What are 5 Best Process Mining Algorithms to Consider?
Process mining algorithms are examples of how machine learning process mining applications can facilitate process discovery. TThey help clean the required data and generate process models with different strengths and weaknesses. Technical professionals and developers must decide which algorithm to use based on the data and models of the processes they want to automate.
Since it is crucial for developers to select the best algorithm to employ in their process models, explore the most common process discovery algorithms:
Feature | Alpha Miner (A/A+) | Heuristics Miner | Fuzzy Miner | Inductive Miner | Genetic Miner |
|---|---|---|---|---|---|
Model Soundness | Discovered model might not be sound. | Does not guarantee a sound model. | Cannot be converted to other types of process modeling languages. | Model is sound. | Model can handle invisible and duplicated tasks, but is computationally expensive. |
Capabilities | Cannot handle loops of length one and length two / A+ can handle loops of length one and length two. Invisible and duplicated tasks cannot be discovered. | Takes frequency into account. Detects short loops. | Supports large numbers of activities and highly unstructured behavior. Uses significance/correlation metrics to simplify process model interactively. Can leave out less important activities (or hide them in clusters). Strong against noise. | Can handle invisible tasks. Model is sound. Most used process mining algorithm. | Mimics the process of evolution in biological systems. Use elitism, crossover, and mutation to build the population elements of the next generation. Tackles non-free-choice, invisible, and duplicate tasks. Computationally expensive. Robust to noise. |
Handling of Noise | Weak against noise. | - | Strong against noise. | - | Robust to noise. |
Inputs | Event log file. | Event log file. | Event log file. | Event log file. | Event log file. |
Outputs | Petri Net. | Heuristic Net. | Fuzzy Model. | Petri Net or Process Tree. | Petri Net or W-F Net. |
When to Use | Not recommended for real-life data (Obsolete). | When you have real-life data with not too many different events, or when you need a Petri net model for further analysis. | When you have complex and unstructured log data, or when you want to simplify the model interactively. | For discovering process delays, deviations, and animation of the model. | When all behavior in the log needs to be represented by the model. |
1. Alpha Miner
Alpha Miner is the first algorithm that bridges the gap between event logs or observed data and the discovery of a process model. Alpha Miner can build process models solely based on event logs by understanding relations and causalities between the steps of processes.
For example, today, several activities are executed in parallel rather than sequentially to minimize the execution time of the process. The alpha miner can be applied to detect parallel activity because it understands start and end events by using double timestamps.
As in the figure below, the alpha miner finds out the processes involved in completing A to C as separate traces, then restructures them together in a model by their relations.
To do these, alpha miner generates:
- A Petri net
The execution of the process starts from the events included in the initial marking and finishes at the events included in the final marking.
Some of the characteristics of the algorithm:
- It does not support classification: The algorithm does not recognize that one process is the same as another and logs them as independent events.
- It does not handle noise data well.Noise data is irrelevant or meaningless data that occurs due to data quality issues (e.g., data entry errors or incompleteness). Such data negatively affect the accuracy and simplicity of the process models.
2. Heuristic miner
Heuristics Miner is a noise-tolerant algorithm; therefore, it is applied to demonstrate the process behavior in noise data. The Heuristics miner only considers the order of the events within a case. For instance, it creates an event log table with the fields as case id, originator of the activity, time stamp, and activities considered during the mining. The timestamp of activity is used to calculate the ordering of events.
This technique includes three steps:
- The construction of the dependency graph
- The construction of the input and output expressions for each activity.
- The search for long-distance dependency relations.
Some of the characteristics of the algorithm:
- Takes frequency of events into account
- Can only describe events that are either exclusively dependent on each other (AND), or completely independent from one another (XOR)
3. Fuzzy miner
Fuzzy Miner is one of the youngest algorithms suitable for mining less structured processes. These processes exhibit a large amount of unstructured and conflicting behavior (e.g., it turns spaghetti-like models into more concise models.). The processes may be unstructured and conflicting because they might include information about:
- Activities related to locations in topology (e.g., towns or road crossings)
- Precedence relating to the traffic connections (e.g., railways or motorways).
Fuzzy miner applies a variety of techniques, such as removing unimportant edges, clustering highly correlated nodes in to a single node, and removing isolated node clusters. Fuzzy miner cannot be converted to other types of process modeling languages such as Business Process Mining Notations (BPMN) or Business Process Execution Language (BPEL).
4. Inductive Miner
Inductive Miner detects splits [1], which are the conditions or connecting steps between the first and the final stage of the process in the log. There are different types of splits in an event log:
- Sequential
- Parallel
- Concurrent
- Loop
Once an inductive miner identifies the splits, it recurs on sub-logs until it can find a base case. Inductive miner models give a unique label for each visible transition. These models use hidden transitions specifically for loop splits. a Petri net or process tree can be produced to map the process flow, based on the inductive miner algorithm.
5. Genetic miner
Genetic miner algorithm is derived from biology, specifically from natural selection. It helps deal with noise and incompleteness in process models. The way it operates is as follows:
- Reading event log
- Building initial representation that defines the search space of a genetic algorithm.
- Calculating fitness of each process in this initial representation, also referred as fitness measure. This step evaluates the quality of a process model point in the search space against an event log.
- Stopping and returning the fittest models
- Generating the next model by genetic operators ensures that all points in the search space are defined by the internal representation and can be reached by running the genetic algorithm.
To understand Genetic miner better you can check out the genetic algorithm courses:
How to choose the best algorithm for mining?
It should be compatible
These ML algorithms can be implemented in programming languages like R or Python . Depending on the data type and quality, they can be utilized in all sectors.
It should be interchangeable
In some cases, one database requires more than one miner algorithm because of its structure. There are also situations where several miner algorithms can be used interchangeably to construct similar models.
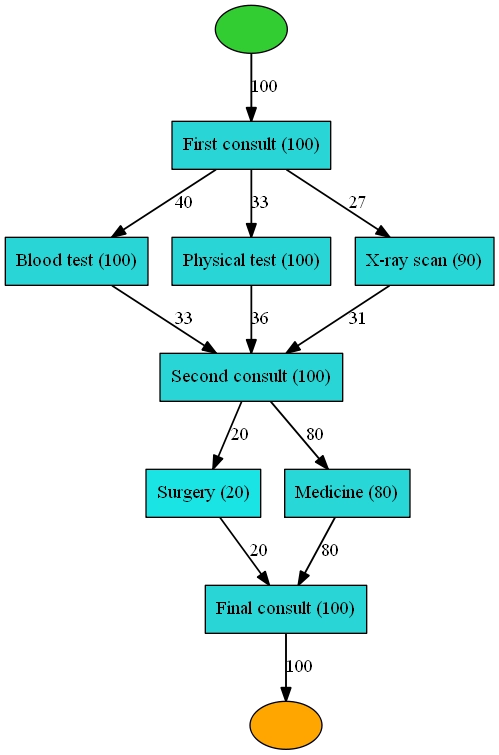
In these cases IT and analyst teams must compare them through the directly-follows graph (DFG) (see, Figure 7) of events and event transitions to evaluate the models and understand what they capture or omit. Another common practice is to run all the models and measure the fitness, precision, generalization, and simplicity of the models to decide the most applicable model.
Figure 8: Directly-follows Graph (DFG) Example in Healthcare
Further reading
To understand how process mining works, how it differs from automated process discovery, and process discovery tools, check out our in-depth articles:
If you believe your business will benefit from process mining software, feel free to scroll down our data-driven list of process mining software and tools.
Check out our comprehensive and constantly updated process mining case studies list to learn more.
Let us guide you in finding the right vendors:
Find the Right Vendors
Be the first to comment
Your email address will not be published. All fields are required.