Selecting the right metric to evaluate your machine learning classification model is crucial for business success. While accuracy, precision, recall, and AUC-ROC are common measurements, each reveals different aspects of model performance. We’ve analyzed these metrics to help you choose the most appropriate one for your specific use case, ensuring your models deliver real value.
Accuracy
Accuracy is a metric in machine learning that measures the overall correctness of a model’s predictions. It represents the ratio of correctly predicted instances (both true positives and true negatives) to the total number of instances in the dataset. Accuracy is calculated using the formula: Accuracy = (Number of correct predictions) / (Total number of predictions)

Let’s use an example where a model classifies 40 restaurant reviews as positive or negative. This is the ground truth with 40 different reviews.
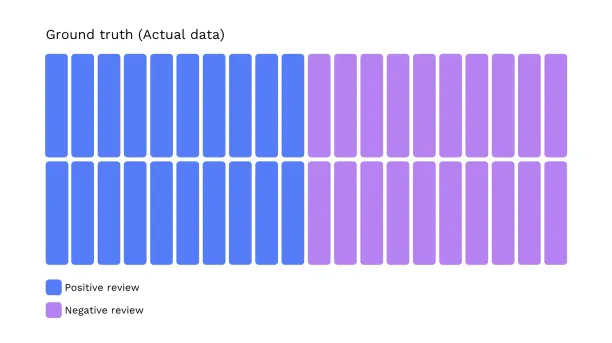
As seen in the image, the model classified some positive reviews as negative and some negative reviews as positive.
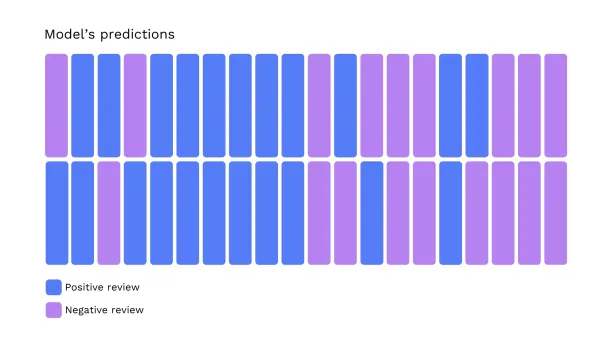
When we compare the model’s predictions with the actual data, we see that:
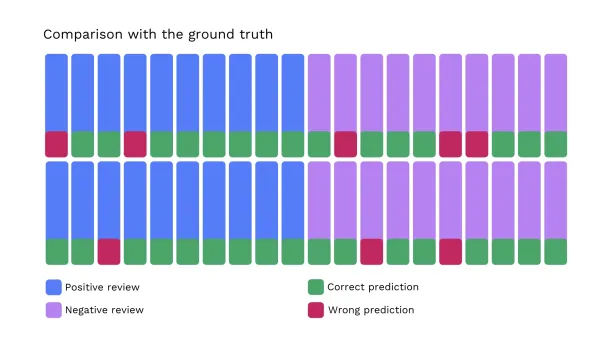
In that case, he model misclassified 8 reviews; therefore, its accuracy is 80%.
Confusion matrix
A confusion matrix visualizes the classification model’s performance by displaying the counts of true positives, false positives, true negatives, and false negatives.
Our confusion matrix shows:

Therefore, the 4 possible results of a model’s individual predictions are:
- True positive: The prediction is correct and the actual value is positive (i.e., this value is one of the values the model tried to identify. In our case, the model correctly predicted the positive reviews)
- False positive: The prediction is wrong and the actual value is positive
- True negative: The prediction is correct and the actual value is negative (i.e. this value is not one of the values that the model was trying to identify. In our case, the correctly identified negative reviews are true negatives.)
- False negative: The prediction is wrong and the actual value is negative
There are other metrics to evaluate a machine learning model’s performance comprehensively, like precision and recall.
Precision
Precision is the measure of how often a machine learning model correctly predicts the positive data. You can measure it with the formula:
Precision = True Positives / (True Positives + False Positives)
Recall
Recall is the proportion of actual positive cases that the model correctly identified. In simpler terms, it measures how well a model finds all the positive instances.
Recall = True Positives / (True Positives + False Negatives)
When to use precision and recall?
Precision:
- When false positives are costly or problematic
- When you want to be very confident in your positive predictions
- When resources for follow-up are limited
- When testing or alerting is expensive
Strengths:
- Reduces false alarms
- Builds trust in positive predictions
- Conserves resources
- Minimizes unnecessary actions
Weaknesses:
- Precision does not account for false negatives, meaning the model may miss many true positives.
- Not ideal when finding all positive cases is critical
- Can be artificially inflated by setting a high threshold for positive predictions, leading to fewer false positives but at the cost of recall.
- Doesn’t account for false negatives
Recall:
- When false negatives are dangerous or costly
- When finding all positive cases is critical
- In medical screening, security, and safety contexts
- When the cost of missing a positive is higher than the cost of a false alarm
Strengths:
- Ensures few or no positive cases are missed
- Prioritizes completeness over precision
- Critical for high-risk scenarios
- Better for imbalanced datasets with few positive cases
Weaknesses:
- May generate many false positives
- Can overwhelm follow-up systems
- May reduce overall confidence in alerts
- Can be artificially inflated by classifying everything as positive, leading to a high recall but very low precision.
Real-world examples
- Cancer screening: High recall prioritized (better to have false positives than miss cancer)
- Spam filtering: Balance needed (but usually precision-focused to avoid losing important emails)
- Fraud detection: Recall often prioritized for investigation, with human review for precision
- Product recommendations: Precision often prioritized (better to show fewer but more relevant items)
Accuracy paradox
In some cases, where positive and negative data are unequal, accuracy can be misleading. For example, let’s assume we have a review pool with 34 positive reviews and 6 negative reviews.
In the image, the model predicted that all the reviews are positive. When we compare it to the ground truth, we can see that the model’s accuracy is 80%. However, the model failed to detect any negative reviews, meaning its accuracy for negative reviews is 0%.”
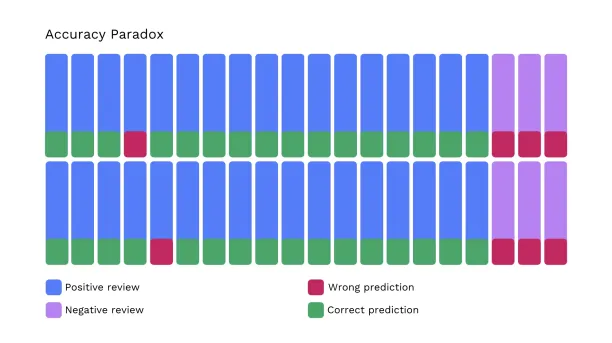
This situation is called the “Accuracy paradox.” Users should be aware that an accuracy metric might be misleading in the case of small groups in a dataset.
Sensitivity and specificity
Sensitivity is the true positive rate, and specificity is the true negative rate.
F1-score
F1-score is a metric that shows a model’s predictive performance. It is measured using precision and recall. The harmonic mean of precision and recall is used to calculate it. The F1-score ranges from 0 to 1, with 1 indicating the best balance of precision and recall.
Area under the ROC curve (AUC)
The ROC (Receiver Operating Characteristic) curve is a graphical plot that illustrates the diagnostic ability of a binary classifier as its discrimination threshold is varied. The Area Under the ROC Curve (AUC-ROC) provides a single scalar value to evaluate the overall performance of a model.
AUC-ROC measures the entire two-dimensional area underneath the ROC curve, which plots the True Positive Rate (TPR/Recall) against the False Positive Rate (FPR) at various threshold settings.
Interpretation:
- AUC = 1.0 Perfect classifier
- AUC = 0.5 Not better than random guessing
- AUC < 0.5 Worse than random guessing
Strengths
- Threshold-invariant: Evaluates model performance across all possible classification thresholds.
- Scale-invariant: Not affected by changes in the scale of predictions.
- Class-imbalance robust: Performs well even with imbalanced datasets.
- Provides a single metric to compare multiple models.
Weaknesses:
- It may give misleading results when the cost of different error types varies significantly.
- Does not provide information about specific threshold performance.
- Poor performance may be hidden in certain regions of the curve.
- Less intuitive for non-technical stakeholders than recall and precision.
When to use:
- Comparing multiple models
- Threshold-independent evaluation of model performance
- Working with imbalanced datasets
- General assessment of discriminate ability
Confidence levels
The confidence levels provided by the model complicate this situation. Almost all machine learning models can be built to provide a level of confidence for their predictions. A high-level approach to using this value in accuracy measurement is multiplying confidence levels with the results. This:
- Reward the model for providing high confidence values for its correct assessments
- Penalizes the model for high-confidence mistakes
There are more sophisticated approaches that consider how the model is used. A typical challenge is taking into account human-in-the-loop cost.
For example, suppose all low-confidence predictions will be manually reviewed.
In that case, assigning a manual labor cost to low-confidence predictions and taking their results out of the model accuracy measurement is a more accurate approximation for the business value generated from the model.
What are the possible results of a data science / ML model?
A model’s individual predictions can either be true or false, meaning the model is right or wrong. The actual value of the data point is also important. You may wonder why we need a model that makes predictions if we know the actual values.
Here, we are referring to the model’s performance on the training data, data where we know the answers. The actual value of the data points can be the values we are trying to identify in the dataset (positives) or other values (negatives).
How to assign business values to outcomes?
All of the 4 outcomes listed above have different business values. Let’s continue with the analogy of the model that is trying to identify customers who are potential buyers. The potential business values of these variables are:
- True positive: The contribution margin (i.e., the value of the sale after all variable costs). Thanks to the model, we identified the right customer and made the sale; therefore, all the incremental value of the sale should be attributed to the model.
- False positive: Negative of the contribution margin. This could have been a sale but the model misclassified it so the sale did not happen. Because of the model, we are not able to close this sale.
- True negative: No value. No action was taken and no opportunity was missed, so these are neutral data points
- False negative: The marketing costs to reach the customer and the cost of annoyance caused to the customer as a result of reaching her with an offer she is not interested in. The latter cost is most of the time overlooked. However, it is important as by unnecessarily reaching customers, we cause some to unsubscribe or not pay attention to our messages, making future sales less likely.
How can business outcome value determine ML model value?
By cross-multiplying the number of results in each bucket by their respective values, we determine the model’s overall value.
How to refine business value estimation with confidence levels?
Like us, models can also assess their likelihood to be right. This value is almost as important as the results themselves. With confidence levels, your company can refine its human-in-the-loop mechanism or its business decisions based on the model output. The refinement due to confidence levels depends on whether that model is solving a problem where humans outperform the model:
- Consider introducing additional controls for low confidence cases in predictions where humans outperform the model at a reasonable cost. It may sound counter-intuitive to be using models in areas where humans are better. However, due to cost considerations, models perform tasks (such as optical character recognition or document data extraction) where humans are more capable. In these cases, using a confidence level as input to manual controls can help improve results. For example, if all of a model’s false predictions have low confidence, a manual check of low confidence outputs would enable your company to make perfect decisions.
- Consider discarding model predictions without introducing human-in-the-loop where the model’s confidence level is low if
- Humans can not outperform the model (i.e. in big data solution areas like recommendation personalization) or
- Human time cost is not worth the value a correct decision generates.
An example where a model’s low-confidence predictions are disregarded is identifying customers for targeted campaigns. The cost of sending a campaign message to a customer who may not buy the product is relatively low, while the value from a sale is high. Therefore, companies may want to send offers to customers even if the model predicts, with low confidence, that they will not buy the product.
FAQ
How can false positives and false negatives be eliminated to make more correct predictions?
Structuring the data and using reliable data sources may help to achieve a higher accuracy score. Model performance in machine learning refers to the accuracy of a model’s predictions or classifications when applied to new, previously unseen data.
In binary classification, the accuracy metric often measures model performance, which evaluates how well the model predicts both the positive and negative classes. Accuracy reflects the proportion of correct positive predictions and correctly identified instances of the negative class, providing insight into how effectively the model classifies new data.


Comments
Your email address will not be published. All fields are required.