Challenges & Methods for Multilingual Sentiment Analysis in 2024
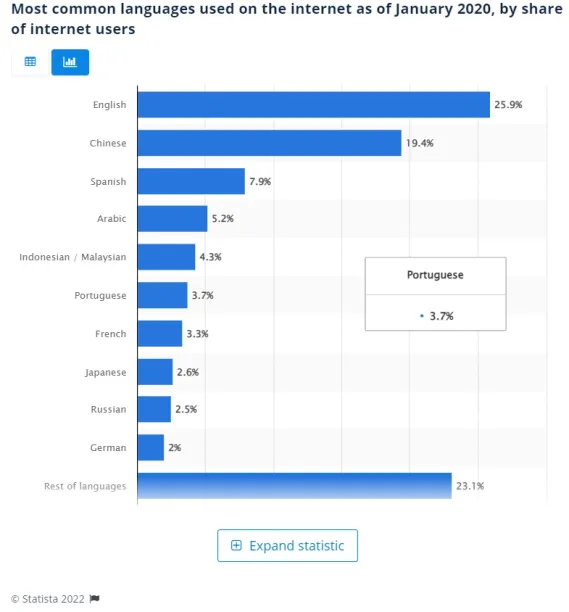
In our 2022 research about sentiment analysis, we explained how businesses increasingly invest in sentiment analysis and how it works. One of the challenges of sentiment analysis is multiple languages. As seen in Figure1, majority of the web data is in languages different from English. When it comes to applying sentiment analysis, despite more sources becoming available over time, majority of the sources are primarily available for English and it is challenging to apply sentiment analysis in different languages. In this research, we will introduce you the two main ways that sentiment analysis can be applied into non-English languages.
Why sentiment analysis is difficult in different languages?
1. Pre-processing with different encoding
Text pre-processing is an important step for any NLP application. For computers to process text, today’s industry standard is text to have the encoding style called Unicode . Languages that use non-Latin alphabets or old text data sources may have a different encoding style, such as KOI8 which used for Cyrillic alphabet. This makes human languages unreadable to many pre-processing coding languages and stops the NLP process at the very beginning.
2. Stop words and text classifiers
NLP packages get help from built-in word lists in order to remove words that do not have a significant meaning. For example, words like “the, a, an” need to be removed from an English text to limit the text to words that are meaningful for an NLP analysis. Stop words are available in different languages, but they still don’t expand to all languages and dialects in the world and need to be manually developed.
A second built-in list that is used for sentiment analysis is the text classifiers, which is basically labeling each word or group of words as positive, negative, or neutral. Our research about best open source tools for sentiment analysis listed the top packages that have such lists built-in for different languages, which may not be the case for all solutions available in the market.
3. Structural differences across languages
A fundamental step of sentiment analysis is tokenization, which is separating text into small meaningful units. These units are often words or group of words in order to detect meaning that is added by prefixes, such as the difference between “good” and “not good”. As laid out by a research group in Stanford University, this process should be different for many languages since the grammatical structure is different, such as number of words that convey a certain meaning or difference of suffixes and prefixes.
Two Main Methods for Multilingual Sentiment Analysis
Sentiment analysis can be applied on a text either by translating it to another language or directly on the original language. The former was a preferred method prior to development of more advanced NLP models, however recent research points out that there are more resources being developed for applying sentiment analysis for many different languages in the world. The challenges we mentioned above are still applicable, but the quality of the analysis results will likely improve over time in original languages.
1. Native Language Support
Today, many NLP packages support different languages, which enables possessing the unique meaning of a text in a different language. For example, one of the most popular NLP packages on Github, spaCy, supports more than 60 languages natively. One breakthrough that made it available was the development of BERT, which is a bi-directional NLP model developed by Google and actively used for analyzing Google search queries across many different languages.
2. Translation to English
A 2018 study by European Union showed that online data and corpora to build NLP solutions on are mostly in English, underrepresenting other languages. Following the same phenomena, established NLP tools were primarily available in English. Therefore, an early method developed for multilingual sentiment analysis, which is still used today, is translating the text into English and then applying pre-processing and analysis steps. The main caveat with this approach is, despite the progress in the accuracy of automated language translation, it is still not perfect especially between English and less frequently spoken languages. Therefore, this method is likely to cause a certain amount of meaning loss or distortion. Recent scientific research as well supports that sentiment analysis on translated languages is not as accurate as applying the analysis directly to the native language.
Further reading
- Best Web Scraping Programming Languages with Stats
- Web Scraping vs Data Mining: Why the Confusion?
- Top 3 Web Scraping Challenges Solved by AI
For guidance to choose the right tool, check out data-driven lists of web scrapers and sentiment analysis services and reach out to us:
This article was drafted by former AIMultiple industry analyst Bengüsu Özcan.

Cem has been the principal analyst at AIMultiple since 2017. AIMultiple informs hundreds of thousands of businesses (as per similarWeb) including 60% of Fortune 500 every month.
Cem's work has been cited by leading global publications including Business Insider, Forbes, Washington Post, global firms like Deloitte, HPE, NGOs like World Economic Forum and supranational organizations like European Commission. You can see more reputable companies and media that referenced AIMultiple.
Throughout his career, Cem served as a tech consultant, tech buyer and tech entrepreneur. He advised businesses on their enterprise software, automation, cloud, AI / ML and other technology related decisions at McKinsey & Company and Altman Solon for more than a decade. He also published a McKinsey report on digitalization.
He led technology strategy and procurement of a telco while reporting to the CEO. He has also led commercial growth of deep tech company Hypatos that reached a 7 digit annual recurring revenue and a 9 digit valuation from 0 within 2 years. Cem's work in Hypatos was covered by leading technology publications like TechCrunch and Business Insider.
Cem regularly speaks at international technology conferences. He graduated from Bogazici University as a computer engineer and holds an MBA from Columbia Business School.
To stay up-to-date on B2B tech & accelerate your enterprise:
Follow onNext to Read
Top 3 Reputation Management Best Practices in 2024
Top 4 Use Cases of Sentiment Analysis in Marketing in 2024
Top 4 Real-Life Examples of Sentiment Analysis in 2024
Related research

Comments
Your email address will not be published. All fields are required.