Invoice processing is a critical yet labor-intensive business operation that traditionally requires manual data extraction and entry into accounting systems. This manual approach is time-consuming and susceptible to human error. To evaluate automated alternatives, we conducted a comparative analysis of leading document processing solutions and LLMs:
- Amazon Textract API
- Claude Sonnet 3.5
- Docsumo
- Google Document AI
- Microsoft Azure Document Intelligence
- Rossum
Our study assessed these tools’ capabilities in accurately extracting data from diverse invoice formats and qualities, aiming to quantify their effectiveness as alternatives to manual processing.
Benchmark results
We evaluated invoice processing performance across invoices of varying quality and contrast levels. While all tools demonstrated strong performance with high-quality images, their accuracy declined significantly when processing lower-quality documents. Among the tools tested, Claude Sonnet 3.5 exhibited the highest overall accuracy and resilience across the full spectrum of document qualities.
Methodology
Measurement: Our evaluation methodology focused on the accuracy of key-value pair extraction. Each extracted field was assessed using a binary classification: correct extraction or incorrect/missing extraction. The accuracy metric was computed using the following formula:
Accuracy = (Number of Correctly Extracted Key-Value Pairs) / (Total Number of Key-Value Pairs)
This methodology enabled objective comparison of extraction performance across different tools and document types.
Sample size: Finding invoice data is challenging since it involves personal information like emails and names. We used more than 400 key value pairs from 20 publicly available invoice samples.
Samples: While all solutions correctly processed high quality images, extraction quality declined in images like these:

Fine-tuning: Although the products we tried were successful in finding total amounts, they had issues in extracting pricing details. It is possible to get better results by fine-tuning some products. In a few products, users can click on a value in the image to correct model output.
To be fair to all providers, we did not perform any fine-tuning. With fine-tuning, all providers should be able to achieve higher success rates in the second time they process these documents. However, our focus in this benchmark is autonomous operations which requires models to produce correct, reliable results based on documents that they previously did not see.
Timeline: All tests were completed in December 2024.
Next steps
Increasing participants: Since this study provides insights into current invoice processing capabilities across Large Language Models (LLMs), OCR technologies, and specialized invoice processing tools, we plan to expand our analysis by incorporating additional state-of-the-art LLMs to provide a more comprehensive benchmark of automated invoice processing solutions.
Increasing sample size and diversity.
What is invoice OCR?
Invoice parsing uses automated tools such as NLP, NLU, OCR, and other data extraction technologies to automatically extract data from invoices in various formats, such as PDFs, images, etc.
An invoice parser is a software program that extracts information such as
Vendor name
Invoice number
Amount due
and inputs it in a machine-readable format. This data can be utilized for multiple functions, such as automating accounts payable, completing month-end accounting closures, and managing invoices.
The parser software is usually integrated into an invoice processing system, which automates the entire process from the receipt of an invoice to payment.
How do invoice OCR tools work?
Documents written in a certain markup language are read and handled by parsers. They break the document up into smaller pieces, called tokens, and then look at each token to figure out what it means and where it fits in the structure of the whole document.
To do this, parsers need to know a lot about the grammar of the markup language in question. This gives them the ability to recognize each token and figure out the exact connections between them.
The process includes 5 steps:
1. Input
Invoices can be received in a variety of formats, including paper, email, or electronic formats such as PDF or XML. The invoice parser software will typically accept these invoices as input.
2. Optical Character Recognition (OCR)
If the invoice is in a scanned paper or image format, the parser will use OCR technology to extract text from the image. This allows the parser to access the data contained within the invoice.
Some invoice parser solutions use AI-powered OCR technology that can automatically extract information from PDFs, photos, and scanned data without the need for new rules or templates. This is because the AI can handle semi-structured and unfamiliar documents and improve over time. The extracted information can be customized to only include specific tables or data entries.
3. Data extraction
The parser will then extract specific information from the invoice, such as the vendor name, invoice number, date, and item details. This is typically achieved using a combination of pattern recognition and machine learning algorithms.
Some invoice parsing software has the capability to extract key information such as the invoice date, number, tax identification numbers, and various totals by using predefined filters:
Some parser tools offer the ability to extract line item information from invoices with a consistent format by creating a separate document parser for each specific vendor or trading partner layout:
4. Data validation
Once the data has been extracted, the parser will validate the information to ensure that it is accurate and complete. This can include checking that the date is in the correct format, that the vendor name matches a predefined list of vendors, or that the item details match the expected format.
5. Data output
The extracted and validated data is then outputted in a format that can be easily imported into the user’s accounting or ERP system. This can be in the form of a CSV file, database record, or directly into an accounting software.
Challenges with manual invoice data extraction
Manually extracting data from invoices and entering it into a system can be challenging for companies as there are several complexities:
Human error
Invoices can contain a large amount of data, and manual entry increases the risk of errors, such as typos, transposition of numbers, and incorrect data entry. Inaccuracies in data entry are responsible for an estimated $600 billion in yearly losses.1 Processes like accounts payable need correct data export from financial documents.
Time-consuming
On average, it takes 17 days, or approximately 75% of a month, to manually process a single invoice.2
Many different pieces of important information are included in invoices, and they are all presented in a key-value style where an individual identification serves as both the key and the value. The process of manually extracting these pairs is time-consuming and involves many inspections to assure accuracy. Even some OCR algorithms struggle to detect extracted values without context. Automated invoice processing can help employees focus on more complex tasks.
Lack of standardization
Invoices from different suppliers may have different formats. Each invoice is generated with a unique format that can pose difficulties when processing and interpreting these patterns. The documents, such as emails, paper, and PDFs, may go through a lot of digital and paper records before being approved for payment, making manual extraction of data challenging and prone to error.
Process inefficiency
The manual handling of invoices, which incurs an average cost of almost $23 per invoice3 , can be both time-consuming and expensive, leading to an inefficient and repetitive process.
Data loss potential
There is a risk of losing data if invoices are lost or damaged or if data is not entered correctly into the system.
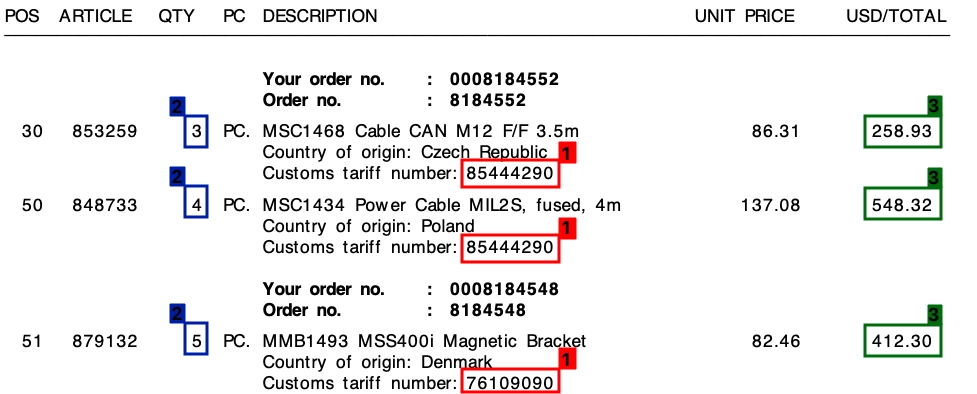
OCR software often face difficulties in extracting line items from invoices as well. This is because transaction tables may lack horizontal or vertical lines, making it difficult for ocr invoice processing to establish context for the extracted items. Collected digital invoice or invoice images can be used in this process.
How to choose your invoice processing vendor?
1. Supplies a solution in line with your company’s data privacy policies.
Your company’s data privacy policy can be a show-stopper to using external APIs such as Amazon AWS Textract. Most providers offer on-premise solutions so data privacy policies would not necessarily stop your company from using an invoice capture solution. The accounts payable workflow must be treated with careful consideration as it frequently involves confidential business and financial information.
2. Provide a consistent data structure regardless of the text on the documents.
There are two ways that deep learning based invoice capture companies work. Companies like Textract return key value pairs. So for example, if an invoice calls the total amount as “Gross amount”, the other calls it “Total amount” and another German invoice calls it “Summe”, Textract gives you the data in 3 different structures for these 3 documents.
In one, you have a key value pair with the key “Gross amount”, in another “Total amount” and in the German one, you get “Summe”. Other providers designed consistent data structures that work for all invoices. In all 3 scenarios, you would get “Total amount” which the key they use in their output file. This makes analytics and processing easier as you don’t need to deal with many different structured data formats.
3. Ask for the false positive and manual data extraction rates
Then run a Proof of Concept (PoC) project to see the actual rates on the invoices received by your company.
False positives are invoices that are auto-processed but have errors in data extraction. These are difficult to identify and can disrupt operations. For example, incorrect extraction of payment amounts would be problematic. Minimizing this should be the absolute focus.
Manual data extraction is necessary when automated data extraction system has limited confidence in its result. This could be due to a different invoice format, poor image quality or a misprint by the supplier. This is also important to minimize but there’s a trade-off between false positives and manual data extraction. Having more manual data extraction can be preferable to having false positives.
This is the first quantitative benchmarking we have seen in this space and will follow a similar methodology to prepare our own benchmarking.
4. Leverage a PoC to measure the potential automation rate
This depends on the number of fields you expect to capture from the documents. A typical set of ~10 fields including items like purchase order ID, vendor name, vendor name etc. can enable data entry into ERP and payments.
Best practice vendors achieve ~80% STP by extracting all of these ~10 fields with almost no errors ~80% of the time. Though there may be errors from time to time, manually checking the largest payments can ensure that no significant wrong payment slips through the net.
5. Ask for advanced processing options provided by the vendor
Extraction is the first step in data collection, it needs to be followed by data processing in most cases. For example, invoices need to be checked for VAT compliance (e.g. domestic invoices without VAT need to explain why VAT is excluded) and failure to do so could result in significant fines for the company depending on the country.
6. Ask for how the solution learns about new invoices
Best solutions have an interface for allowing your team to help guide the solution. As your company’s employee picks the key-value pairs, the invoice capture solution takes note so it can be more confident about a similar invoice next time.
7. Evaluate the ease-of-use of their manual data entry solution
It will be used by your company’s back-office personnel as they manually process invoices that can not be automatically processed with confidence.
Beyond this, best practice procurement questions make sense. For example:
- How widely adopted is their solution? Do they have Fortune 500 customers?
- Are their customers happy with their solution and support? Could be good to ask an acquaintance from a company that is already using their solution. Since invoice automation is not a solution that would improve marketing or sales of a company, even competitors could share with one another their view of invoice automation solutions.
- What are the options to integrate the solution to your company’s systems (e.g. ERP)? Is IT on-board with the integration approach?
- What is their Total Cost of Ownership (TCO)? Different solutions use different units of pricing (e.g. price per page or price per document) which makes this comparison difficult. However, using a sample from your archives, you could have an estimate of the cost.


Comments
Your email address will not be published. All fields are required.