We’ve categorized AI web scraping tools into the three main groups based on their technical complexity and intended audience. Click each category to jump to the relevant section:
- AI-powered platforms: Focused on using AI for structured extraction.
- No-code tools: Visual interfaces for scraping data without writing any code, with limited AI usage.
- Open-source AI tools: Ideal for developers who prefer full control over their scraping.
Here’s the table of top AI web scraping tools:
| Vendor | For | |
|---|---|---|
1. |  Bright Data Bright Data |
Enterprise-grade large-scale scraping |
2. |  Oxylabs Oxylabs |
Adaptive scraping and parsing capabilities |
3. |  Diffbot Diffbot |
AI-based structured data extraction via Knowledge Graph |
4. |  Firecrawl Firecrawl |
Headless AI-powered scraping with adaptive DOM parsing |
5. |  ScrapeGraphAI ScrapeGraphAI |
Prompt-driven data extraction using schema-based HTML parsing |
6. |  Kadoa Kadoa |
Beginner-friendly structured scraping |
7. | AI-powered open-source scraping agents | |
8. | LLM-powered HTML-to-JSON extraction via schema-guided prompts | |
9. |  LangChain LangChain |
Building LLM-based data workflows |
10. |  Octoparse Octoparse |
Non-coders who want quick extraction |
11. |  ParseHub ParseHub |
No-code visual scraper that supports AJAX |
12. |  Browse AI Browse AI |
Trainable no-code bots with AI-powered data monitoring and extraction |
13. |  Clay Clay |
AI-enhanced scraping integrated into sales automation |
14. |  Import.io Import.io |
Enterprise-scale data extraction |
15. |  Bardeen Bardeen |
Browser-based workflow automation with scraping capabilities |
Best AI web scraping tools
| Tool | Type | Key Features | Pricing/Plan Type |
|---|---|---|---|
| Bright Data | AI-powered platform | AI scraping APIs, anti-bot, and large-scale data extraction | Paid (enterprise plans) |
| Oxylabs | AI-powered platform | Adaptive scraping and parsing capabilities | Paid (enterprise plans) |
| Diffbot | AI-powered platform | Computer vision, NLP, Knowledge Graph | Paid (API-based) |
| Firecrawl | AI-powered platform | Dynamic content scraping, JS rendering | Free & Paid |
| ScrapeGraphAI | AI-powered platform | Natural language-driven scraping | Free (open-source) |
| Kadoa | No-Code | Structured data extraction, beginner-friendly | Free trial & Paid |
| Scrapeghost | Open-Source AI tool | Schema-based scraping, GPT-powered, CLI support, OpenAI API integration | Free (Open Source) + OpenAI API cost |
| Crawl4AI | Open-Source AI tool | Python library, heuristic scraping | Free (open-source) |
| LangChain | AI-powered platform | LLM integration, custom workflows | Free & Paid |
| Octoparse | No-Code | Point-and-click interface, desktop tool | Free trial & Paid |
| ParseHub | No-Code | Visual interface, handles dynamic sites | Free & Paid |
| Browse AI | No-Code | Prebuilt robots, point-and-click UI | Free plan available |
| Clay | AI-powered platform | AI scraping, sales data enrichment | Paid (with integrations) |
| Import.io | AI-powered platform | Data extraction, integration, transformation | Paid (custom plans) |
| Bardeen | AI-powered platform | AI workflows, browser automation | Free & Paid plans |
How we made this list
We intentionally excluded general-purpose data scraping tools and automation libraries that lack built-in AI capabilities (such as Scrapy or Playwright), even if they’re commonly used in web scraping and may complement AI tools in hybrid workflows.
We curated this list using the following criteria:
- Focus on AI-powered capabilities: We only included tools that use artificial intelligence, like LLMs or NLP, to understand page structure without hardcoded rules, and prompt-driven data extraction.
- Accessibility for users: We categorized tools based on technical level, such as no-code vs. developer tools.
What is AI web scraping?
AI web scraping is the process of using artificial intelligence algorithms with traditional web scraping processes to automate and refine data extraction activities. AI-powered web scraping tools are especially beneficial when you:
- Intend to scrape data from dynamic websites (design and structural changes)
- Need to categorize or analyze the scraped data
- Extract data from websites employing anti-bot measures.
AI web scraping tool types
1. AI-powered platforms
These solutions use LLMs, computer vision, or NLP for parsing, extracting, or interpreting content from web pages. For instance, Diffbot’s adaptive scraping dynamically adapts to DOM changes or inconsistent markup across pages. Many tools in this category support schema (structured format) or prompt-based extraction.
You give the tool a natural language instruction, for example, “Extract all job titles and company names from this URL”
2. No-code tools
No-code scrapers provide visual interfaces, enabling users to define the data to capture using point-and-click functionality or prebuilt templates. You can define data extraction rules visually.
However, these tools offer limited AI usage compared to AI-powered platforms, which utilize AI for pattern detection or intelligent field suggestions.
3. Open-source AI tools
This category includes libraries or frameworks that use LLMs or AI agents to extract data from web pages. They provide programmatic control; you need to define extraction schemas or AI prompts.
Techniques and technologies involved in AI-powered web scraping
AI-powered web scraping approach automatically adapts to website redesigns and extracts data loaded dynamically via JavaScript. It is important to employ these methods with consideration for the website’s terms and ethical considerations.
1. Adaptive scraping
Traditional web scraping methods rely on the specific structure or layout of a web page. When websites update their designs and structures, traditional scrapers can easily break. AI-based data collection methods, such as adaptive scraping, allow web scraping tools to adjust themselves to changes that are implied by websites, such as designs and structures.
Adaptive scrapers use machine learning and AI to adjust themselves dynamically based on the web page’s structure. They autonomously identify the structure of the target web page by analyzing the document object model (DOM) or by following specific patterns. In order to identify certain patterns or anticipate changes, the tool can be trained using scraped historical data.
For instance, AI models like convolutional neural networks (CNNs) can be used to recognize and analyze visual elements of a web page such as buttons. Typically, traditional data scraping techniques rely on the underlying code of a web page, such as HTML elements, to extract data.
Adaptive scraping examines the rendered version of the target website as it appears in a web browser. Visual elements such as buttons, banners or pop-ups disrupt the data extraction process.
A CNN can be trained with different visual representations of the pagination buttons to locate and interact with these buttons on a web page.
Sponsored
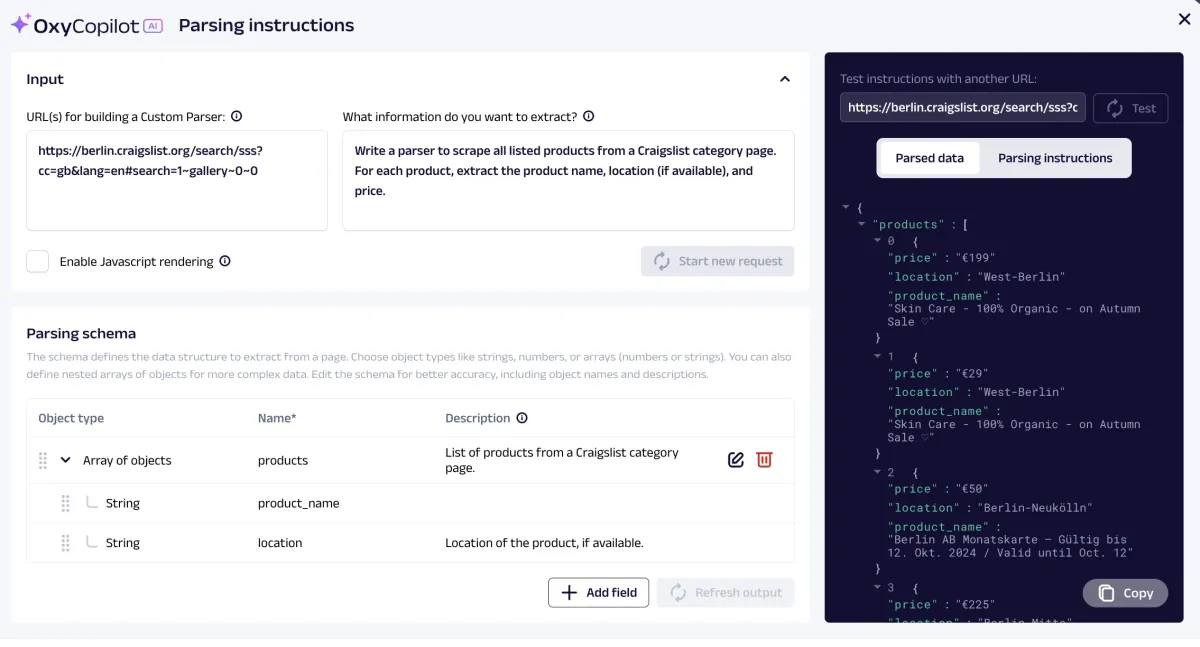
Oxylabs provides an ML-based custom parser builder, called OxyCopilot, that enhances Oxylab’s Web Scraper API, allowing users to refine and organize the data they collect using prompts. This streamlines the process by eliminating the need to sort through irrelevant data fields or perform manual data cleaning.
2. Generating human-like browsing patterns
Most websites employ anti-scraping measures, like CAPTCHAs, to prevent web scrapers from accessing and scraping their content. AI-powered web scraping tools can simulate human-like behavior like speed, mouse movements, and click patterns.
3. Generative AI models
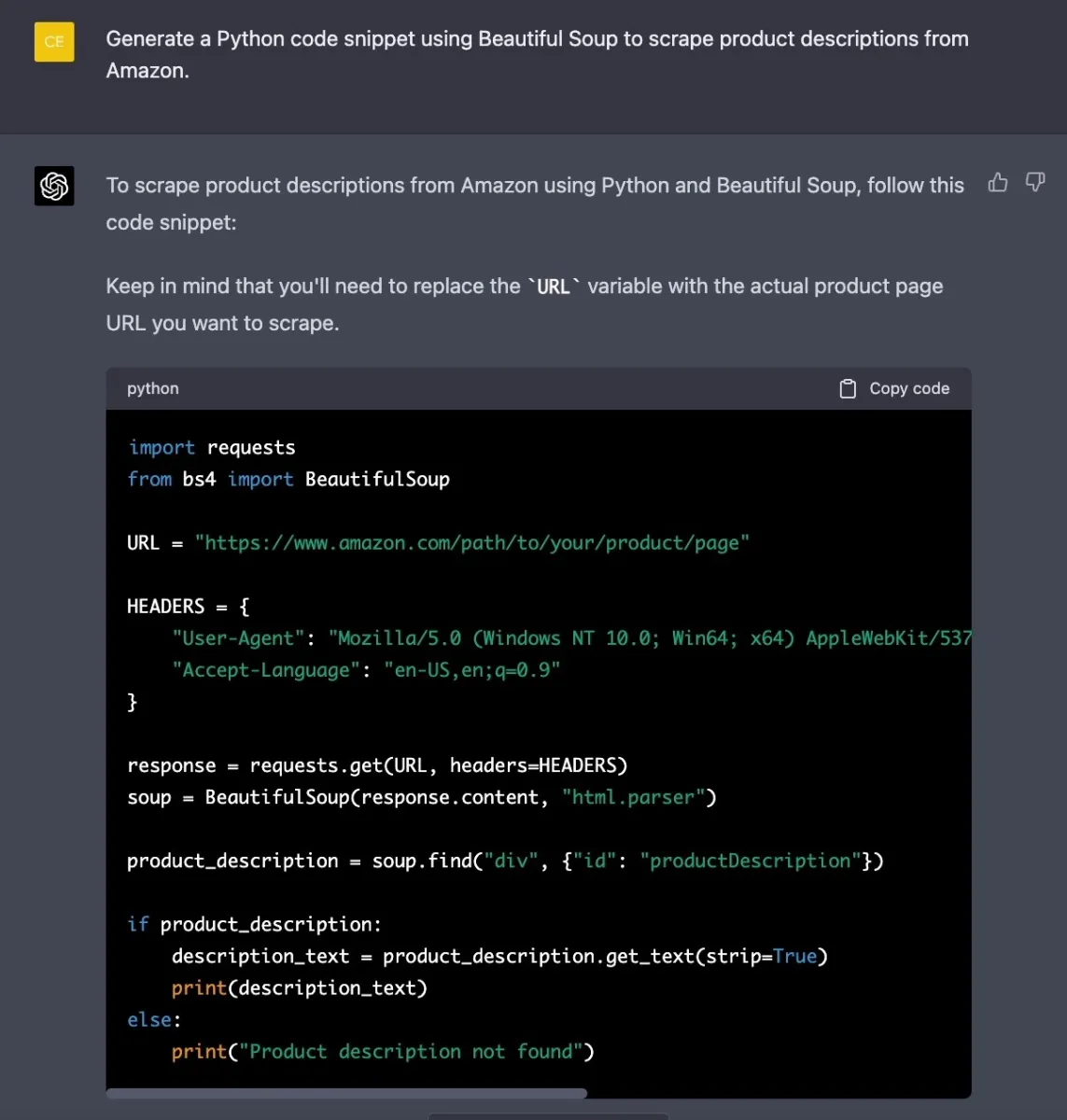
Generative AI can be applied in different stages of the data collection process to enhance its adaptability. Pre-trained language models, such as ChatGPT, can assist developers in generating code for extracting data from websites and provide step-by-step instructions for web scraping in various programming languages.
Once you have scraped the desired web data, ChatGPT can be fine-tuned on the scraped data to generate more conversational content.
4. Natural language processing (NLP)
NLP, a subset of ML, enables you to conduct various tasks, including sentiment analysis, content summarization, and entity recognition. It is necessary to derive insights from the scraped data.
For instance, if you have extracted a significant amount of product review data, you need to determine the emotional tone behind each word, such as positive, negative, or neutral. Sentiment analysis enables you to categorize the extracted data as either positive or negative. This helps businesses to address customer concerns and improve their offerings.


Comments
Your email address will not be published. All fields are required.