Synthetic Data to Improve Deep Learning Models in 2024
Despite its success in a wide range of tasks, deep learning has an important limitation: its data-hungry nature. Collecting and labeling huge data with desired properties is costly, time-consuming, or unfeasible in some applications.
Synthetic data, also called artificially generated data, can help improve the performance of deep learning algorithms by meeting their data demands. Researchers believe that synthetic data is essential for further development of deep learning and will play an increasingly important role in the future. As shown in the image below, Gartner’s 2021 report on synthetic data agrees with this belief.
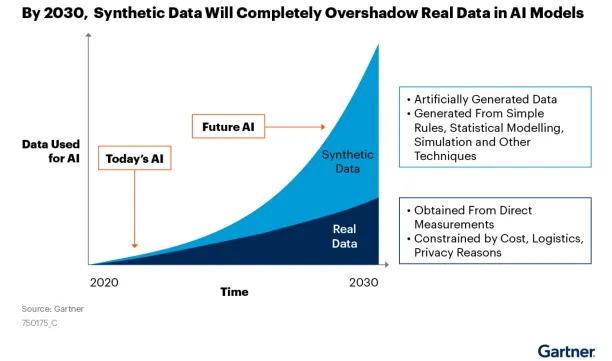
How can synthetic data help deep learning?
Increasing the size of datasets with high-quality artificial data can help deep learning algorithms with these issues:
- Data scarcity: Deep learning models rely on large amounts of high quality training data. However, the unavailability of model-relevant data limits the potentials of deep learning applications. By generating large datasets having similar statistical properties with the desired real data, synthetic data can significantly improve the performance and accuracy of deep learning models.
- Privacy: Privacy regulations are another factor limiting access to large datasets. It is not possible to rely on datasets that do not contain personally identifiable information for many deep learning applications. Simply removing personally identifiable information from such datasets is also problematic as data can be re-identified using modern machine learning approaches. Generating synthetic data from real datasets can contain all the important insights of the source data without risking anyone’s privacy.
- Data labeling effort: For supervised deep learning, labeling the training data is indispensable to the model building process. For example, before a deep learning model learns whether a picture contains a cat or not, it must be trained on a large dataset with correctly labeled pictures. It is a labor-intensive and tedious job. Synthetic data produced by generative models can already have accurate labels.
What are some synthetic data use cases in deep learning applications?
- Healthcare: Obtaining large-scale and labeled data in medical imaging is a challenge due to privacy regulations. A 2018 study shows that synthetic CT images improve the performance of a convolutional neural network (CNN) model to classify liver lesions from 78% total accuracy to 85%. Another remedy for this is federated learning which allows improving machine learning models without sharing training data. For more, check our article on synthetic data applications in healthcare.
- Finance: Within the transactions of a bank, fraudulent activity constitutes a small percentage. This imbalance between fraudulent and non-fraudulent activities of a bank’s transaction dataset poses a problem for deep learning models to detect fraud. Generating synthetic fraudulent activity to balance the dataset can significantly improve the performance of deep learning algorithms. For more, check our article on synthetic data applications in finance.
- Autonomous vehicles: A deep learning model for autonomous vehicles cannot be realistically trained on a dataset containing images or videos of all possible real-world conditions. Even if it was possible, it would be a daunting task to collect and label this type of dataset. Instead, autonomous vehicles are trained on simulations such as Google’s self-driving car. For more, feel free to read autonomous things (AuT) applications.
Synthetic data can be useful in any deep learning application with small data or privacy concerns. Check out our article on synthetic data use cases.

What are the challenges to use synthetic data in deep learning applications?
- The quality of synthesized data depends on the source data. If the source data is biased or has quality issues, the outcome of deep learning algorithms would reflect these issues.
- Although easier and cheap than collecting and labeling real data, it can also be challenging and costly to generate high-quality synthetic data in some applications.
- Synthetic data replicates specific statistical properties of the source data. So it can miss some random behavior of real-world data.
For more on synthetic data and its challenges, feel free to check our guide.
If you are ready to use synthetic data in your deep learning applications, you can use our prioritized, data driven list of synthetic data technology providers to choose a partner.
If you need synthetic data for your business, let us help you:

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
Synthetic Data vs Real Data: Benefits, Challenges in 2024
Synthetic Data for Computer Vision: Benefits & Examples in 2024
Test Data Management: What it is & Why it matters in 2024?
Related research
Top 20 Synthetic Data in 2024: 20 Use Cases & Applications

Comments
Your email address will not be published. All fields are required.