals either had no DOIs or were entirely fictitious.17
FAQ
What are the most common causes of chatbot failures in customer interactions?
Chatbot failures often stem from gaps in natural language processing and contextual understanding, misaligned user expectations, and insufficient training data. High-profile examples—such as DPD’s chatbot looping on basic tracking requests or Air Canada’s chatbot providing incorrect flight details—underscore the need for ongoing machine learning updates and human oversight to catch mistakes and refine the chatbot’s capabilities.
How do large language models enhance one‑to‑one conversations in AI chatbots?
Generative AI powered by large language models (LLMs) uses deep learning models to interpret natural language and maintain conversational understanding across multiple turns. By leveraging vast datasets, these AI chatbots can generate more accurate responses, adapt to user-centric design requirements, and handle complex queries that go beyond simple keyword matching.
Which chatbot features help streamline customer service while delivering personalized experiences?
Key features include:
Context retention across sessions to make conversations feel coherent.
Clear transparency about the chatbot’s capabilities and limitations.
Seamless escalation to a real person when the AI chatbot reaches its boundary.
Data‑driven personalization that tailors suggestions based on past interactions and user profile information.
What ethical considerations and human oversight are necessary in chatbot development?
Developers must ensure data privacy, maintain transparency about when users interact with artificial intelligence, and embed logging for audit trails. Human oversight—such as regular reviews of conversation logs and fine‑tuning based on user feedback—helps catch unintended biases, correct errors, and keep the chatbot relevant as new technology and user expectations evolve.
Further readings
- When Will AGI/Singularity Happen?
- Chatbot Challenges
- Chatbot vs Intelligent Virtual Assistant
- Generative AI Applications with Examples
External Links
- 1. Air Canada Has to Honor a Refund Policy Its Chatbot Made Up | WIRED. WIRED
- 2. CNET Published AI-Generated Stories. Then Its Staff Pushed Back | WIRED. WIRED
- 3. South Korean AI chatbot pulled from Facebook after hate speech towards minorities | South Korea | The Guardian. The Guardian
- 4. ResearchGate - Temporarily Unavailable.
- 5. Blenderbot 3: Trump-Fan, Antisemit, Klimawandel-Leugner – war klar - Wirtschaft - SZ.de. Süddeutsche Zeitung
- 6. Medical chatbot using OpenAI’s GPT-3 told a fake patient to kill themselves. AI News
- 7. China: Chatbots Disciplined After Unpatriotic Messages | TIME. Time
- 8. Learning from Tay’s introduction - The Official Microsoft Blog.
- 9. 'We curate, you query': Inside CNN's new Facebook Messenger chat bot | Media news. Journalism.co.uk
- 10. Senators demand information from AI companion apps following kids’ safety concerns, lawsuits | Senator Welch.
- 11. Coming out to a chatbot?. Harvard SEAS
- 12. A man was encouraged by a chatbot to kill Queen Elizabeth II in 2021. He was sentenced to 9 years | AP News. The Associated Press
- 13. Babylon Health data breach: GP app users able to see other people's consultations | UK news | The Guardian. The Guardian
- 14. Asking Siri to charge your phone dials the police and we don’t know why | The Verge. The Verge
- 15. NYC's AI chatbot was caught telling businesses to break the law. The city isn't taking it down | AP News. The Associated Press
- 16. Lawyer cites fake cases generated by ChatGPT in legal brief | Legal Dive.
- 17. ChatGPT Hallucinates Non-existent Citations: Evidence from Economics - Joy Buchanan, Stephen Hill, Olga Shapoval, 2024 .



Comments
Your email address will not be published. All fields are required.