Playwright vs Puppeteer: Scraping & Automation
Playwright and Puppeteer are the most powerful open-source tools for controlling headless browsers. The main difference between these tools lies in cross-browser support and feature richness.
Playwright supports multiple browser engines, whereas Puppeteer is primarily focused on Chromium-based browsers and offers a more straightforward experience.
How to build a price scraper with Playwright and an LLM
Instead of relying solely on Playwright for web scraping, we integrated an agent system powered by a large language model (LLM) via OpenRouter. This setup enabled us to send the HTML and visual content of a webpage to the LLM, which then intelligently interpreted the necessary action, such as identifying and clicking the correct button.
The target Amazon page includes elements like:
- Product title
- Price
- Add to cart button
- Related products
Step 1: Setting up your environment
We will:
- Import all the necessary libraries
- Configure logging
- And set up a connection to an LLM (via OpenRouter).
1.1 Import required libraries
We need to import the right libraries, configure logging, and connect to an LLM provider.
- requests: Needed to upload files to the web.
- base64: Converts HTML and images into safe text formats to send to the LLM.
- OpenAI as OpenRouter: We’re using OpenRouter (a proxy for OpenAI-like models) under the hood.
- playwright.sync_api: This provides a synchronous interface for controlling a browser using Playwright.
1.2 Set up Logging
This sets up logging so we can monitor what the script is doing.
1.3 Connect to your LLM provider (OpenRouter)
Step 2: Configure the language model and browser connection
We will,
- Set up a browser connection via a WebSocket endpoint
- Define timeouts and retry logic
2.1 Set your language models
Both models are accessed through OpenRouter.
2.2 Connect to a remote browser
We routed the traffic through proxies.
2.3 Set timeout values and retry logic
2.5 Helper: Ask the LLM for page selectors
This sends a prompt, along with optional HTML and a screenshot, to the large language model (LLM).
Step 3: LangChain agent and prompt setup
3.1 Define the agent’s system prompt
This prompt helps the LLM determine what to do, such as finding the price.
3.2 Define a tool
3.3 Create the agent
This combines your model with your prompt and tool(s).
3.4 Prepare the agent executor
Step 4: Playwright browser automation logic
4.1 Connect to Playwright and a remote browser
The following code will launch Playwright in synchronous mode. We have connected it to Bright Data’s Scraping Browser, a proxy browser.
4.2 Capture page context (HTML + screenshot)
These lines will get the full HTML of the current page.
This screenshot was taken programmatically by the agent:
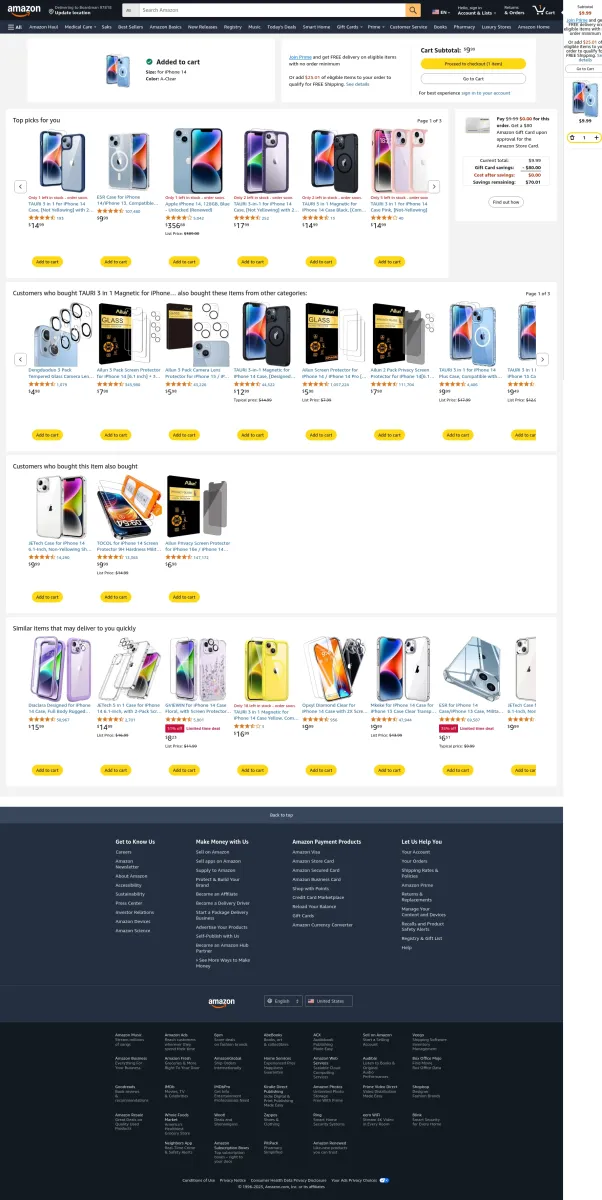
Steps 5 & 6: Running the Agent with Browser and LLM
In this final section, we will:
- Set up a loop that controls the flow of automation.
- Provide the agent with natural language instructions and parsed user intent.
5.1 Parse the user’s search intent
5.2 Construct the initial prompt
5.3 Loop through agent steps
5.4 Chat history for context
5.5 Error handling & retry logic
Main differences between Playwright and Puppeteer
Playwright and Puppeteer are both open-source Node.js libraries commonly used for web automation tasks and web scraping. Both tools support controlling headless browsers, automation via DevTools, and provide APIs for interacting with pages and elements.
Explore the key differences and similarities between Playwright and Puppeteer:
What is Puppeteer?
Puppeteer is an open-source Node.js library that provides a user-friendly API to control headless Chrome or Chromium browsers over the DevTools Protocol or WebDriver BiDi.
Puppeteer allows automation testing of Chrome Extensions for performance testing. Users can capture precise screenshots of entire pages or specific UI components.
Advantages of Puppeteer
- Since Puppeteer is developed and maintained by Google, the tool quickly integrates the latest Chrome developments.
- Cross-browser support is limited. Runs Chrome/Chromium in headless mode by default.
- Offers full control over Chrome’s features, including clicking buttons, form submission, scrolling, and taking screenshots.
- For Chrome-only tasks, Puppeteer is slightly faster than Playwright.
Disadvantages of Puppeteer
- Puppeteer does not support other browsers, such as Safari or Microsoft Edge.
- The primary language Puppeteer supports is JavaScript (and TypeScript via typings).
- Puppeteer is tightly coupled with specific versions of Chromium or Firefox. If you want to test on older browser versions, you need to manage the browser binary manually.
What is Playwright?
Playwright is an open-source, cross-browser automation and testing library developed by Microsoft. The tool enables developers to interact with all major browsers like Chromium (Chrome, Edge), Firefox, and WebKit (Safari).
Playwright allows capturing screenshots of entire pages or specific elements, generating PDFs of pages, and recording videos of test sessions.
Advantages of Playwright
- Cross-browser and cross-language support: Playwright is compatible with multiple browsers and supports various programming languages, including Python, .NET, JavaScript, and TypeScript.
- Built-in cross-browser testing: Developers can use the same scripts and tests across all supported browsers, both in visible (headed) and headless modes.
- Native mobile app testing of Chrome for Android and Mobile Safari: Includes predefined device profiles for common mobile devices.
- Built-in auto-wait: Auto-wait mechanisms ensure that elements become actionable before interactions occur.
Disadvantages of Playwright
- PDF Generation Limitation: Only supported on headless Chromium. Firefox and WebKit do not currently support PDF generation.
- Resource-intensive: Launching multiple browsers can consume memory and CPU resources.
- Less mature ecosystem relative to Puppeteer (offering extensive community support): While Playwright has quickly grown in popularity (initially released in early 2020), the tool still requires more community engagement.
Combining Scraping and Automation in One Puppeteer Script
In this example, we will:
- Navigate across different blogs
- Extract article titles, URLs, publish dates, and tags.
Step 1: Create a folder for your project
Then navigate to the folder
Step 2: Initialize a New Node.js Project
This will hold your project’s dependencies:
After creating a package.json file, install Puppeteer in the folder by running:
Step 3: Create the Scraping Script
- Create a new JavaScript file for the scraping script:
- Open the file:
- Paste the following code, then save and exit (CTRL + O → Enter, CTRL + X):
The script will extract:
- Article titles, URLs, publish dates, and tags.
Step 3: Run the Script
Expected output:
Troubleshooting
In the below image
- The Extracted Job Listings: [] means the script didn’t find any job listings on the page.
- No element found for selector: #text-input-what indicates the form input for the job search couldn’t be found.
How to fix the issue:
- Job listings scraping issue: The selector used for extracting the job titles can be outdated or incorrect. You need to inspect the page and update the script with the correct selector.
Many social media platforms, job search engines like Indeed, and e-commerce sites like Amazon use anti-bot measures to prevent automated requests.
For example, in the image below, Amazon serves the dog page, indicating that they utilize bot detection and block your request. Puppeteer (particularly in headless mode or with default settings) launches the target website.

Be the first to comment
Your email address will not be published. All fields are required.