When scraping image data with Python library, the goal can go beyond just downloading the images. You may need to collect metadata and additional contextual information associated with the images on a webpage. This typically involves gathering details like the image’s alt text, dimensions, captions, file sizes, and other relevant image data.
In this guide, we’ll walk through the process of scraping images from a webpage using Python which can be extremely useful for SEO purposes.
How to Scrape Images from a Website With Python
1. Requirements & Installation
To effectively scrape images from websites using Python, you will need the following libraries:
- Requests: For downloading images from URLs.
- BeautifulSoup: For parsing HTML and extracting image elements.
- Selenium: For rendering dynamic content on JavaScript-heavy websites.
- PIL (Python Imaging Library): For saving and processing images.
- Pandas: For storing scraped URLs into a structured format (CSV).
To install all the required dependencies, run the following command in your terminal or command prompt:
pip install requests beautifulsoup4 selenium pandas pillowStep-by-Step Guide to Image Scraping with Python & Selenium
Step 1: Setting Up the Web Scraping Environment
To handle JavaScript-heavy pages (e.g., with lazy loading or AJAX), Selenium is used to fully render the page. Below are the essential imports:
import hashlib, io, requests, pandas as pd
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from bs4 import BeautifulSoup
from pathlib import Path
from PIL import ImageStep 2: Fetching Page Content with Selenium
This function loads the page using a headless Chrome browser and returns the full HTML content after waiting for JavaScript to render:
def get_content_from_url(url):
options = ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(options=options)
driver.get(url)
driver.implicitly_wait(5) # Wait for JS content to load
page_content = driver.page_source
driver.quit()
return page_contentStep 3: Parsing Image URLs from HTML
Now, we will parse the page content and extract the image URLs. Many websites load images lazily (on scroll) or have images with non-standard attributes like data-src. We will handle these cases by checking multiple attributes (src, data-src, srcset).
def parse_image_urls(content, classes, location, primary_src="src"):
soup = BeautifulSoup(content, "html.parser")
results = []
for container in soup.find_all(attrs={"class": classes}):
tag = container.find(location)
if tag:
img_url = tag.get(primary_src) or tag.get("data-src") or tag.get("srcset")
if img_url and img_url not in results:
results.append(img_url)
return resultsStep 4: Saving Extracted URLs to CSV
Once image URLs are extracted, store them in a CSV file using pandas for later analysis: This makes it easier to analyze the images later (e.g., for checking filenames, alt tags, or file sizes).
def save_urls_to_csv(image_urls):
df = pd.DataFrame({"links": image_urls})
df.to_csv("links.csv", index=False, encoding="utf-8")
print(f"✅ Saved {len(image_urls)} image URLs to links.csv")Step 5: Downloading and Saving Images
You can download images and saves it using a SHA-1 hash-based filename to avoid duplicates:
def get_and_save_image_to_file(image_url, output_dir):
try:
image_content = requests.get(image_url).content
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert("RGB")
filename = hashlib.sha1(image_content).hexdigest()[:10] + ".png"
file_path = output_dir / filename
image.save(file_path, "PNG", quality=80)
print(f"📥 Saved: {filename}")
except Exception as e:
print(f"❌ Failed to download {image_url}: {e}")Tip: Understanding Unsplash HTML Structure
When scraping images from websites like Unsplash, it’s crucial to first understand the structure of the HTML and the specific containers where the images are stored. In the case of Unsplash, each image is nested within certain HTML elements (usually div tags), and understanding where the img tag is located within these elements is key to scraping the image URL.
Inspecting the Unsplash Webpage
- Right-click on an image on the Unsplash page and click Inspect or Inspect Element.
- You will see the HTML structure highlighted in the browser’s developer tools. Each image is inside a container element like a div, and typically, the image itself is nested within an img tag.

When targeting Unsplash:
<div class="gr86h">
<a href="...">
<img src="https://images.unsplash.com/photo-1234567890123.jpg" alt="Image description" />
</a>
</div>In this case:
- The div element with the class gr86h is the container for each image.
- Inside this div, there’s an <a> tag that wraps the image, which points to the full image or a link to the image page.
- The img tag inside the a tag contains the src attribute that holds the URL of the image.
Extracting the Image URL
To get the image URL, we can target the img tag inside the div with the class gr86h (or any other class that may be present in different Unsplash pages).
In your Python code, you would extract the image URL like this:
image_url = a.find("img").get("src")Key Div Class for Image Extraction
On Unsplash, the class name gr86h is used for the div containers around images. If you’re scraping images, you can use this class to target the div that contains each image.
Example for finding the images on Unsplash using BeautifulSoup:
def parse_image_urls(content, classes="gr86h", location="img", source="src"):
soup = BeautifulSoup(content, "html.parser")
results = []
for container in soup.find_all(attrs={"class": classes}):
img_tag = container.find(location)
if img_tag:
img_url = img_tag.get(source)
if img_url and img_url not in results:
results.append(img_url)
return resultsThis ensures you’re correctly targeting the img tag inside the div with the class gr86h, which holds the image URL.
By understanding the structure of the webpage and the HTML elements where images reside, you can efficiently scrape image URLs. For Unsplash, the image URLs are stored in the src attribute of the img tag, which is contained inside the div with the class gr86h.
Step 6: Running the Script
The main ( ) function pulls everything together and begins scraping from Unsplash:
def main():
url = "https://unsplash.com/s/photos/king-fisher"
content = get_content_from_url(url)
image_urls = parse_image_urls(
content=content,
classes="gr86h", # Inspect this may change!
location="img",
primary_src="src"
)
if not image_urls:
print("⚠️ No image URLs found. Try checking the class name or attributes.")
return
save_urls_to_csv(image_urls)
output_dir = Path("downloaded_images")
output_dir.mkdir(exist_ok=True)
for image_url in image_urls:
get_and_save_image_to_file(image_url, output_dir)Final Output

Final Python Script: Image Scraper for JavaScript-Heavy Websites (e.g., Unsplash)

# Import Required Libraries
import hashlib
import io
import requests
import pandas as pd
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from bs4 import BeautifulSoup
from pathlib import Path
from PIL import Image
# Step 1: Fetch HTML Content from URL Using Selenium
def get_content_from_url(url):
options = ChromeOptions()
options.add_argument("--headless=new") # Run browser in headless mode
driver = webdriver.Chrome(options=options)
driver.get(url)
driver.implicitly_wait(5) # Wait for JS to load
page_content = driver.page_source
driver.quit()
return page_content
# Step 2: Parse HTML Content and Extract Image URLs
def parse_image_urls(content, classes, location, primary_src="src"):
soup = BeautifulSoup(content, "html.parser")
results = []
for container in soup.find_all(attrs={"class": classes}):
tag = container.find(location)
if tag:
img_url = tag.get(primary_src) or tag.get("data-src") or tag.get("srcset")
if img_url and img_url not in results:
results.append(img_url)
return results
# Step 3: Save Extracted Image URLs to a CSV File
def save_urls_to_csv(image_urls):
df = pd.DataFrame({"links": image_urls})
df.to_csv("links.csv", index=False, encoding="utf-8")
print(f"Saved {len(image_urls)} image URLs to links.csv")
# Step 4: Download and Save Images to Disk
def get_and_save_image_to_file(image_url, output_dir):
try:
image_content = requests.get(image_url).content
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert("RGB")
filename = hashlib.sha1(image_content).hexdigest()[:10] + ".png"
file_path = output_dir / filename
image.save(file_path, "PNG", quality=80)
print(f"Saved: {filename}")
except Exception as e:
print(f"Failed to download {image_url}: {e}")
# Step 5: Main Function to Run the Workflow
def main():
url = "https://unsplash.com/s/photos/king-fisher"
content = get_content_from_url(url)
# Class name may change—use browser inspect tool to update if needed
image_urls = parse_image_urls(
content=content,
classes="gr86h", # Update this if Unsplash changes HTML structure
location="img",
primary_src="src"
)
if not image_urls:
print("No image URLs found. Try checking the class name or attributes.")
return
save_urls_to_csv(image_urls)
output_dir = Path("downloaded_images")
output_dir.mkdir(exist_ok=True)
for image_url in image_urls:
get_and_save_image_to_file(image_url, output_dir)
# Final Execution Block
if __name__ == "__main__":
main()
print("All done!")What is image scraping?
Image scraping is a technique used in web scraping to extract image data from web sources in various formats, including JPEG, PNG, and GIF. The term typically refers to automated processes implemented using Python web scraping libraries, such as Beautiful Soup, or through a no-code scraper.
Image scraper APIs for extracting images at scale
Image scraper APIs enable users to extract images from web pages programmatically via an API request. They often include built-in capabilities like JavaScript rendering, CAPTCHA avoidance, and proxy rotation.
Sponsored
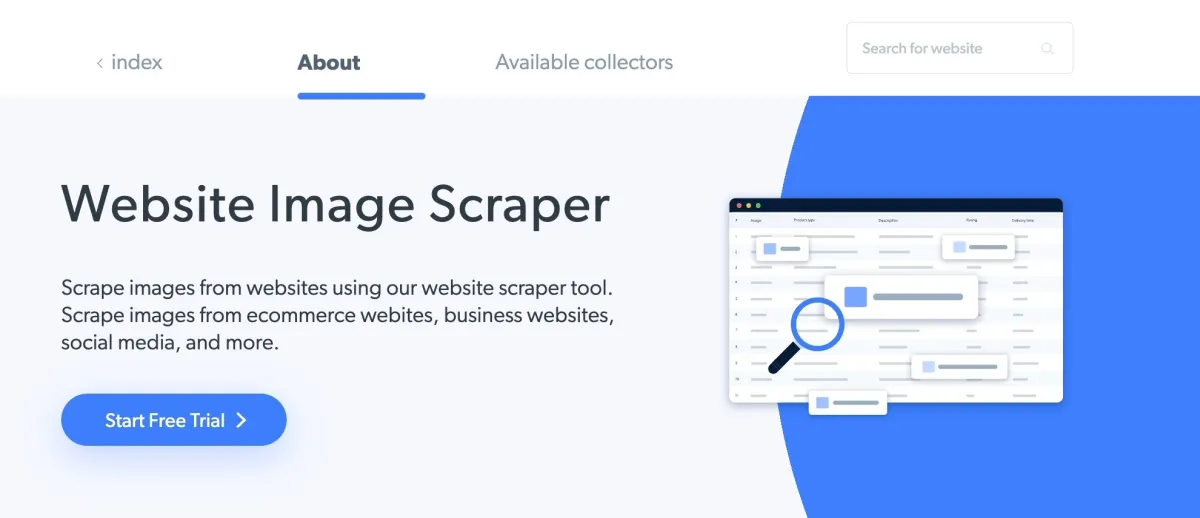
Bright Data’s Image Scraper is accessible to a wider range of users, including those with limited or no programming experience. The image scraping tool enables users to scrape data from any online source and track the rankings of images. It complies with all relevant data protection laws, including GDPR and CCPA.
Figure 2: Bright Data’s Image Scraper
Best practices for image scraping to avoid common challenges
It is essential to scrape image data cautiously and follow best practices in order to avoid technical and legal issues. Here are some best practices for image scraping:
- Check image formats and sizes: Images can come in various formats, such as JPEG, GIF, and sizes, such as small thumbnails. Ensure that your image scraper can handle all of these formats and different image sizes.
- Follow ethical and legal guidelines: Image scraping may be illegal under certain conditions, such as when it violates copyright laws. Check the terms of service and the Robots.txt file of the website you intend to scrape to ensure your data collection activity does not violate any rules or policies. For example, most websites employ rate limits to manage crawling traffic and prevent the overuse of APIs. Check for any rate limits imposed by the website’s API and comply with them to avoid being blocked.
- Respecting the website’s server and bandwidth: Limit the frequency and volume of your requests or add time delays between your requests. You can also use caching techniques to avoid requesting the same image data multiple times.


![Proxies for Web Scraping: Providers & Best Practices [2025]](https://research.aimultiple.com/wp-content/uploads/2021/04/proxy-scraping-1-190x143.png.webp)
Comments
Your email address will not be published. All fields are required.